前一博文我们认识了循环神经网络参数学习的随时间反向传播算法BPTT,本文我们来了解实时循环学习RTRL。
与反向传播的 BPTT 算法不同的是,实时循环学习(Real-Time Recurrent Learning,RTRL)是通过前向传播的方式来计算梯度。
一、数学公式及推导
假设循环神经网络中第 𝑡 + 1 时刻的状态 𝒉_(𝑡+1) 为:
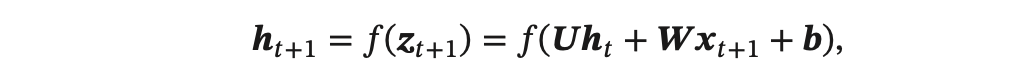
经过数学推导(推导过程比较复杂,略),假设第 𝑡 个时刻存在一个监督信息,其损失函数为 L𝑡,就可以同时计算损失函数对 𝑢𝑖𝑗 的偏导数:
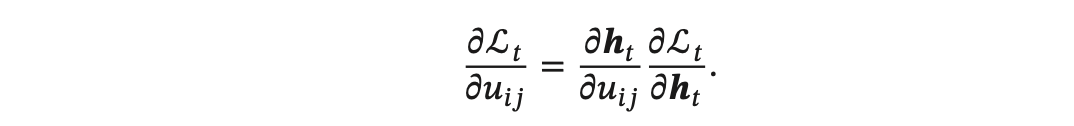
这样在第 𝑡 时刻,可以实时地计算损失 L𝑡 关于参数 𝑼 的梯度,并更新参数。参数 𝑾 和 𝒃 的梯度也可以同样按上述方法实时计算。
与随时间反向传播算法BPTT相比,RTRL 算法和 BPTT 算法都是基于梯度下降的算法,分别通过前向模式和反向模式应用链式法则来计算梯度。在循环神经网络中,一般网络输出维度远低于输入维度,因此 BPTT 算法的计算量会更小,但是 BPTT 算法需要保存所有时刻的中间梯度,空间复杂度较高。RTRL 算法不需要梯度回传,因此非常适合用于需要在线学习或无限序列的任务中。
二、进一步理解实时循环学习
实时循环学习(Real-Time Recurrent Learning, RTRL)是一种用于训练循环神经网络(RNN)的在线算法,其核心思想是在每个时间步实时更新梯度,而不必像 BPTT 那样先将整个序列“展开”后再反向传播。
原理概述
在 RNN 中,每个时间步的隐藏状态不仅依赖当前输入,还受到之前所有时刻的影响。传统的 BPTT 需要先沿时间展开整个网络,再倒退计算梯度;而实时循环学习的思想是“当即”计算当前隐藏状态对所有参数的敏感度(即局部雅可比矩阵),并递归更新。这种方法使得每个时刻都能“实时”获得梯度信息,从而在序列流动中一步步更新参数,适合在线学习场景。
实时循环学习的主要思想是:
-
在线计算梯度:在每个时间步,不仅计算该步输出的误差,还保持一个对参数的导数的累计(例如,隐藏状态对参数的雅可比矩阵),以便立即更新参数。
-
递归更新雅可比矩阵:由于 ht 的计算依赖于 ht−1 ,隐藏状态对参数的偏导数也呈现出递归关系,算法通过递归公式将前一时刻的梯度信息传递到当前时刻。
-
避免全序列展开:与 BPTT 不同,RTRL 不需要将整个序列展开后进行反向传播,而是在每个时间步即时计算并更新,这使其更适合需要实时或在线更新的应用场景。
算法过程及具体步骤
假设一个 RNN 模型,其前向计算公式为:
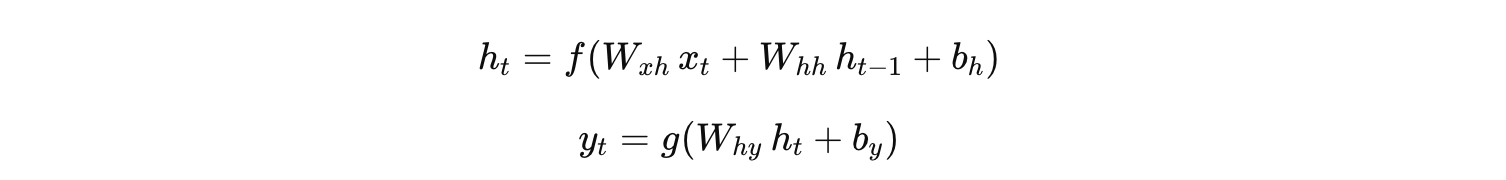
其中 f(⋅) 是激活函数(如 tanh),参数 θ 包括 Wxh、Whh(以及偏置 bh),这些参数均为共享参数。
RTRL 的具体实现过程包括以下四个关键步骤:
1. 局部梯度计算
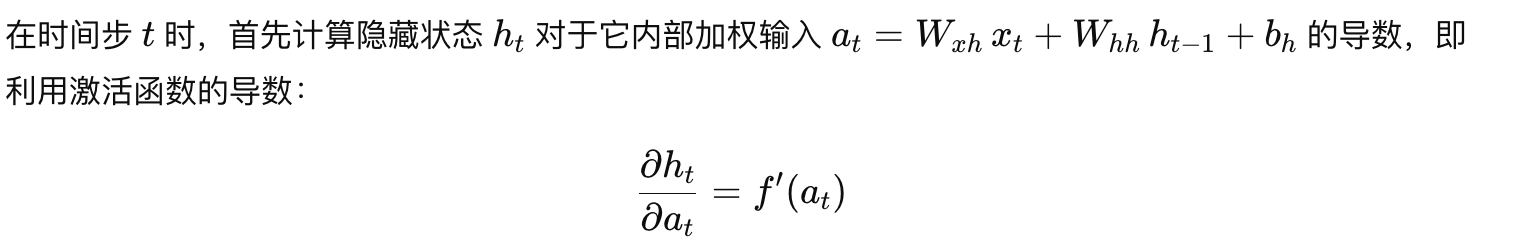
这一步给出当前时间步的局部敏感性,它决定了后续如何利用当前误差反向传递到参数。
2. 梯度传递与雅可比矩阵更新

其中 Xt 表示当前输入部分对参数的直接导数(例如,对于 Wxh,它为 xt,对于 Whh ,当前输入部分为零,因为 ht−1 在 t 时刻才参与计算,但相应地参数的求导需要考虑这部分贡献)。 这一步中,我们既利用了当前时刻的局部梯度,也将上一时刻累积的梯度通过 Whh 传递到当前,从而捕获了整个历史信息。
3. 参数梯度累积
在每个时间步,计算隐藏状态对各输出损失的贡献:
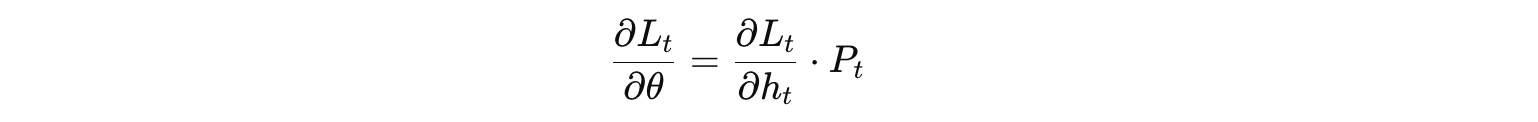
其中 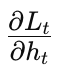 是当前时间步损失对隐藏状态的梯度。由于参数在所有时间步均共享,最终的梯度是所有时间步梯度的求和:
是当前时间步损失对隐藏状态的梯度。由于参数在所有时间步均共享,最终的梯度是所有时间步梯度的求和:
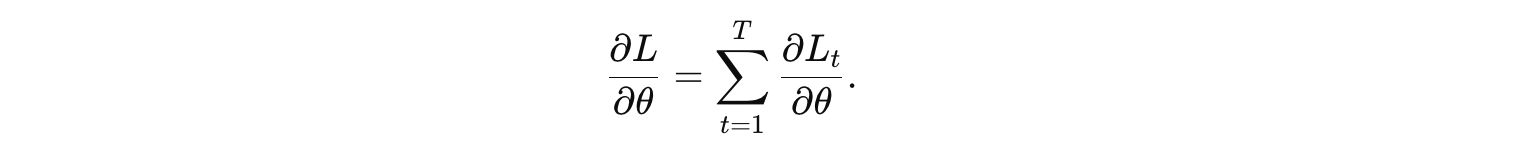
4. 参数更新
在累积完整个时间序列的梯度后,利用梯度下降或其他优化算法进行参数更新:
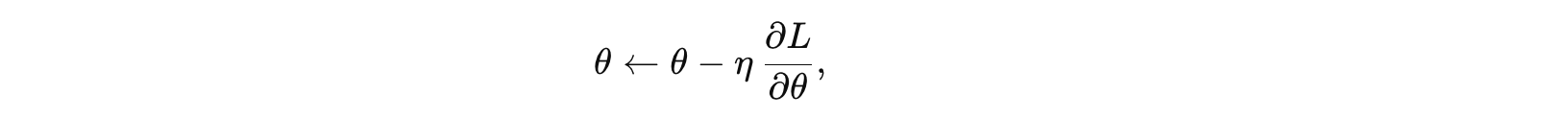
其中 η 是学习率。
举例说明
假设我们有一个长度为 3 的序列进行在线训练。我们希望模型学习到某个简单关系,如“将输入值加 1”。具体过程如下:
-
前向传播:
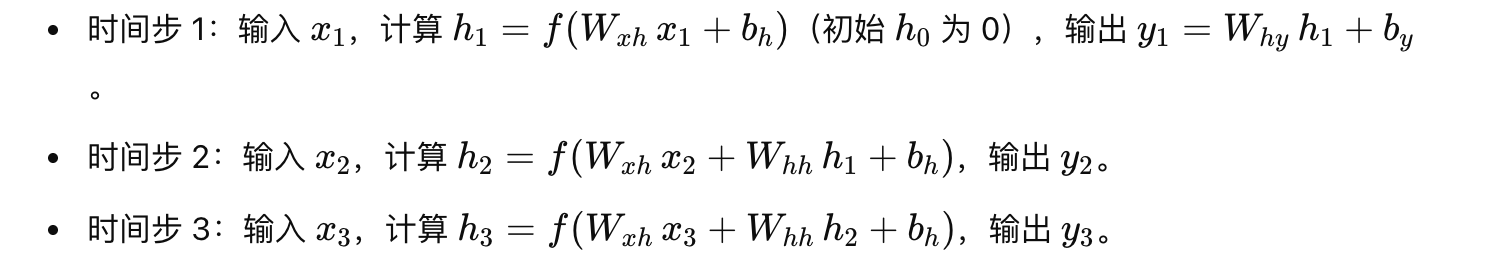
-
局部梯度计算:
在时间步 3,先计算损失对输出 y3 的梯度,然后反向传播到 h3: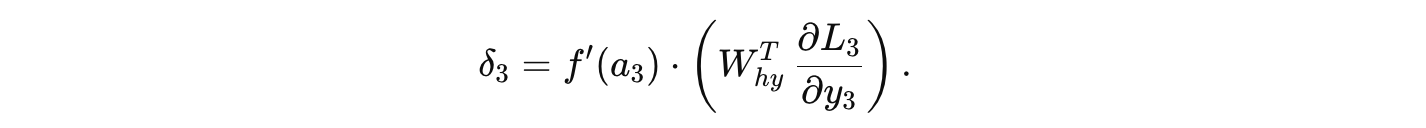
类似地,时间步 2和1也各自计算对应的局部梯度 δ2 与 δ1。
-
梯度传递与雅可比更新:

-
参数梯度累积与更新:

总结
-
局部梯度计算:在每个时间步先计算当前输出误差对隐藏单元输入的局部梯度(乘以激活函数导数)。
-
梯度传递与累积:利用递归公式,用当前时间步的局部梯度加上从未来时刻传来的梯度(经过 Whh)构成当前时刻对隐藏状态的总梯度,并更新对应的雅可比矩阵 Pt。
-
参数梯度累积:将每个时间步对参数的梯度累加,形成对共享参数的整体梯度。
-
参数更新:利用优化算法实时更新参数。
这种实时在线计算梯度并更新参数的方法,使模型能够在每个时间步及时调整,对连续数据流进行在线学习。虽然 RTRL 在计算和存储上成本较高,但它为“实时循环学习”提供了理论支持,展示了如何通过递归梯度更新捕捉长时依赖关系。