REINFORCE 算法推导
REINFORCE算法是一种基于策略梯度的蒙特卡洛强化学习算法,通过直接优化策略参数以最大化期望回报。基本原理:REINFORCE属于策略梯度方法,其核心是通过梯度上升调整策略参数θ,使得高回报的动作被赋予更高的概率。具体来说,算法通过采样完整的轨迹(episode)计算累积回报,并用其估计梯度,进而更新策略。
1. 目标函数
策略梯度方法的目标是最大化期望累积回报:
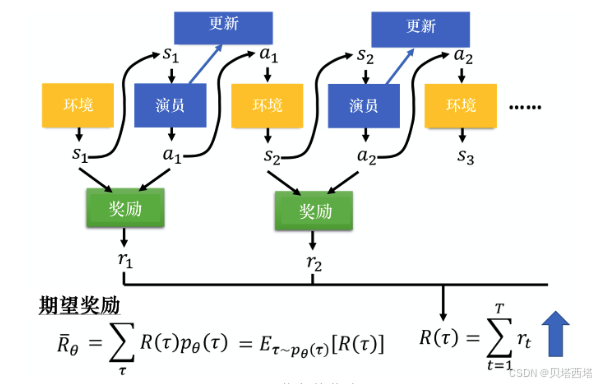
J ( θ ) = E τ ∼ π θ [ R ( τ ) ] J(\theta) = \mathbb{E}_{\tau \sim \pi_\theta} \left[ R(\tau) \right] J(θ)=Eτ∼πθ[R(τ)]
其中:
- τ = ( s 0 , a 0 , r 0 , . . . , s T ) \tau = (s_0, a_0, r_0, ..., s_T) τ=(s0,a0,r0,...,sT) 是轨迹(Trajectory)
- R ( τ ) = ∑ t = 0 T γ t r t R(\tau) = \sum_{t=0}^T \gamma^t r_t R(τ)=∑t=0Tγtrt 是轨迹的折扣回报
- γ \gamma γ 是折扣因子
2. 策略梯度定理
对目标函数求梯度:
∇ θ J ( θ ) = ∇ θ E τ ∼ π θ [ R ( τ ) ] \nabla_\theta J(\theta) = \nabla_\theta \mathbb{E}_{\tau \sim \pi_\theta} \left[ R(\tau) \right] ∇θJ(θ)=∇θEτ∼πθ[R(τ)]
2.1 期望展开为轨迹积分
∇ θ J ( θ ) = ∫ ∇ θ p θ ( τ ) R ( τ ) d τ \nabla_\theta J(\theta) = \int \nabla_\theta p_\theta(\tau) R(\tau) d\tau ∇θJ(θ)=∫∇θpθ(τ)R(τ)dτ
2.2 对数概率技巧
利用 ∇ θ p θ ( τ ) = p θ ( τ ) ∇ θ log p θ ( τ ) \nabla_\theta p_\theta(\tau) = p_\theta(\tau) \nabla_\thet