protobuf协议介绍与使用
- 引言
- Protobuf简介
- Protobuf的优势
- Protobuf的基本工作原理
- 四、.proto文件语法
- Python傻瓜式应用教学
- 环境安装
- proto文件
- 编译.proto文件
- 使用生成的Python代码
- 生成JS代码
- 总结
引言
遇到一个站点,它的content-type竟然是application/grpc-web+proto,

请求体是这种不规则的结果,跟往常遇到的都不一样

特别是响应内容看都看不懂,应该是二进制数据或者某种协议编码数据

此刻内心跟土拨鼠是一样一样的…

咱们来交叉提问了解一些信息:
问:application/grpc-web+proto啥意思
答:application/grpc-web+proto 是一个HTTP头部字段,用于指定传输的数据类型为gRPC-Web协议,并且数据内容是基于Protocol Buffers(protobuf)格式编码的。这个头部告诉接收方,传入的数据是按照gRPC-Web协议格式化的protobuf消息。
问:啥是gRPC-Web
答:gRPC-Web是一种技术,它允许gRPC服务通过Web浏览器直接访问。
问:啥是gRPC
答:gRPC是由google开源的高性能的RPC框架
问:啥是Proto文件
答:Proto文件使用Protocol Buffers(protobuf)语言编写,这是一种由Google开发的语言中立、平台中立、可扩展的序列化结构化数据的方法。
问:gRPC-Web与proto文件的关系
答:在gRPC-Web中,proto文件被编译成客户端和服务器都能理解的代码,从而实现了跨语言的RPC调用。
强大的google,只能gRPC-Web+protobuf是一套高性能的框架,能让前端和后端可以高效地交换数据,不过对爬虫来说确实一个拦路虎,要拿到数据我们得搞定protobuf…
Protobuf简介
Protocol Buffers(简称Protobuf)是由Google开发的一种与语言无关、平台无关、可扩展的序列化结构数据的方法,它可用于通信协议、数据存储等。Protobuf通过将结构化的数据序列化为紧凑的二进制格式,从而实现了高效的存储和传输。
Protobuf的优势
- 高效:Protobuf的二进制格式比XML和JSON更加紧凑,传输和存储效率更高。
- 跨语言:Protobuf支持多种编程语言,如C++、Java、Python等,方便不同语言之间的数据交换。
- 可扩展:Protobuf允许在不破坏现有数据的情况下添加新的字段,具有良好的向后兼容性。
Protobuf的基本工作原理
- 定义数据结构:使用.proto文件描述数据结构。
- 编译.proto文件:使用Protobuf编译器(protoc)将.proto文件编译成目标语言的代码。
- 使用生成的代码:在应用程序中使用生成的代码进行数据的序列化和反序列化。
四、.proto文件语法
.proto文件用于定义消息类型,其基本语法如下:
syntax = "proto3"; // 指定使用proto3语法package example; // 定义包名,用于区分不同项目或模块中的消息类型// 定义消息类型
message Person {string name = 1; // 字段名为name,类型为string,字段编号为1int32 id = 2; // 字段名为id,类型为int32,字段编号为2string email = 3; // 字段名为email,类型为string,字段编号为3
}
Python傻瓜式应用教学
环境安装
Protobuf需要安装编译器,用于编译.proto文件
GitHub传送门,下载window版本的压缩包即可
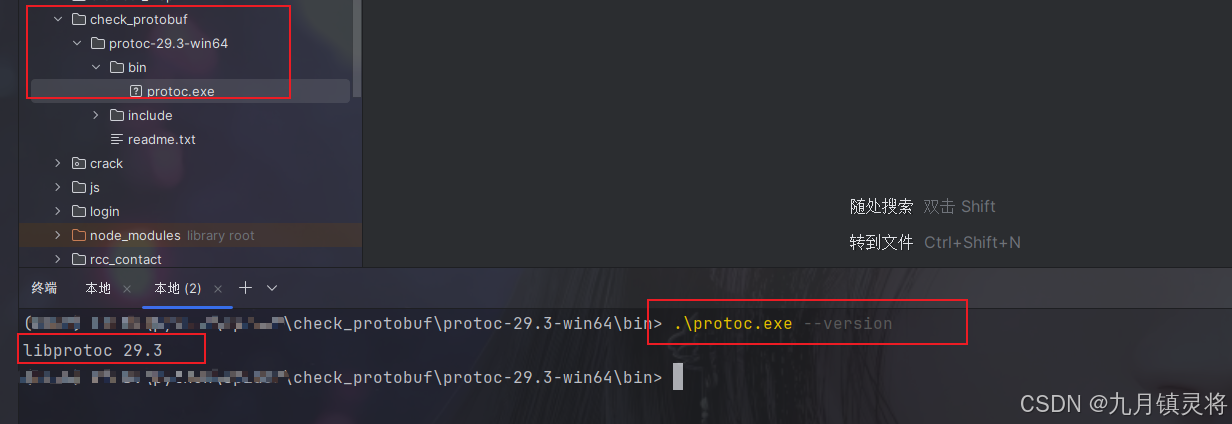
下载后解压缩放到项目目录下,使用protoc.exe --version测试安装成功
然后,使用pip安装Python的Protobuf库 pip install protobuf
proto文件
创建一个名为person.proto的文件,内容如下:
syntax = "proto3";package example;message Person {string name = 1;int32 id = 2;string email = 3;
}
编译.proto文件
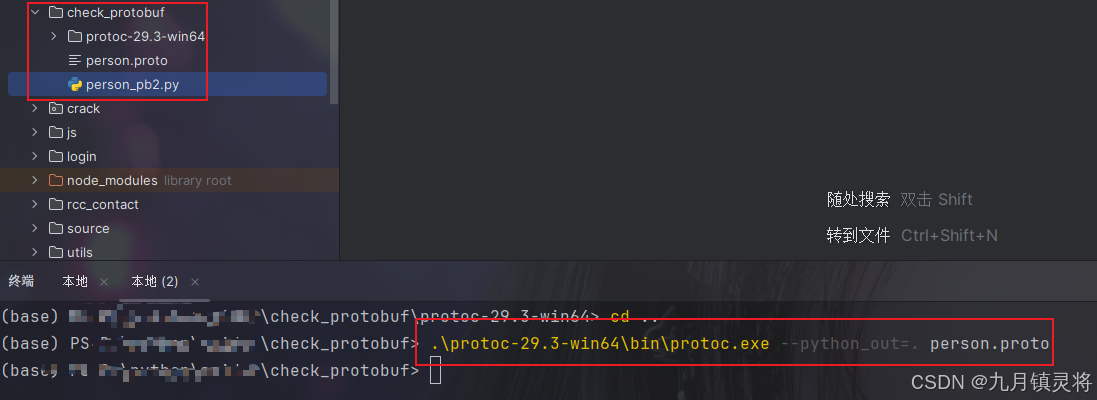
使用Protobuf编译器将person.proto文件编译成Python代码。
protoc --python_out=. person.proto
这将在当前目录下生成一个名为person_pb2.py的文件。
使用生成的Python代码
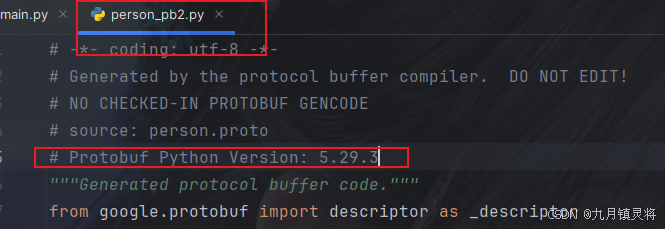
注意Protobuf python版本要跟person_pb2.py注明的一致
创建一个Python脚本,内容如下:
import person_pb2# 创建一个Person对象
person = person_pb2.Person()
person.name = "Alice"
person.id = 1234
person.email = "alice@example.com"# 序列化Person对象
serialized_data = person.SerializeToString()
print(f"Serialized data: {serialized_data}")# 反序列化数据
new_person = person_pb2.Person()
new_person.ParseFromString(serialized_data)# 打印反序列化后的对象
print(f"Name: {new_person.name}")
print(f"ID: {new_person.id}")
print(f"Email: {new_person.email}")
运行脚本,你将看到以下输出:

生成JS代码
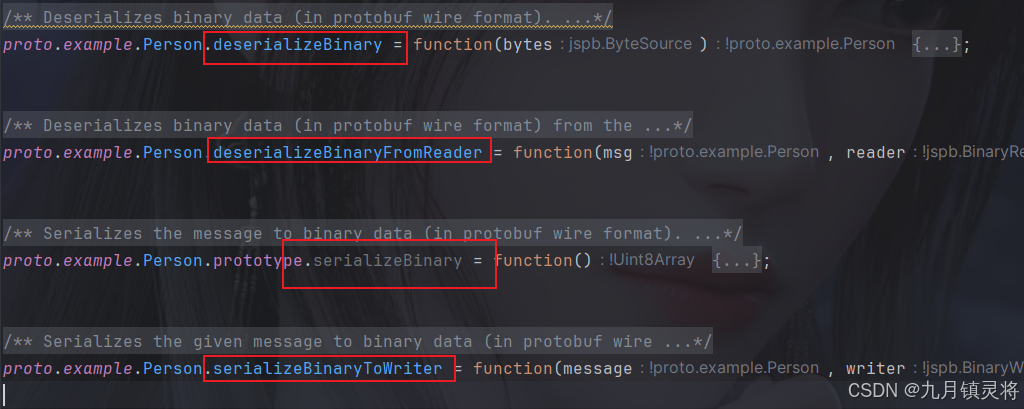
对于爬虫来说,我们主要面对的应该是Protobuf 的JS代码,提前熟悉它的代码结构和样式能有效帮助我们定位和逆向。
使用.\protoc-29.3-win64\bin\protoc.exe --js_out=. person.proto命令即可生成对应的jJS代码,但是需要先安装nodejs依赖
npm i google-protobuf
npm install protoc-gen-js
这些都是它的关键参数标识
总结
这篇文章主要介绍protobuf协议,具体的爬虫逆向处理过程后面再介绍!
这篇讲解更多:通过JS逆向ProtoBuf 反反爬思路分享,我也记录记录。
