1 为什么要进行案例研究?
过去,计算机视觉中的大量研究都集中在如何将卷积层、池化层以及全连接层这些基本组件组合起来,形成有效的卷积神经网络。
找感觉的最好方法之一就是去看一些示例,就像很多人通过看别人的代码来学习编程一样。我认为一个很好的方法去了解关于如何构建卷积神经网络,就是去看别人构建的高效卷积神经网络。事实证明,一个神经网络结构,如果在一个计算机视觉问题中表现的很好,通常也会在别的问题中表现很好。
在接下来,我们将会,学习一些计算机视觉领域的研究论文。
2 经典网络
LeNet-5的网络架构是:
从一幅32×32×1的图像开始,而LeNet-5的任务是识别手写数字,LeNet-5是针对灰度图像训练的,这就是为什么他是32×32×1。
LeNet-5的第一层使用六个5×5的过滤器,步长为1,padding为0,输出结果是28×28×6,图像尺寸从32×32缩小到28×28,然后进行池化操作。在这篇论文发表的那个年代,人们更喜欢用平均池化;而现在,我们可能用最大池化更多一点。但是在这个例子中,我们进行平均池化,过滤器的宽度为二,步长为二,图像的高度和宽度都缩小两倍,输出结果是一个14×14×6的图像。
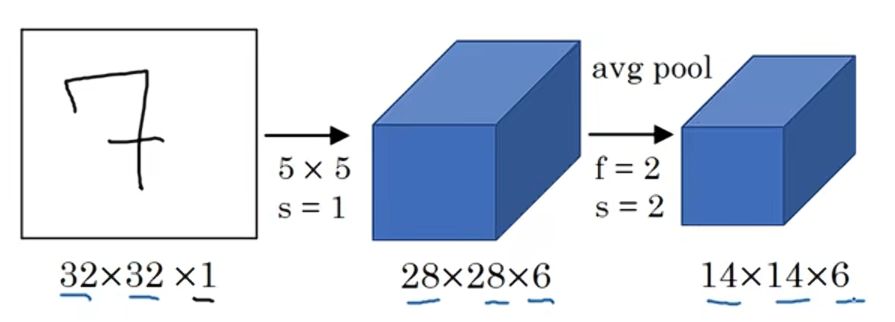
在LeNet-5论文发表的年代,当时人们并不使用padding或者valid卷积,这就是为什么每进行一次卷积,图像的高度和宽度都会缩小一半。
接下来继续用16个5×5,步长为1的过滤器进行卷积,新的输出结果是10×10×16,再进行平池化,输出5×5×16。
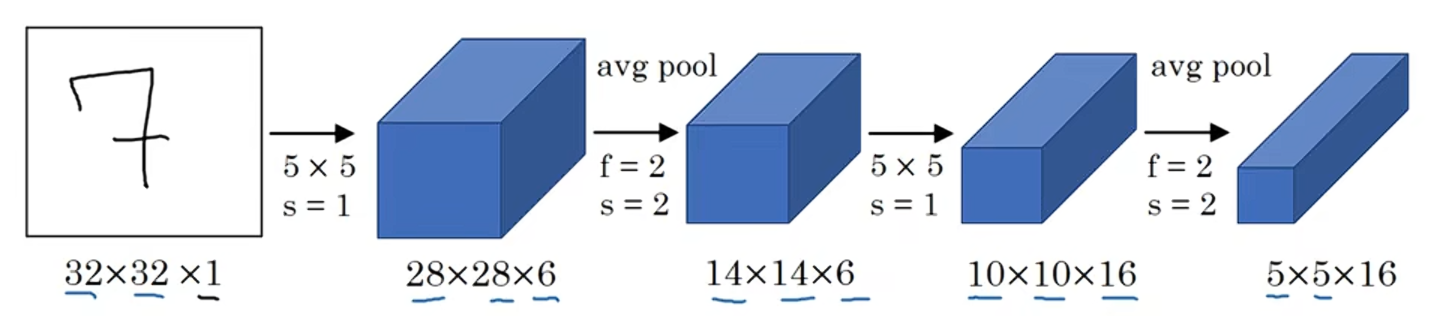
把5×5×16展平成400个神经单元,建立全连接层,120个神经元每个都全连接这400个单元;再建立一层全连接层,用84维特征生成一个最终结果,
可能有10个可能值,对应识别的0-9这10个数字。现在,用Softmax函数输出十种分类结果
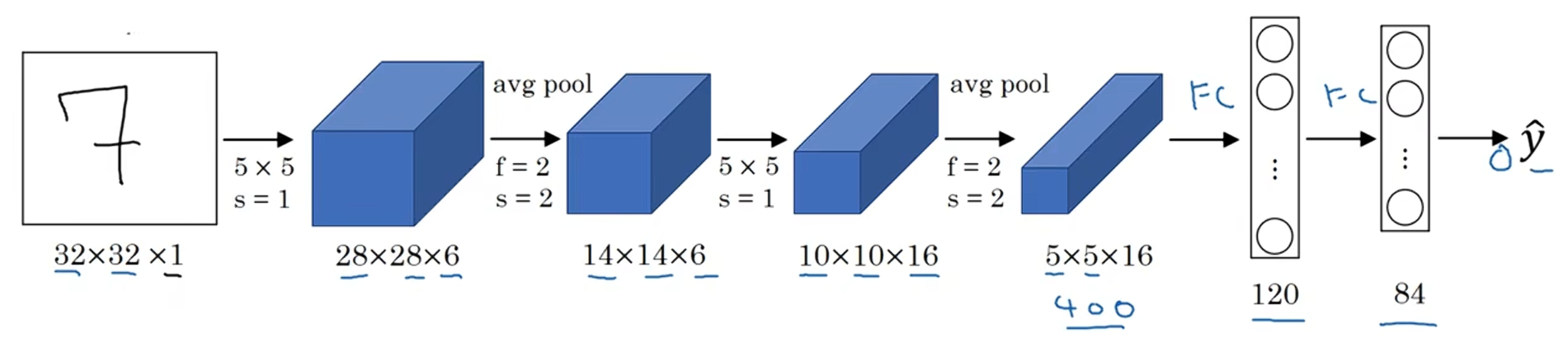
尽管LeNet-5原先是用别的分类器做输出层,而这个分类器现在已经不用了。用现在的标准来看,这是个小型神经网络,大概有6万个参数;而如今你经常会见到千万到亿量级参数的神经网络。不管怎样,如果我们从左往右看这个神经网络,会发现随着网络越来越深,图像的高度和宽度都在缩小,从最初的32×32缩小到28×28,再到14×14,10×10,最后只有5×5;与此同时,随着网络层次的加深,通道数量一直在增加,从1个增加到6个,再到16个。这个神经网络中还有一个模式,至今仍然经常用到,那就是先使用一个或者多个卷积层,后面跟着一个池化层,然后又是若干个卷积层,再接一个池化层,然后是全连接层,最后是输出,这种排列方式很常见。
AlexNet的网络架构是:
AlexNet首先用一张227×227×3的图片作为输入,如果你读了这篇论文,论文提及的是224×224×3的图像,但如果你检查数字,你会发现227×227才合理。
第一层使用96个11×11,步长为4的过滤器,图像尺寸缩小到55×55×96,随后的最大池化层用了3×3的过滤器,尺寸缩小为27×27×96,然后用256个5×5的过滤器进行Same卷积,得到27×27×256,再来一次做最大池化,尺寸缩小到13×13×256。
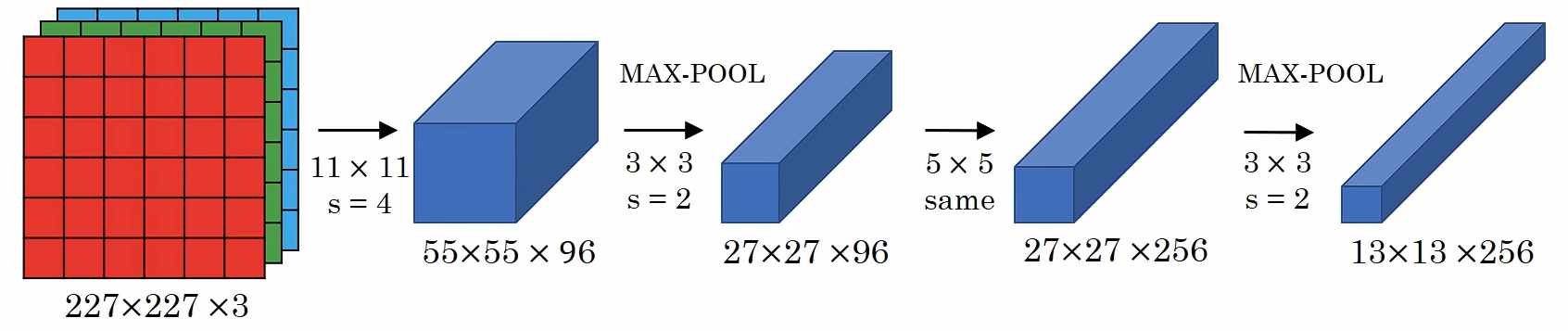

使用384个3×3的过滤器进行两次Same卷积,得到13×13×384;用256个3×3的过滤器进行卷积,得到13×13×256,进行最大池化,尺寸缩小到6×6×256,把他展平成9216个单元,然后进行一些全连接层,使用Softmax函数输出,看他是1000个可能对象中的哪一个?
Alexnet神经网络结构与LeNet有很多相似之处,不过Alexnet要大很多,AlexNet包含约6000万个参数,AlexNet采用与LeNet相似的构造版块,拥有更多隐藏神经元、在更多数据上训练。Alexnet在ImageNet数据库上训练,使它有优秀的性能。
Alexnet神经网络比LeNet更好地原因是:Relu函数的使用。
VGG-16的网络架构是:
按作者所说,关于VGG-16非常值得注意的一点是:VGG-16没有那么多超参数,结构更简单,更能关注卷积层,使用3×3、步长为1的Same过滤器;最大池化的过滤器都是2×2、步长为2。
假设你要识别224×224×3的图像,在最开始的两层,用64个3×3的过滤器对输入的图像进行Same卷积,得到224×224×64的结果,使用最大池化缩小到112×12×64;接着又是使用2层Same卷积层,结果是112×112×128,经过池化层后,维度是56×56×128;再使用三层Same卷积层,使得维度变成56×56×256,接着使用池化层后维度变成28×28×256;再经过三层Same卷积层变成28×28×512,经过最大池化变成14×14×512。再经过卷积、池化,直到最后维度变成7×7×512,把得到的神经单元展平拉直,通过全连接层,经过Softmax函数输出1000类结果。
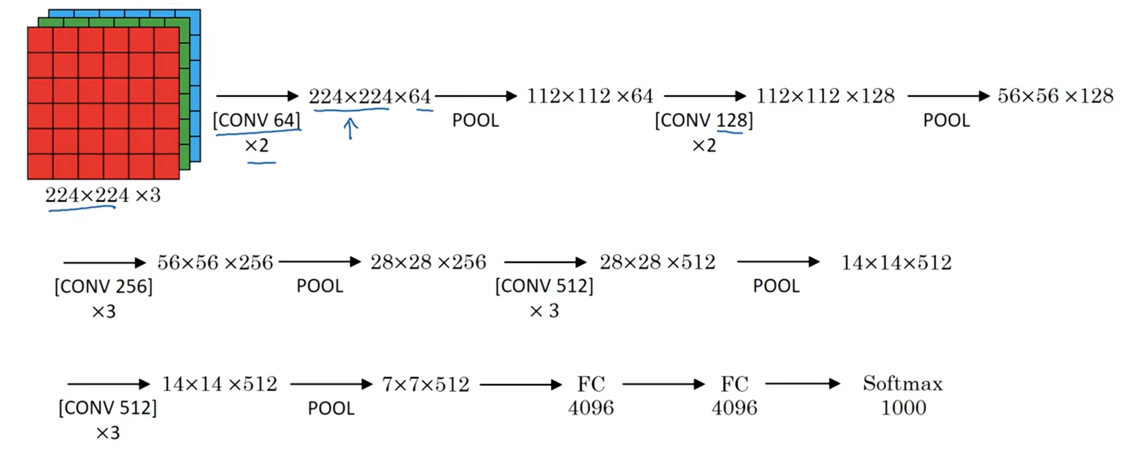
VGG-16中的16指该网络有16层带权重的层,这是一个相当大的网络,它总共有一亿三千八百万个参数。即使以现在的衡量标准,也是很大的 。VGG-16结构的简洁性也非常吸引人,看得出这个结构相当统一,先是几层卷积层,再是池化层。另一方面,如果你看卷积层中过滤器数,从64到128到256再到512,每次粗略的双倍增加过滤器的方式是设计神经网络时用的另一个简单原则。
3 ResNets
太深的神经网络训练起来很难,因为有梯度消失和梯度爆炸问题,我们将学习跳跃连接,它可以允许从某一网络层得到激活值,并迅速传递给下一层甚至是更深的神经网络层,利用它你就可以训练网络层很深的残差网络。残差网络是使用了残差结构的网络。
这里有两层神经网络,代表第L层的激活函数,然后是
,两层后得到
。
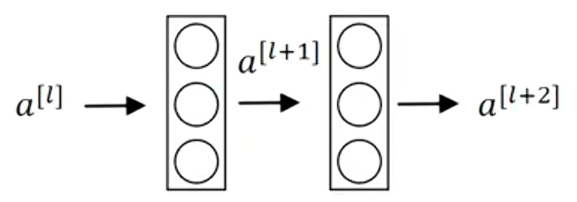
在这个例子的激活函数,作为输入,计算出
,之后应用非线性激活函数Relu得到
;然后在下一层经过线性计算
,再使用一次Relu函数得到
。换句话说,从
流向
的信息需要经过上面的所有步骤,我把这称做这组层的主路径。
在残差网络中,我们需要做个改变,把直接向后连接到深层神经网络的位置。
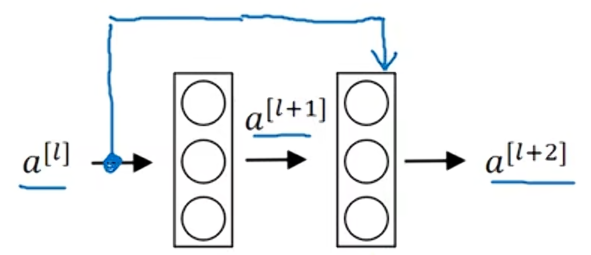
这条路径是在进行Relu非线性激活函数之前加上的。也就是,
。
我们来看看下面这个网络,它并不是一个残差网络,而是一个普通网络:

把它变成ResNet的方法是加上所有的跳跃连接,就像这样:

事实证明,如果你使用标准的优化算法(如梯度下降法)来训练普通网络,从经验上来说,你会发现当你增加层数时,训练误差会在下降一段时间后回升;
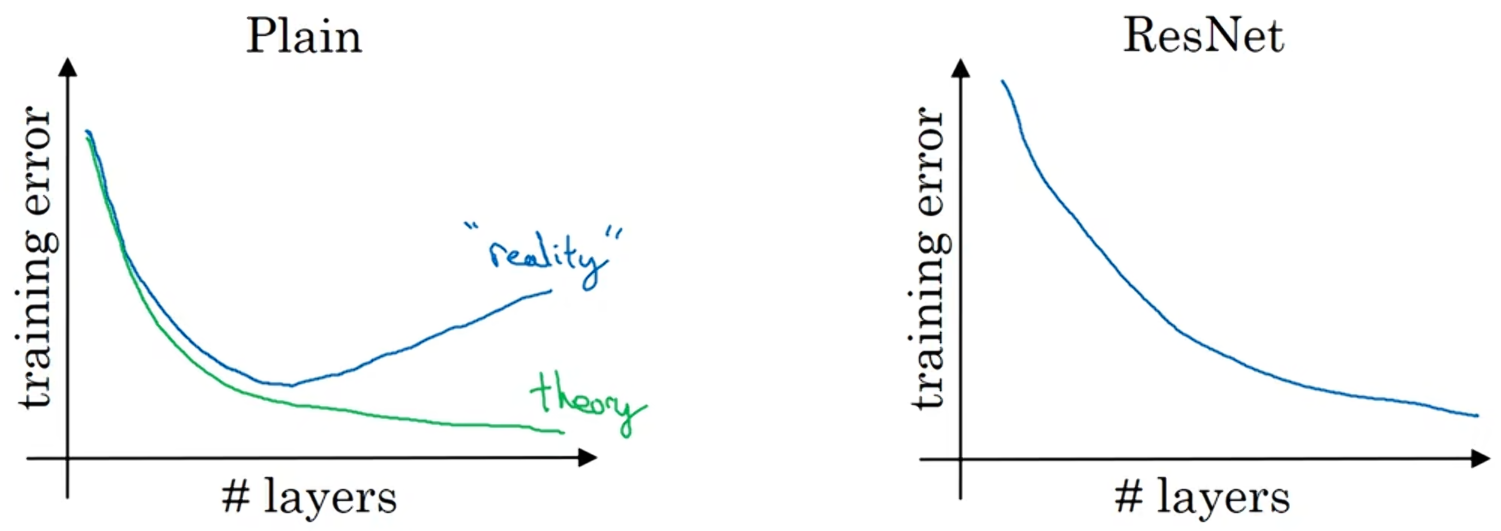
而理论上,随着网络深度的加深,应该训练的越来越好。如果没有残差网络,对于一个普通网络来说,网络越深意味着用优化算法越难训练,训练错误会越来越多;但是有了ResNet就不一样了,即使网络再深,训练表现也不错,训练错误会减少。
4 ResNets 为何有效?
为什么ResNets这么好用呐?
一个网络深度越深,它会使得你用训练集训练神经网络的能力下降,这也是有时候我们不希望加深网络的原因,但当你训练ResNet的时候就不一样了,我们来看一个例子。
如果你有一个大型神经网络,它的输入是x,输出激活值。

如果你想调整神经网络,使其深度更深一点:
把这两层看作是具有跳跃连接的残差块。为了方便说明,假设我们在整个网络中使用Relu激活函数,所有激活值都大于等于零。
我们看一下的值,也就是
,展开这个表达式,也就是:
。注意一点,如果使用L2正则化或者权重衰减,它会压缩
的值,如果对b使用权重衰减也会达到同样的效果。这里的w是关键项,假设
,如果
,那么
,
。因为我们假设使用Relu激活函数,并且所有激活值都是非负的,
是非负的,所以结果是
,这意味着残差块比较容易学习恒等函数,由于这个跳跃连接也很容易得到
,将这两层加入到你的神经网络,与上面这个没有这两层的网络相比,并不会非常影响神经网络的能力,因为对于它来说学习恒等函数非常容易。所以这就是为什么添加两层,不论是把残差块添加到神经网络的中间还是尾部都不会影响神经网络的表现。
当然,我们的目标并不只是维持原有的表现,而是帮助获得更好的表现。你可以想象,如果这些隐藏单元学习到一些有用信息,那么它可能比学习恒等函数表现的更好;而这些不含残差块或跳跃连接的普通神经网络,情况就不一样了。当网络不断加深时,就算是选择用来学习恒等函数的参数也很困难,所以很多层最后的表现,不但没有更好,反而更糟。
我认为残差网络起作用的主要原因是:这些额外层学习恒等函数非常容易,几乎总能保证它不会影响总体的表现,很多时候甚至可以提高效率,或者说至少不会降低网络效率。
除此之外,关于残差网络另一个值得讨论的细节是:对于,我们是假定
和
具有相同的维度。所以你会看到在ResNet中许多Same卷积的使用。如果输入和输出有不同的维度,假如
是128维,而
和
的结果是256维的,我们可以让
与一个256×128维的
矩阵相乘,也就是
。