一、Spark 是什么
Spark 是一种基于内存的快速、通用、可扩展的大数据分析计算引擎,也可说是分布式内存迭代计算框架。
二、Spark 四大特点
速度快(内存计算)
易于使用
通用性强
运行方式多
三、与hadoop的核心差异
数据通信:Spark 基于内存,Hadoop 基于磁盘。
任务启动:Spark 用线程(快),Hadoop 用进程(慢)。
适用场景:Spark 适合迭代计算、交互式分析;Hadoop 适合大规模磁盘存储场景。
四、Spark 核心架构与部署模式
1. 运行架构
Master-Slave 模型:
Driver:负责任务调度、作业转换和状态跟踪(类似大脑)。
Executor:实际执行任务的工作节点,负责处理数据并缓存结果。
集群管理器:如 Standalone、YARN、Kubernetes,负责资源分配。
核心组件:DAG 调度器(拆分任务阶段)、任务调度器(分配任务到 Executor)。
2.部署模式
| 模式 | 特点 | 适用场景 |
| Local | 单节点运行,用于本地测试,无需集群环境 | 开发调试 |
| Standalone | Spark 自带集群管理器,实现资源自调度,支持 Master-Worker 架构 | 轻量级集群,学习 / 测试 |
| YARN | 集成 Hadoop YARN 资源管理器,适合与 Hadoop 生态结合 | 生产环境,大数据处理 |
| Kubernetes | 基于容器编排,弹性扩缩容,适合云原生部署 | 大规模分布式生产环境 |
五、Spark Core:分布式计算基础
1. RDD(弹性分布式数据集)
核心特性:
弹性:支持内存 / 磁盘存储切换、容错恢复、动态分区。
分布式:数据分片存储在集群节点,支持并行计算。
不可变:通过转换(Transformation)生成新 RDD,保留操作 lineage(血缘关系)。
关键操作:
转换(Transformation):map、filter、reduceByKey、join(惰性执行,不立即计算)。
行动(Action):collect、count、saveAsTextFile(触发实际计算)。
依赖关系:
窄依赖:父 RDD 分区仅被一个子分区使用(如 map)。
宽依赖:父 RDD 分区被多个子分区使用(如 reduceByKey),触发 Shuffle。
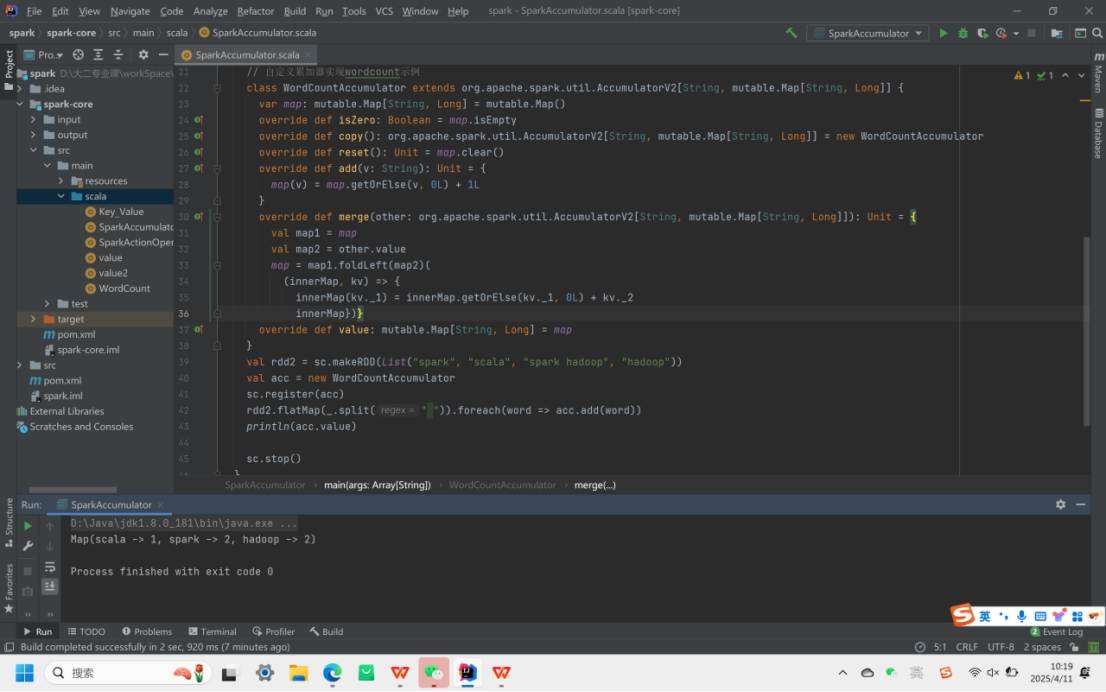
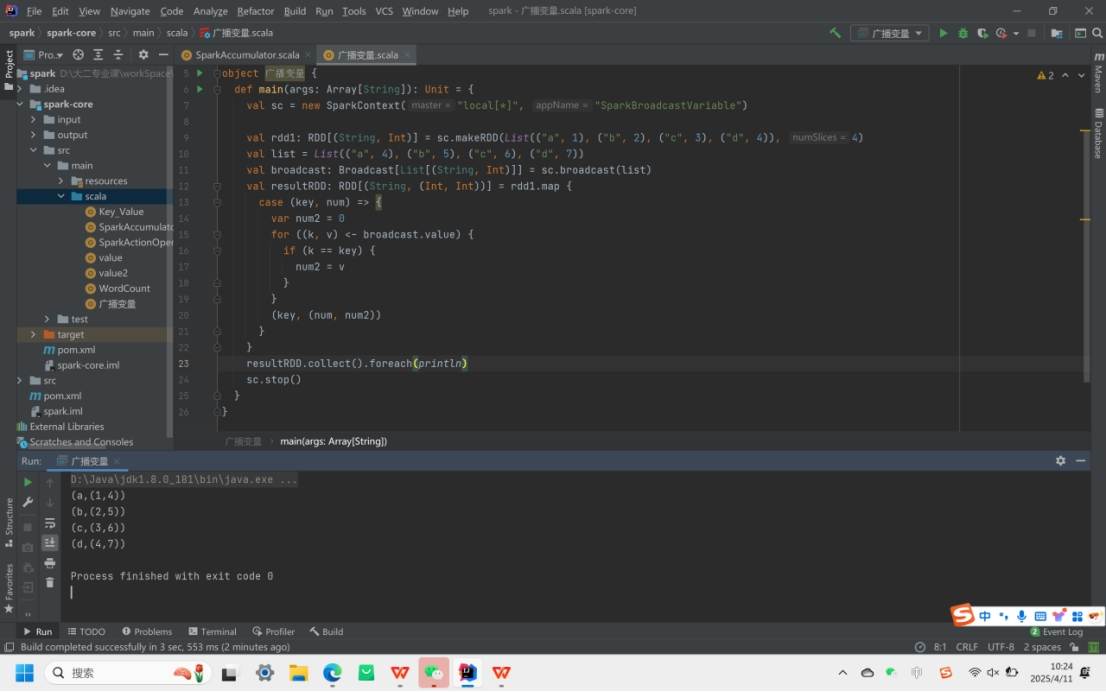
2. 累加器与广播变量
累加器(Accumulator):分布式环境下的全局计数器,用于统计任务结果(如全局计数)。
广播变量(Broadcast Variable):将只读变量广播到所有 Executor,避免重复传输(如字典数据)。
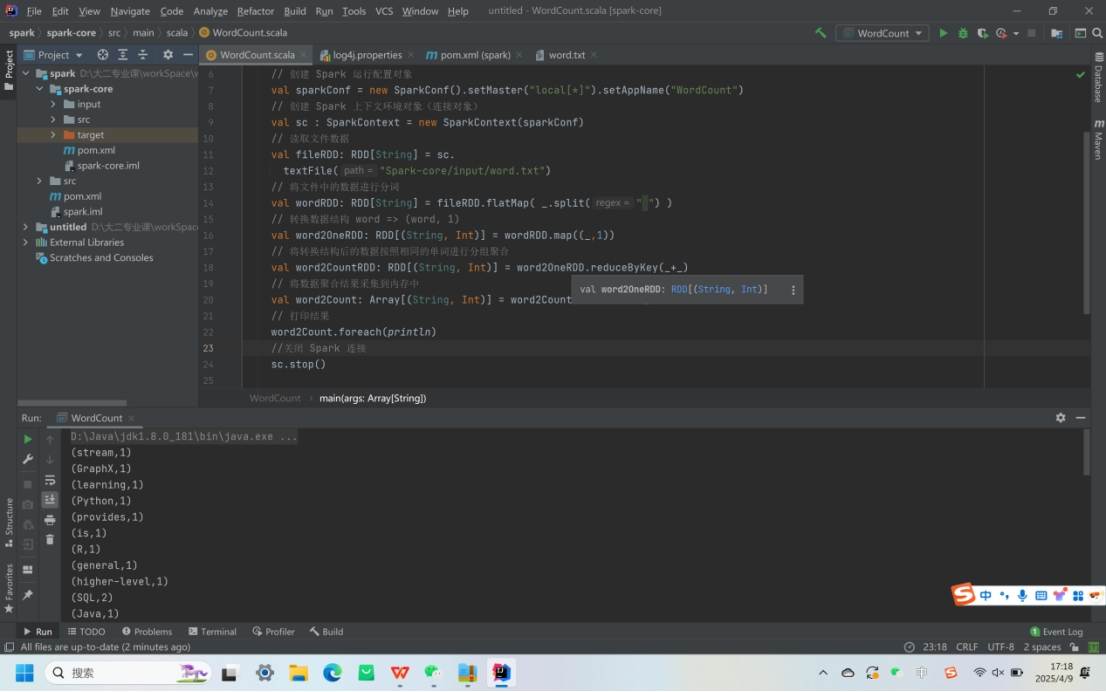
3.行动算子
reduce:聚集 RDD 所有元素,先聚合分区内数据,再聚合分区间数据。
collect:在驱动程序中以数组形式返回数据集所有元素。
foreach:分布式遍历 RDD 元素并调用指定函数。
count:返回 RDD 中元素个数。
first:返回 RDD 中第一个元素。
take:返回 RDD 前 n 个元素组成的数组。
takeOrdered:返回 RDD 排序后的前 n 个元素组成的数组。
aggregate:分区数据通过初始值和分区内数据聚合,再和初始值进行分区间聚合
fold:折叠操作,是 aggregate 的简化版
countByKey:统计每种 key 的个数。
save 相关算子:将数据保存到不同格式文件
六、Spark SQL:结构化数据处理
1. 核心抽象
DataFrame:带 Schema 的二维表结构,支持 SQL 查询和 DSL 操作,底层为 Dataset[Row]。
Dataset:强类型数据集,结合 RDD 的灵活性和 SQL 的优化能力(如 Dataset[User])。
三者关系:
plaintext
RDD ↔ DataFrame ↔ Dataset
(通过反射/编程方式转换,如 rdd.toDF()、df.as[User])
2. 数据操作
SQL 风格:注册临时表,使用 spark.sql("SELECT * FROM table") 执行查询。
DSL 风格:通过链式调用 df.filter($"age">18).groupBy("name").count() 实现逻辑。
数据源:支持 JSON、CSV、Parquet、JDBC(如 MySQL)、Hive 等,通用加载接口:
scala
spark.read.format("csv").option("header", "true").load("path")
七、Spark Streaming:实时流处理
1. 核心概念
DStream(离散化流):将实时流切割为多个时间片(如每秒一个批次),每个批次对应一个 RDD。
输入源:Kafka、Flume、TCP 套接字等,通过 socketTextStream 或 Kafka Direct API 读取数据。
DStream 本质是RDD 序列,每个时间区间数据对应一个 RDD。
2.特点:
易用性:支持 Java、Python、Scala 等语言,编程方式类似离线处理。
容错性:无需额外配置即可恢复丢失数据。
易整合性:可与 Spark 批处理结合,支持离线与实时处理统一代码。
3.关键操作
无状态转换:对每个批次独立处理(如实时 WordCount):
有状态转换:跨批次维护状态(如窗口聚合、updateStateByKey):
输出操作:将结果写入外部系统(如 MySQL、HDFS),通过 foreachRDD 实现。
八、Spark 生态与综合应用
1. 生态组件
MLlib:机器学习库,支持分类、回归、聚类等算法(如 LogisticRegression)。
GraphX:图计算框架,支持 Pregel 模型和图算法(如 PageRank)。
Structured Streaming:基于 DataFrame/Dataset 的流式处理,支持端到端 Exactly-Once 语义。
2. 典型应用场景
离线分析:使用 Spark Core/Spark SQL 处理批量数据(如日志分析、报表生成)。
实时分析:结合 Spark Streaming/Kafka 构建实时数据管道(如实时用户行为分析)。
机器学习:通过 MLlib 训练模型,结合 Spark SQL 处理特征数据。
图计算:利用 GraphX 分析社交网络、推荐系统中的关系数据。