5-1基于无序链表实现集合、5-2基于无序链表实现映射
集合
什么是集合?
集合(Set)作为存储数据的容器时:
- 它是不允许存储相同元素的。只能保留一份。
- 能快速的帮助我们进行去重操作,过滤掉重复的元素
集合的应用
- 典型的应用:词汇量统计,统计一篇英文文章的总单词数
- 使用集合进行去重。看看不同的单词总数有多少个,判断英文文章的阅读难度。
集合的接口
ISet.cs
namespace DataStucture
{interface ISet<E>{int Count { get; }bool IsEmpty { get; }void Add(E e);void Remove(E e);bool Contains(E e);}
}TestHelper.cs
功能用途
-
核心功能:读取文本文件,将其内容拆分为独立的单词(简陋的分词),并返回单词列表。
-
典型应用场景:
-
文本分析(如词频统计)。
-
为数据结构(如哈希表、字典树)提供测试数据。
-
自然语言处理(NLP)的预处理步骤(但分词逻辑较简单,不处理词性、时态等复杂情况)。
-
using System;
using System.Collections.Generic;
using System.IO;
using System.Linq;
using System.Text;
using System.Threading.Tasks;namespace DataStucture
{/// <summary>/// 辅助测试类/// </summary>class TestHelper{//读取名为filename的文件,并将它分词,分词后存入list中并返回使用public static List<string> ReadFile(string filename){//使用StreamReader读取filename文件信息FileStream fs = new FileStream(filename, FileMode.Open);//使用StreamReader读取filename文件信息StreamReader sr = new StreamReader(fs);//将读取的单词存入动态数组words中List<string> words = new List<string>();// 分词操作,这是一个非常简陋的分词方式//只要单词拼写不一样,我们就认为是不同的单词。不考虑单词的词性和时态。while (!sr.EndOfStream) // 如果没有读取到filename末尾。就继续while读取{//读取一行字符串并去除字符串的头部和尾部的空白符号,存储在contents中string contents = sr.ReadLine().Trim();//寻找contents第一个字母的位置int start = FirstCharacterIndex(contents, 0);//开始分词逻辑,将一个个的单词存储在数组words中for (int i = start + 1; i <= contents.Length; i++){if (i == contents.Length || !Char.IsLetter(contents[i])){string word = contents.Substring(start, i - start).ToLower();words.Add(word);start = FirstCharacterIndex(contents, i);i = start + 1;}elsei++;}}// 关闭流对象释放资源fs.Close();sr.Close();return words;}//寻找字符串s中,从start的位置开始的第一个字母字符的位置private static int FirstCharacterIndex(string s, int start){for (int i = start; i < s.Length; i++){if (char.IsLetter(s[i])){return i;}}return s.Length;}}
}
Program.cs
using System;
using System.Collections;
using System.Collections.Generic;
using System.Diagnostics;
using System.Net.Http.Headers;namespace DataStucture
{class Program{static void Main(string[] args){Stopwatch t = new Stopwatch();Console.WriteLine("英文");List<string> words = TestHelper.ReadFile("测试文件1/英文.txt");Console.WriteLine("单词总数:" + words.Count);LinkedList1Set<string> set = new LinkedList1Set<string>();foreach (var word in words){set.Add(word);}Console.WriteLine("不同单词的总数:" + set.Count);Console.WriteLine("运行时间:" +t. ElapsedMilliseconds);Console.Read();}}
}
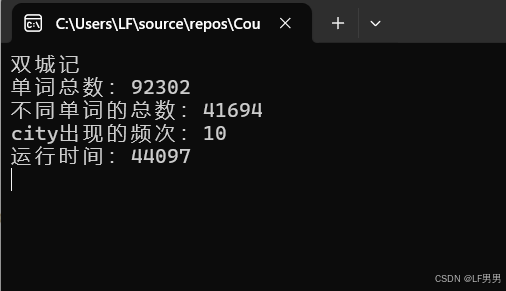
输出结果
结论:是一个顺序的查找方式、效率低下
映射
什么是映射?
映射:指两个元素之间相互“对应”的关系
映射的案例
在C#中使用字典(Dictionary)表示,存储键值对的数据
| 键 (Key) | 值 (Value) |
|---|---|
| 身份证号码 | 人 |
| 车牌号码 | 车 |
| 学生学号 | 学生 |
| 单词词频 | 单词 |
字典的接口
IDictionary.cs
namespace DataStucture
{interface IDictionary<Key,Value>{//数量int Count { get; }//是否为空bool IsEmpty { get; }//添加void Add(Key key,Value value);//删除void Remove(Key key);//查找 (查看字典中是否有这个键)void ContainKey(Key key);//传入一个键 获取 对应的值Value Get(Key key);//修改void Set(Key key, Value newvalue);}
}
LinkedList3.cs
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;namespace DataStucture
{class LinkedList3<Key,Value>{//创建节点类private class Node{public Key key; //键public Value value; //值public Node next; //下一个元素的指针//构造函数public Node(Key key,Value value,Node next){this.key = key;this.value = value;this.next = next;}//打印 方法public override string ToString(){return key.ToString() + ":" + value.ToString();}}private Node head; //标记头部引用private int N; //键值对数量//构造函数 链表的初始状态public LinkedList3(){head = null;N = 0;}public int Count { get { return N; } }public bool IsEmpty { get { return N == 0; } }//查找是否有该节点private Node GetNode(Key key){Node cur = head;while (cur!=null){if (cur.key.Equals(key)){return cur;}cur = cur.next;}return null;}//增public void Add(Key key,Value value){Node node = GetNode(key);if (node == null){head = new Node(key, value, head);N++;}else{node.value = value;}}//判断是否存在public bool Contains(Key key){return GetNode(key) != null;}//获取public Value Get(Key key){Node node = GetNode(key);if(node==null){throw new ArgumentException("键" + key + "不存在");}else{return node.value;}}//改public void Set(Key key,Value newvalue){Node node = GetNode(key);if (node == null){throw new ArgumentException("键" + key + "不存在");}else{node.value = newvalue;}}//删public void Remove(Key key){// 空链表直接返回if (head == null){return;}// 要删除的是头节点if (head.key.Equals(key)){head = head.next; // 头指针指向下一个节点N--;}// 要删除的是中间或尾部节点else{Node cur = head;Node pre = null;while (cur != null){if (cur.key.Equals(key)) // 找到目标节点{break;}pre = cur; // 记录前驱节点cur = cur.next; // 移动到下一个节点}// 确认找到目标节点if (cur != null) {pre.next = pre.next.next; // 跳过当前节点(删除)N--;}}}}
}
Program.cs
using Elasticsearch.Net.Specification.IndicesApi;
using System;
using System.Collections;
using System.Collections.Generic;
using System.Diagnostics;
using System.Net.Http.Headers;namespace DataStucture
{class Program{static void Main(string[] args){Console.WriteLine("双城记");List<string> words = TestHelper.ReadFile("测试文件1/双城记.txt");Console.WriteLine("单词总数:" + words.Count);Stopwatch t = new Stopwatch();LinkedList3Dictionary<string,int> dic = new LinkedList3Dictionary<string,int>();t.Start();foreach (var word in words){if (!dic.ContainsKey(word)){dic.Add(word,1);}else{dic.Set(word, dic.Get(word) + 1);}}t.Stop();Console.WriteLine("不同单词的总数:" + dic.Count);Console.WriteLine("city出现的频次:" +dic.Get("city"));Console.WriteLine("运行时间:" +t.ElapsedMilliseconds);Console.Read();}}
}
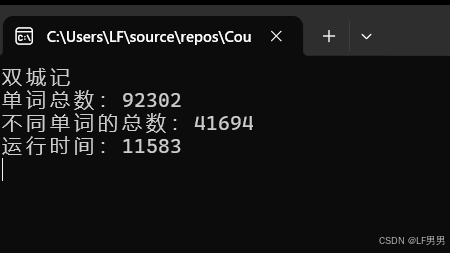
输出结果: