metric self-join
The self-similarity join in metric spaces
对于给定的一组数据 D ⊆ U D\subseteq U D⊆U,self-simility join D ⋈ s D D\bowtie_s D D⋈sD 定义为找到所有数据对 ( x , y ) , x , y ∈ D , x ≠ y (x,y) ,x,y\in D,x\neq y (x,y),x,y∈D,x=y,并且在相似性判定条件下 x , y x,y x,y 是相似的。
它是一种数据挖掘和数据库领域的技术,用于在数据集中找到所有满足特定相似性度量的对象对。它的提出是为了优化数据分析中的相似性查询,尤其是在低维度数据中。这种技术在许多算法中作为子程序使用,例如 DBSCAN 聚类算法和时间序列数据分析。
metric self-join 的结果为 KNN 图的构建提供了基础。两者的主要区别在于 metric self-join 关心的是满足相似性条件的所有点对,而 KNN 图进一步限定了只保留最近的 k 个邻居,所以说这两者在某种程度上等同,所以SISAP 2025挑战中提到KNN图构建(或者说metric self-join)
提一点有关ANN的说法
参考自向量索引算法HNSW和NSG的比较,即为什么要研究图上算法
现在常用的索引类型以及它们的局限性。
首先是基于树的算法,这里举例较为经典的 KD-tree 。这种索引类型在向量维度稍大一些的情况下 (d>10) ,索引性能会急剧下降甚至不如暴力搜索。再说说基于 LSH (locality-sensitive hashing) 的索引,如果想要取得高召回率, LSH 算法必须要建立大量的 Hash 表,这会使得索引大小膨胀数倍。
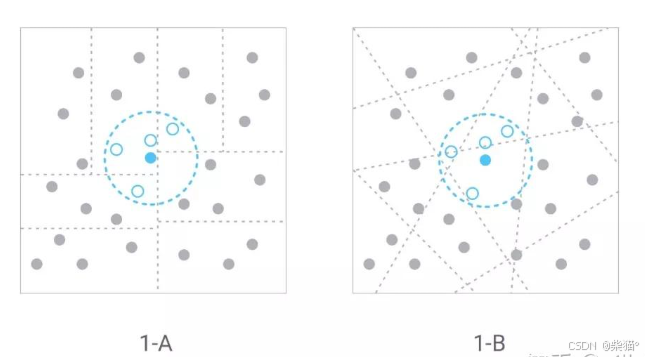
不仅如此,树和 LSH 都属于空间切分类算法,此类算法有一个无法避免的缺陷,即为了提高搜索精度,只能增大搜索空间。图 1-A 描述了基于树的切分搜索,每个虚线分割出的区域是一个子树,如果搜索向量在子树的边缘时,算法需要搜索多个子树来获取结果。图 1-B 描述了基于 Hash 的切分搜索,虚线描述了每个独立的hash表,搜索面临的问题与基于树的搜索算法类似。所以空间切分类算法在最坏的情况下需要扫描几乎整个数据集,这在很多场景下显然是无法接受的。
由于图数据结构有天生近邻关系的特性,在图上做最近邻搜索看来是一种不错的思路,所以近年来基于图的向量搜索算法也是一个研究热点。
文中还详细说明了HNSW和NSG的不同,这里放上他的总结:
HNSW 从结构入手,利用分层图提高图的导航性减少无效计算从而降低搜索时间,达到优化的目的。而 NSG 选择将图的整体度数控制在尽可能小的情况下,提高导航性,缩短搜索路径来提高搜索效率。
HNSW 由于多层图的结构以及连边策略,导致搜索时内存占用量会大于 NSG,在内存受限场景下选择 NSG 会更好。
但是 NSG 在建图过程中无论内存占用还是耗时都大于 HNSW。
此外 HNSW 还拥有目前 NSG 不支持的特性,即增量索引,虽然耗时巨大。
对比其他的索引类型,无论 NSG 还是 HNSW 在搜索时间和精度两个方面,都有巨大优势。
复合索引结构
主要参考Faiss: The Missing Manual中的内容
A composite index is built from any combination of:
- Vector transform — a pre-processing step applied to vectors before indexing (PCA, OPQ).
- Coarse quantizer — rough organization of vectors to sub-domains (for restricting search scope, includes IVF, IMI, and HNSW).
- Fine quantizer — a finer compression of vectors into smaller domains (for compressing index size, such as PQ).
- Refinement — a final step at search-time which re-orders results using distance calculations on the original flat vectors. Alternatively, another index (non-flat) index can be used.
Note that coarse quantization refers to the ‘clustering’ of vectors (such as inverted indexing with IVF). By using coarse quantization, we enable non-exhaustive search by limiting the search scope.
Fine quantization describes the compression of vectors into codes (as with PQ) . The purpose of this is to reduce the memory usage of the index.
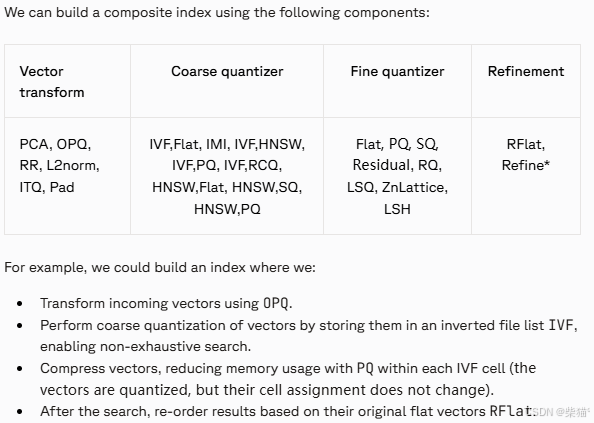
流行的复合结构
IVFADC
IVFADC的核心是IVF256和PQ32这两个索引的组合。
该索引方法于2010年与乘积量化一起提出[H. Jégou, et al.,Product quantization for nearest neighbor search(2010),TPAMI]。从那时起,它一直是最受欢迎的索引之一——它有着合理的召回率、很快的速度和超低的内存使用量。但是,它的缺点是召回性能比较一般,只能说还说得过去。
使用IVFADC进行索引有两个步骤:
- 向量被分配到IVF结构中的不同列表(或沃罗诺伊Voronoi分区。沃罗诺伊图基于一组特定点将平面分割成不同区域,而每一区域又仅包含唯一的特定点,并且该区域内任意位置到该特定点的距离比到其它的特定点都要更近)。
- 向量使用 PQ 进行压缩。
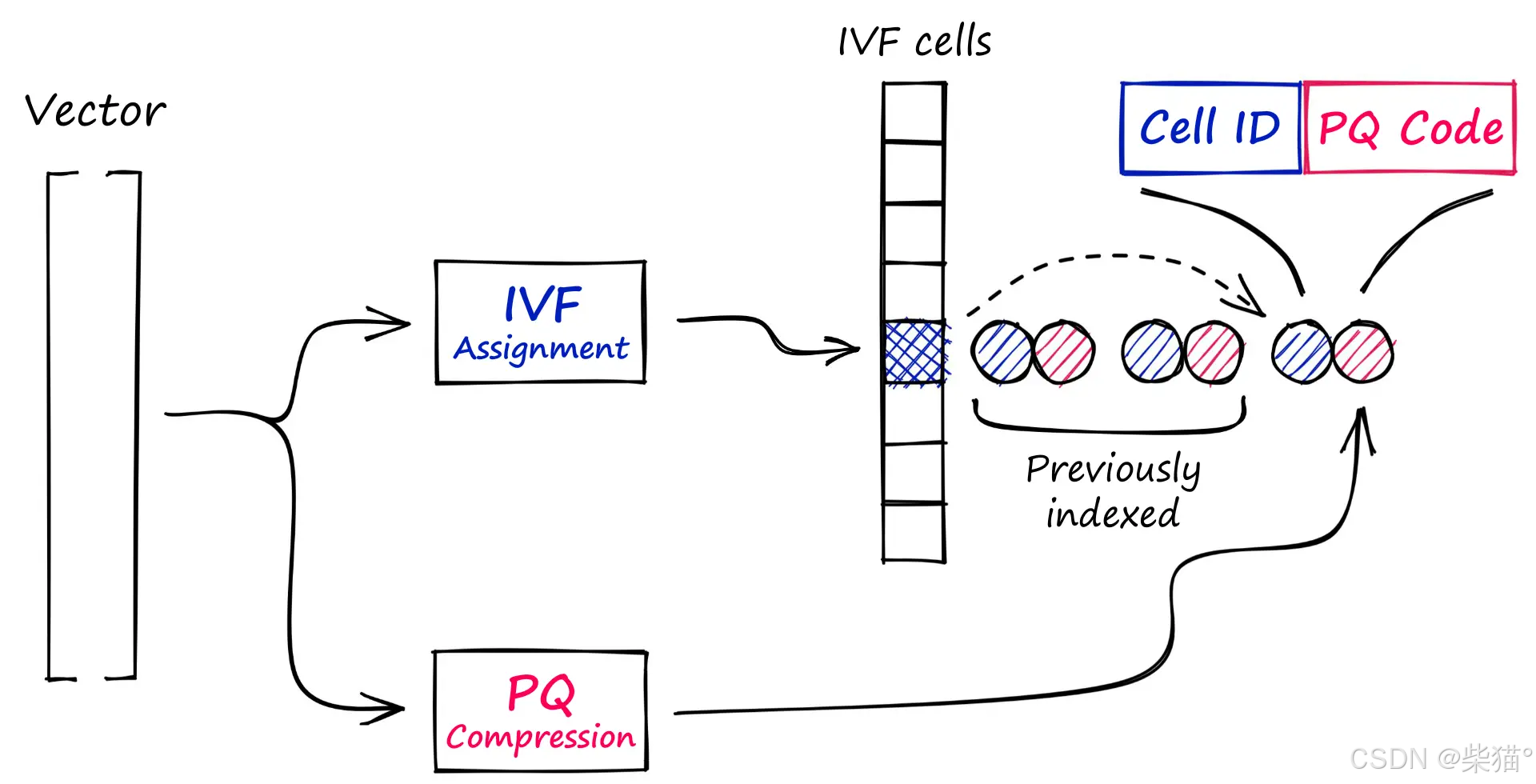
索引向量后,在查询向量 xq 和我们的索引量化向量之间执行非对称距离计算 (Asymmetric Distance Computation:ADC)
之所以被称为非对称搜索,是因为它将未压缩的 xq 与索引中被压缩的 PQ 向量进行比较。与之相反,SDC是将查询向量xq先进行压缩量化,再去已经压缩的索引中比对。
(其实就是我在PQ笔记中提到的在的查询到来时的两种距离计算方式,SDC就是方式一,ADC就是方式二)
Multi-D-ADC
Multi-D-ADC是指多维(multi-dimention)索引+PQ算法,PQ在搜索时进行不对称的距离计算(ADC,见前面)。[A. Babenko, V. Lempitsky,The Inverted Multi-Index(2012),CVPR]
多维ADC索引基于倒排多索引(IMI),它是IVF的一种变体。IMI在召回和搜索速度方面都优于IVF,但增加了内存使用量。所以当IVF+ADC方法在召回和速度上差强人意时,可以使用IMI索引(如多D-ADC),并且(在有些情况下)还可以节省更多的内存使用。IMI索引的工作方式与IVF非常相似,但Voronoi图是在向量的一些子维度上进行分区。这产生的类似于多级Voronoi分区结构。
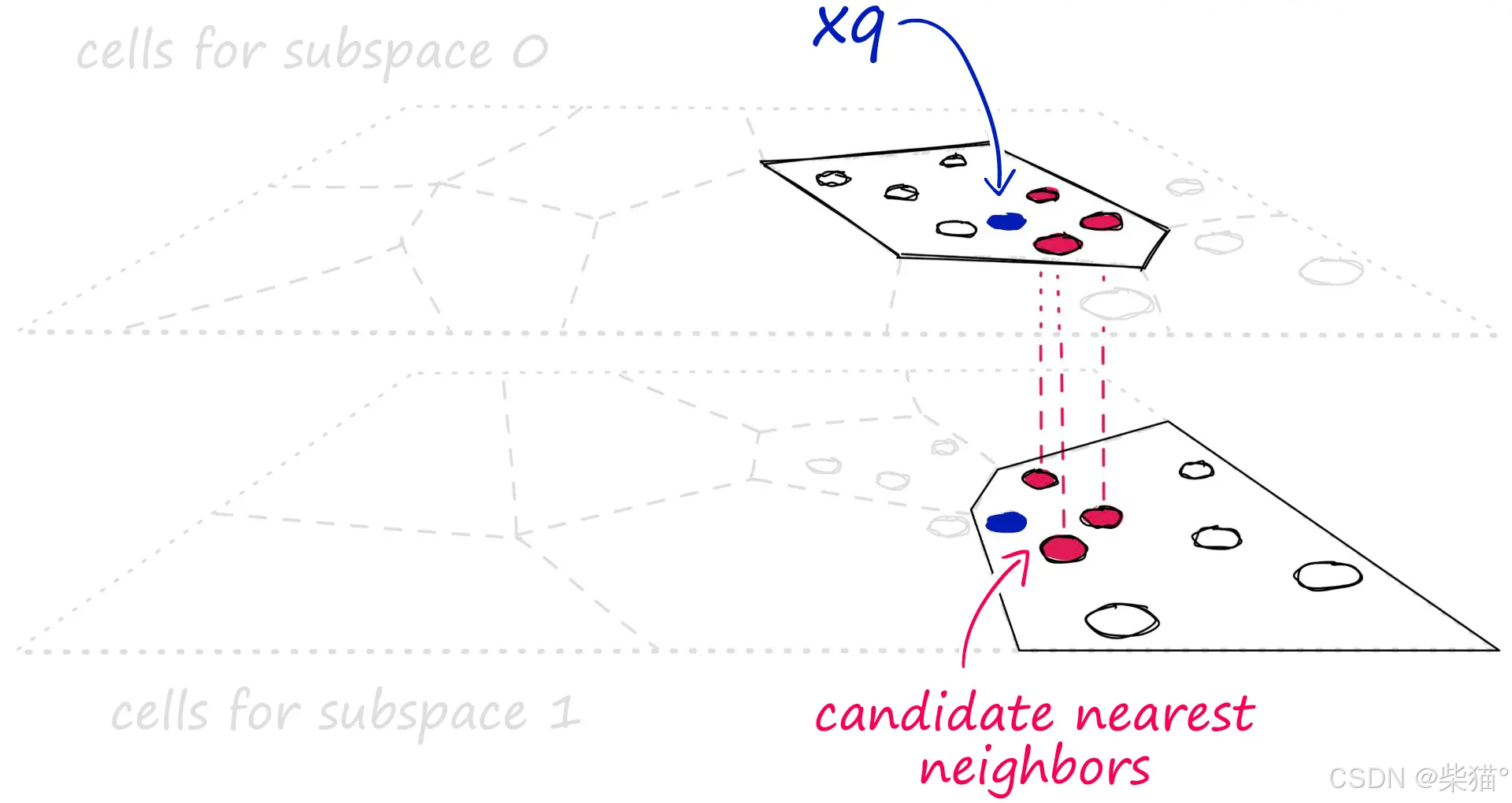
在引入HNSW之前,效果最优的方法是加了OPQ预处理的Multi-D-ADC方法:“OPQ32,IMI2x8,PQ32”
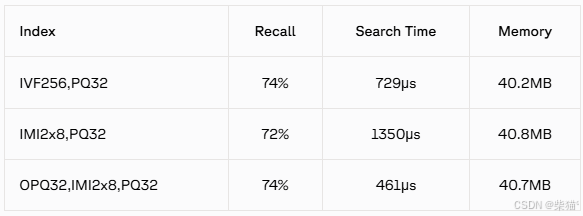
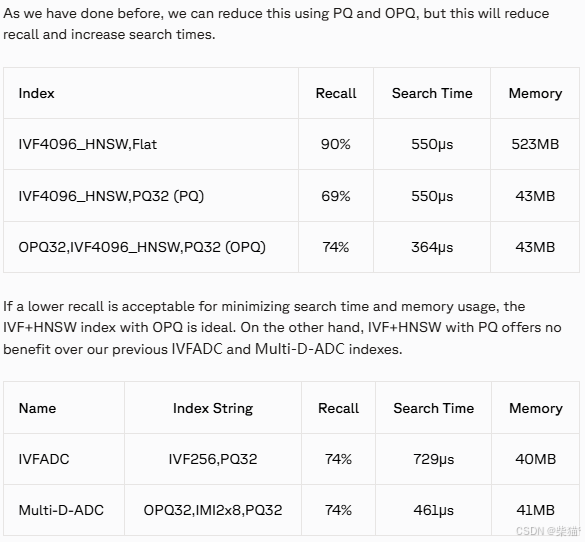
引入HNSW后
介绍一下OPQ
OPQ是在PQ的基础上进一步优化的一种技术,它通过对向量进行旋转变换,将分布不均匀的数据重新调整,使其在各个子向量维度上更均匀。这种预处理使量化后的数据更加高效。
工作流程:
- 使用旋转矩阵对原始向量进行变换,使其分布更均匀。
- 再使用PQ对变换后的向量进行量化。
优势:提升召回率,特别是在向量数据分布不均匀时效果显著。
缺点:额外的旋转计算可能会增加少量处理时间。
旋转变换的作用
在产品量化(PQ)中,向量会被分割为多个子向量,并分别进行量化。然而,如果原始向量数据分布不均匀,各个子向量之间可能存在显著的差异,导致量化误差较大。旋转变换(通过旋转矩阵)可以对向量的整体分布进行调整,将分布不均的特性“平滑”化,使每个子向量的分布更加均匀。
通过这种优化,可以有效降低量化误差,从而提高召回率和检索精度。
旋转变换的具体实现
OPQ的旋转变换采用一个优化的旋转矩阵进行计算,该过程包括以下步骤:
-
训练旋转矩阵:通过使用样本数据来学习最佳旋转矩阵。该矩阵的设计目标是最小化量化误差。
-
应用旋转矩阵:对所有输入向量进行线性变换,通过矩阵乘法将输入向量映射到新的空间。
-
子向量分割:在变换后的空间中,将向量分割为多个子向量,以准备后续的产品量化步骤。
公式表达: y = R ⋅ x \mathbf{y} = \mathbf{R} \cdot \mathbf{x} y=R⋅x 其中:𝑥是原始向量,𝑅是旋转矩阵,𝑦是旋转后的向量。
为什么旋转变换能平滑分布?
旋转变换的理论基础来源于线性代数。简单来说:
-
重新分配特征相关性:旋转矩阵通过对原始向量进行正交变换,可以将原本高度相关的维度解耦,使它们在不同子向量中分布得更均匀。
-
优化全局特征分布:这种重新排列可以将某些维度的过度变化“扩散”到整个向量中,从而避免单一子向量承担过多的信息。
旋转变换是否有效,依赖于数据分布。如果数据的原始分布已经非常均匀(例如标准正态分布),旋转的收益可能有限。但对于那些在某些维度上分布不均的数据集(如高维稀疏数据),旋转可以显著改善量化性能,进而提升检索精度。
与PCA最后操作(类旋转)的比较
PCA的最后一步数据投影与旋转:将原始数据投影到由特征向量定义的新坐标系中。这一步可以看作是对数据的旋转,因为数据从原始空间转移到了主成分空间。
公式表示为: Y = X ⋅ P \mathbf{Y} = \mathbf{X} \cdot \mathbf{P} Y=X⋅P 其中:𝑋 是原始数据矩阵,𝑃 是包含特征向量的矩阵(旋转矩阵),𝑌 是转换后的数据矩阵。
注意这里是右乘
PCA最后的旋转:
-
目的是降低数据维度,同时保留最大方差方向上的信息。
-
数据的旋转是为了找到新的坐标系,使数据尽可能集中在少数几个维度上。
OPQ事先的旋转:
-
目的是优化子向量分布,使得产品量化(PQ)效果更好。
-
数据的旋转是为了将数据的分布“平滑化”,使得子向量的分布更加均匀。
矩阵左乘和右乘的差异
- 操作对象不同:
-
左乘作用于列向量,通常用于坐标系变换。
-
右乘作用于行向量,通常用于操作向量数据。
- 意义不同:
-
左乘的结果是向量在新坐标系中的表示。
-
右乘的结果是向量数据本身的重新分布或操作。
- 适用场景:
-
左乘用于图形变换、物体旋转等场景。
-
右乘用于矩阵叠加、数据处理等场景。