提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 一、 数据
- 1、认识经典数据
- 1.1入门数据:MNIST、其他数字与字母识别
- (1)数据加载
- (2)查看数据的特征和标签
- 方式一:.data/.targets查看数据特征和标签
- 方式二:通过查看某一个索引值的方式来查看特征和标签
- 方式三:万能方法
- (3)数据可以化
- 方式一:PIL直接可视化
- 方式二:用一个万能公式来随机可视化五张图
- 1.2竞赛数据:ImageNet、COCO、VOC、LSUN
- 1.3景物、人脸、通用、其他
- 总结
前言
内容来源于【菜菜&九天深度学习实战课程】上班以后时间少,为了提高效率,通过抄课件的方式加深记忆,而非听课。所以所有笔记仅仅是学习工具,并非抄袭!
在传统机器学习中,通常会区分有监督、无监督、分类、回归、聚类等人物类别,在不同的任务重会指向不同形式的标签、不同的评估指标、不同的损失函数,这些内容会影响我们的训练和建模流程。在深度视觉以外,除了区分“回归、分类”之外,还需要区分众多的、视觉应用类别。如果只考虑图像的内容,至少有常见的三种任务:识别(recognition) 、检测(detection)、分割(segmentation)。
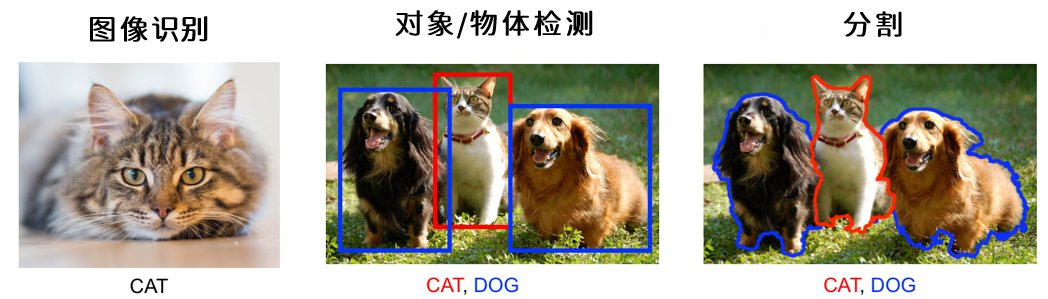
图像识别以图像中的单一对象为核心,采集信息并作出判断,任何超过单一对象的任务都不是单纯的图像识别。用于图像识别的数据集往往比较规整、比较简单,被识别物体基本轮廓完整、拍摄清晰、是图像中最容易被人眼注意到的对象。因此,图像识别适用于机场人脸识别这种简单的应用场景。
检测任务和分割任务是针对图像中多个或者单个对象进行判断的任务。因此分割和检测所使用的图像往往复杂很多。在检测任务重,首先要使用边界框(Bounding Box, bbx)对图像中的多个对象所在位置进行判断,在一个边界框容纳一个对象的前提下,再对边界框内每一个单一对象进行图像识别。因此。
检测任务的标签有两个:(1)以坐标方式确定的边界框的位置;(2)每个边界框中的物体属性。检测任务的训练流程也氛围两步:(1)定位;(2)判断。检测任务的训练数据也都是带边框的。我们可以只使用其中一个标签进行训练,但是检测任务同时训练两个标签才是最常见的情况。检测任务比较适用于大规模动态影像的识别,比如识别道路车辆、识别景区人群等。检测也是现在实际应用最为广泛的视觉任务。
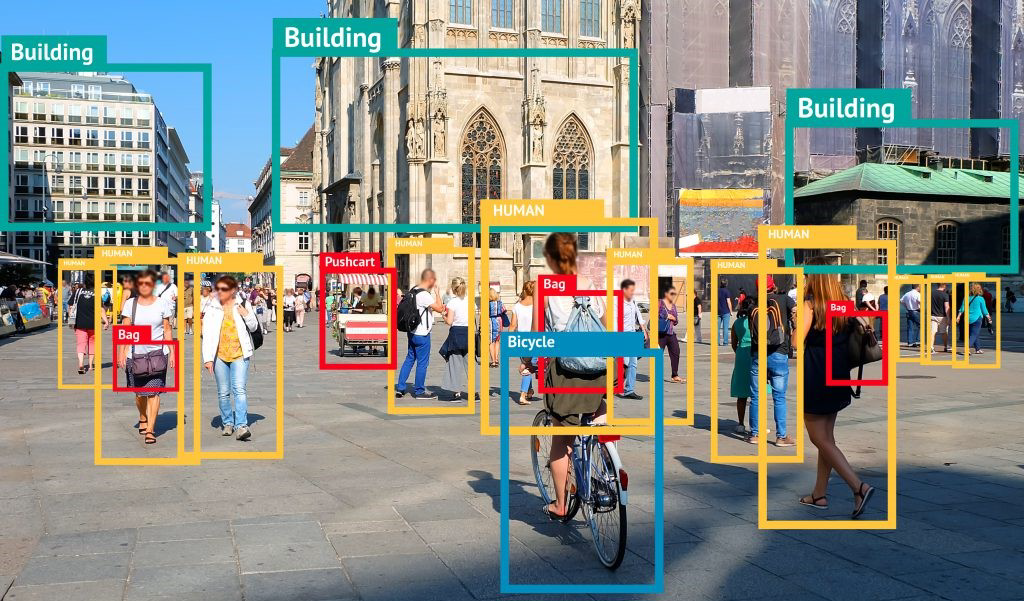
分割任务是像素级别的密集任务,需要对图像中的每个像素进行分类,因此不需要定义边界框就能够找到每个对象的“精准边界”。分割任务的标签往往只有一个,通常是对象的定义或性质(比如,这个像素是猫,这个像素是蓝天),但是标签中的类别会非常对,对于复杂的图像,标签类别可能成百上千。分割任务是现在图像领域对“理解图像”探索的前沿部分,许多具体的困难还未解决,同时,在许多实际应用场景并不需要分割任务这么”精准“的判断,因此分割的实际落地场景并不如检测来的多。比较知名的实际落地场景是美颜相机、抖音换脸特效等。
综上所述,三种任务在输出的结果及标签有所不同,但它们在一定程度上共享训练数据集,这主要是因为图像中的“对象”概念是可以人为定义的。用于图像识别的训练数据只要有适当的标签,也可以被用来检测和分割。例如,对于只有一张人脸的图像,只要训练数据存在边界框,那标签中就可以进行检测。相对的,用于检测和分割的数据如果含有大量的对象,可以被标注为“人群”这样的标签来进行识别(不过,用于检测、分割的数据拥有可以作为识别数据的标签非常少,因为检测分割数据集往往是多对象的)。

在单个任务重,也可能会遇到不同的“标签”。例如,对人脸数据,我们可以进行“属性识别”(attribute recognition)、“个体识别”(identity recognition)、“情绪识别”(emotion recognition)等不同的任务,对于同一张图像,我们的识别结果可能完全不同。

在情绪识别中,我们只拥有“情绪”这一标签,但标签类别中包含不同的情绪。在属性识别中,我们可以执行属性有限的多分类任务,也可以让每一种属性都有一个单独的标签,针对一个标签来完成二分类任务。而个体识别则是经典的人脸识别,在CelebA数据中我们使用人名作为标签来进行判断。
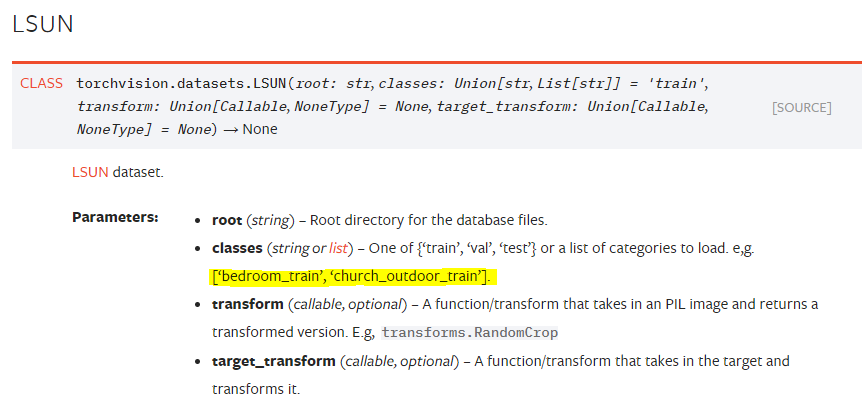
同样的,在场景识别、物体识别数据下(比如大规模场景识别数据LSUN),我们可能无法使用全部的数据集,因为全数据集可能会非常巨大并且包含许多我们不需要的信息。在这种情况下,标签可能是分层的,例如,场景可能分为室内和室外两种,而室内又分为卧式、客厅、厨房,室外则分为自然精光、教堂、其他建筑等,在这种情况下,室内和室外就是“上层标签”,具体的房间或景色则被认为是“下层标签”。我们通常会选择某个下层标签下的数据进行学习,例如:在LSUN中选择“教堂”或“卧室”标签进行学习:

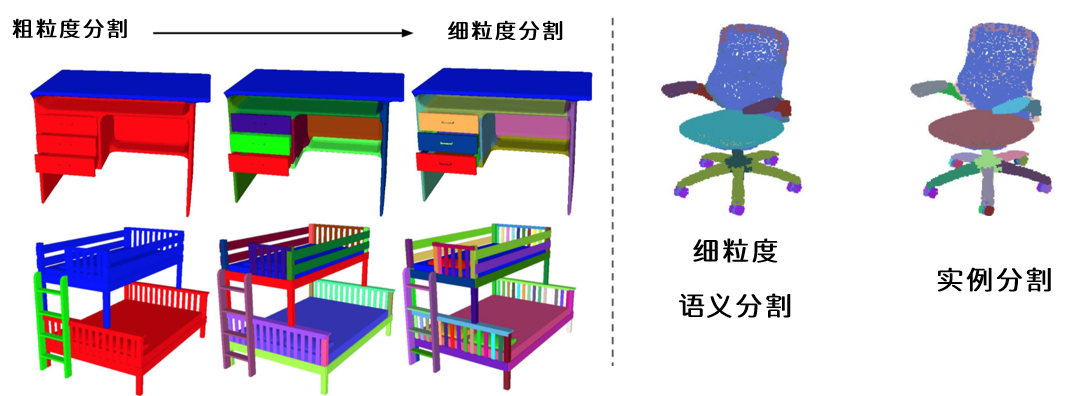
对检测任务,我们也可能会检测不同的对象,例如:检测车牌号和检测车辆就是完全不同的标签,我们也需要从可以选择的标签中进行挑选。对于分割,则有更多的选项,我们可以执行将不同性质的物体分割开来的”语义分割“,也可以执行将每个独立对象都分割开来的”实例分割“,还可以执行使用多边形或颜色进行分割的分割方法。同时,根据分割的“细致程度”,还可以分为“粗粒度分割”(Coarse)和“细粒度分割”(Fine-grained),具体的分割程度由训练图像而定。

因此,在图像数据集的读取过程中,可能会发现一个图像数据集会带有很多个指向不同任务的标签、甚至很多个不同任务的训练集。遗憾的是,数据集本身并不会说明数据集所指向的任务,因此我们必须从中辨别出自己所需要的部分。torchvision.datasets模块中自带的CelebA人脸数据集就是这种情
况。如下图所示,类datasets.CelebA下没有任何文字说明,只有一个指向数据源的链接,光看PyTorch官网,我们并不能判断这个数据集是什么样的数据集。不过,这个类由参数“target_type”,这个参数可以控制标签的类型,四种标签类型分别是属性(attr)、个体(identity)、边界框(bbox)和特征(landmarks)。根据参数说明,可以看出属性是40个二分类标签,可以从中选择一个进行分类,个体是判断这个人类是哪个具体任务,这两个标签指向的是识别任务。边界框和特征都以坐标形式表示,这两个标签都指向检测任务。

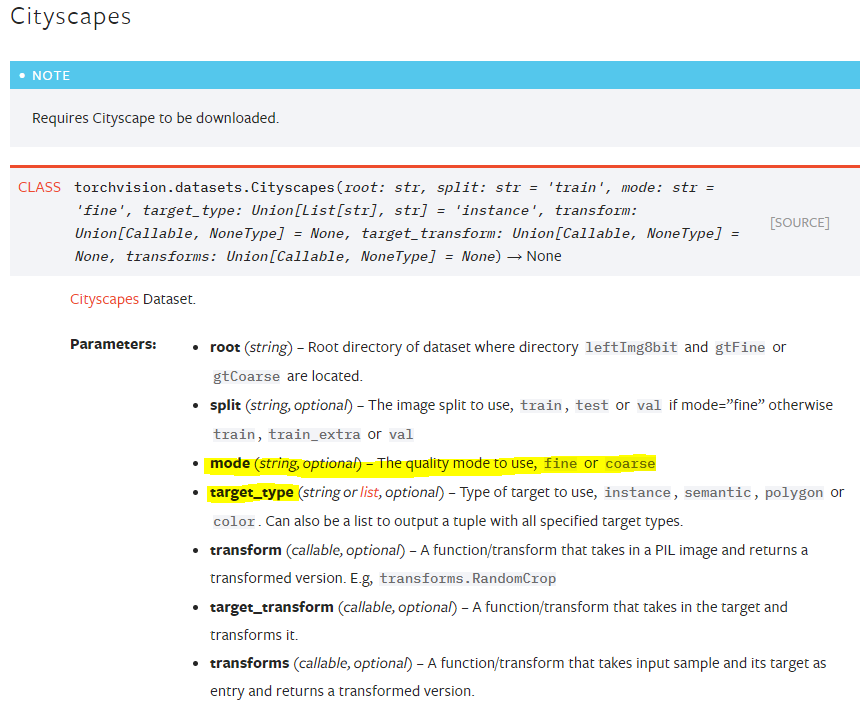
同样情况的还有Cityscapes,这个数据集的类dataset.Cityscapes下没有任何说明,但它含有参数mode和target_type,其中mode由两个模式:fine以及coarse,这两个模式表示Cityscape是一个用于分割任务额度数据集。同时,targe-type下面还有instance(实例分割)、semantic(语义分割)、polygon(多边形分割)、color(颜色分割)四种选项,所以要清晰了解自己的需求以及每种分割的含义才能正确填写这些参数。同时,我们可以一次性训练导入多个标签进行使用,如何混用这些标签来达成训练目标也成为难点之一。
再看看LSUN数据集,需要自己填写标签名称的情况:
现在我们对视觉任务有了一定了解:图像数据丰富多样,在具体任务不明确的情况下,我们连最基本的数据导入都存在问题。基于对图像任务的理解,本课内容将分为上、下两部分。上以图像识别任务为主,下以视觉任务中的其他任务为主。
一、 数据
示例:pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。
1、认识经典数据
1.1入门数据:MNIST、其他数字与字母识别
第一部分要介绍的是最适合用于教学和实验、几乎对所有的电脑都无负担的MNIST一族。MNIST一族是数据和字母识别的最基本的数据集,这些数据集户全都是小尺寸图像的简单识别,可以被轻松放入任意神经网络中进行训练。具体如下:
| 数据名称 | 数据说明 |
|---|---|
| FashionMINST | 衣物用品数据集 |
| MINST | 手写数字数据集 |
| KuzushijiMNIST | 日语手写平假名识别,包含48个平假名字符和一个平假名迭代标记,一个高度 |
| 不平衡的数据集 | |
| QMNIST | 与MNIST高度相似的手写数字数据集 |
| EMNIST | 与MNIST高度相似,在MNIST的基础上拓展的手写数字数据集 |
| Omniglot | 全语种手写字母数据集,包含来自50个不同字母的1623个不同的手写字符,专用于“一次性学习" |
| USPS | 另一个体系的手写数字数据集,常用来与MNIST对比 |
| SVHN | 实拍街景数字数据集(Street View House Number),是数字识别和检测中非常不同的一个数据集。有原始尺寸数据集可以下载,但在PyTorch中内置的是32x32的识别数据。注意,使用本数据需要SciPy模块的支持。 |

在PyTorch中,提供了三个与MNIST数据集相对比的数据集,分别是用于一次性学习的字母识别数据集Omniglot,另一个体系的手写数据集USPS,以及SVHN实拍街景数字数据集。这几个数据集与MNIST的区别如下图。

在深度视觉的研究中,我们很少专门就MNIST进行研究,但我们在这些简单识别数据集上设置了其他值得研究的问题。比如,在我们撰写论文或检验自己的架构时,MNIST一族是很好的基准线——他们尺寸很小,容易训练,很简单却又没有那么“简单”。一流的架构往往能够在MNIST数据集上取得99%以上的高分,而发表论文时,MNIST数据集的结果低于97%是不能接受的。单一机器学习算法能够在Fashion-MNIST数据集上取得的分数基本都在90%左右,而一流的深度学习架构至少需要达到95%以上的水准。再比如,我们常常使用平假名识别的数据集来研究深度学习中的样本不平衡问题,我们还使用Omniglot数据集来研究人脸识别(主要是个体识别 identity recognition)中常见的“一次性学习”问题(one-shot learning)。我们来重点讲讲这个“一次性学习”的问题。


在人脸识别中,我们有两种识别策略:
第一种策略是以人名为标签进行多分类,在训练样本中包含大量的同一个人的照片,测试集中也包含这个人的照片,看CNN能否正确预测出这个人的名字;而第二种策略则是一种二分类策略,在训练样本中给与算法两张照片,通过计算距离或计算某种相似性,来判断两张照片是否是同一个人,输出的标签为“是/否相似或一致”,在这种策略中,测试集的样本也是两张照片,并且测试集的样本不需要出现在训练集中。
如果基于第一种策略来执行人脸识别,则机场、火车站的人脸识别算法必须把全国人民的人脸数据都学习一遍才可能进行正确的判断。而在第二种策略中,算法只需要采集身份证/护照上的照片信息,再把它与摄像头中拍摄到的影像进行对比,就可以进行人脸识别了。这种“看图A,判断图B上的人是否与图A上的人是同一人”的学习方法,就叫做一次性学习,因为对于单一样本,算法仅仅见过一张图A而已。不难想象,实际落地的人脸识别项目都是基于一次性学习完成的。Omniglot数据集就是专门训练一次性学习的数据集。从上图可以看出,Omniglot数据集中的字母/符号对我们而言是完全陌生的,因此我们并无法判断出算法是否执行了正确的“识别”结果。而在Omniglot数据集上,算法是通过学习图像与图像之间的相似性来判断两个符号是否是一致的符号,至于这个符号是什么,代表什么含义,对Omniglot数据集来说并无意义。
字母和数字识别的数据集的尺寸都较小,因此PyTorch对以上每个数据集都提供了下载接口,因此我们无需自行下载数据,就可以使用torchvision.datasets.xxxx的方式来对他们进行调用。在网速没有太大问题的情况下,只要将download设置为True,并确定VPN是关闭状态,就可以顺利下载。注意:下载之后最好将download参数设置为False,否则只要调用目录写错,就会重新进行下载,费时也费流量。
(1)数据加载
方式一:通过torchvision.datasets.MNIST下载数据
import torch
import torchvision
import torch.nn as nn
import torchvision.transforms as transformstrain_data = torchvision.datasets.MNIST(root='/Users/gaoyuxing/Desktop/all_file/torchvision_dataset',train=True,transform=transforms.ToTensor(),download=True)test_data = torchvision.datasets.MNIST(root='/Users/gaoyuxing/Desktop/all_file/torchvision_dataset',train=True,transform=transforms.ToTensor(),download=True)
方式二:下载了数据存储在自己电脑上并调用:
import torchvision
import torchvision.transforms as transformsfminst = torchvision.datasets.FashionMNIST(root='/Users/gaoyuxing/Desktop/all_file/torchvision_dataset',train=True,download=False,transform=transforms.ToTensor())svhn = torchvision.datasets.SVHN(root='/Users/gaoyuxing/Desktop/all_file/torchvision_dataset/SVHN',split="train",download=False,transform=transforms.ToTensor())omniglot = torchvision.datasets.Omniglot(root='/Users/gaoyuxing/Desktop/all_file/torchvision_dataset',background=True, #在ominglot论文中,作者将训练集称为background,因此background代表训练集download=False,transform=transforms.ToTensor())print(fminst)
'''
Dataset FashionMNISTNumber of datapoints: 60000Root location: /Users/gaoyuxing/Desktop/all_file/torchvision_datasetSplit: TrainStandardTransform
Transform: ToTensor()'''
print(svhn)
'''
Dataset SVHNNumber of datapoints: 73257Root location: /Users/gaoyuxing/Desktop/all_file/torchvision_dataset/SVHNSplit: trainStandardTransform
Transform: ToTensor()
'''
print(omniglot)
'''
Dataset OmniglotNumber of datapoints: 19280Root location: /Users/gaoyuxing/Desktop/all_file/torchvision_dataset/omniglot-pyStandardTransform
'''
(2)查看数据的特征和标签
需要注意的是:由于深度视觉中的数据属性均有不同,如果简单得调用.data或者.targets很容易报错。本小结最后给出了一个万能方式。
方式一:.data/.targets查看数据特征和标签
当我们查看数据集时,只给出了Number of datapoints、Root location等,但我们想了解的是数据集的输入和标签,针对fminst来说,可以通过调.data的方式查看特征,.target的方式查看标签。
print(fminst.data)
'''
tensor([[[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],...,[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0]],[[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],...,[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0]],[[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],...,[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0]],...,[[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],...,[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0]],[[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],...,[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0]],[[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],...,[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0]]], dtype=torch.uint8)
'''
print(fminst.targets)
'''
tensor([9, 0, 0, ..., 3, 0, 5])
'''
但是并不是所有的数据集都可以通过这种方式来查阅。这是因为:当面临的任务不同时,每个数据集的标签排布方式和意义也都不同,因此不太可能使用相同的API进行调用。
for i in [fminst, svhn, omniglot]:print(i.data.shape)
'''
torch.Size([60000, 28, 28])
(73257, 3, 32, 32)
AttributeError: 'Omniglot' object has no attribute 'data'
'''for i in [fminst, svhn, omniglot]:print(i.targets.shape)
'''
tensor([9, 0, 0, ..., 3, 0, 5])
torch.Size([60000])
AttributeError: 'SVHN' object has no attribute 'targets'
'''
方式二:通过查看某一个索引值的方式来查看特征和标签
因此,我们可以看到omniglot数据并没有data和targets属性,那么我们应该如何查看omniglot数据呢?——通过索引的方式查看某一个单独的数据
#方式一:查看某一个索引的情况
print(omniglot[0])
'''
(tensor([[[1., 1., 1., ..., 1., 1., 1.],[1., 1., 1., ..., 1., 1., 1.],[1., 1., 1., ..., 1., 1., 1.],...,[1., 1., 1., ..., 1., 1., 1.],[1., 1., 1., ..., 1., 1., 1.],[1., 1., 1., ..., 1., 1., 1.]]]), 0)
'''
#由此可以看出omniglot的每个索引是一个元组#紧接着我们可以调用每个元组中的第一个切片来查看图像数据的特征和形状
print(omniglot[0][0])
'''
tensor([[[1., 1., 1., ..., 1., 1., 1.],[1., 1., 1., ..., 1., 1., 1.],[1., 1., 1., ..., 1., 1., 1.],...,[1., 1., 1., ..., 1., 1., 1.],[1., 1., 1., ..., 1., 1., 1.],[1., 1., 1., ..., 1., 1., 1.]]])
'''
print(omniglot[0][0].shape)
#torch.Size([1, 105, 105]) ,omniglot数据的图像仅有一个通道,图片的形状是105*105#查看样本量
print(len(omniglot)) #19280
方式三:万能方法
如果通过索引的方式还是报错,那就要使用报错概率最低的方式:
for i in [fminst, svhn, omniglot]:for x,y in i:print(x.shape, y)break
'''
torch.Size([1, 28, 28]) 9
torch.Size([3, 32, 32]) 1
torch.Size([1, 105, 105]) 0
'''
(3)数据可以化
方式一:PIL直接可视化
如果需要查看图片,可以通过去掉transforms.Totensor()来查看
fminst = torchvision.datasets.FashionMNIST(root='/Users/gaoyuxing/Desktop/all_file/torchvision_dataset',train=True,download=False)#transform=transforms.ToTensor())#print(fminst)
#print(fminst[0])
#(<PIL.Image.Image image mode=L size=28x28 at 0x7FB843C23BB0>, 9)
print(fminst[0][0]) #(<PIL.Image.Image image mode=L size=28x28 at 0x7FB843C23BB0>, 9)
image = fminst[0][0]
image.show()

方式二:用一个万能公式来随机可视化五张图
注意:该方法要求已经将图片转换为tensor格式,即要求含有tansform = transforms.ToTensor()
def plotsample(data):fig, axs = plt.subplots(1,5,figsize=(10,10)) #建立子图for i in range(5):num = random.randint(0,len(data)-1) #首先选取随机数,随机选取五次#抽取数据中对应的图像对象,make_grid函数可将任意格式的图像的通道数升为3,而不改变图像原始的数据#而展示图像用的imshow函数最常见的输入格式也是3通道npimg = torchvision.utils.make_grid(data[num][0]).numpy()nplabel = data[num][1] #提取标签#将图像由(3, weight, height)转化为(weight, height, 3),并放入imshow函数中读取axs[i].imshow(np.transpose(npimg, (1, 2, 0)))axs[i].set_title(nplabel) #给每个子图加上标签axs[i].axis("off") #消除每个子图的坐标轴#%%plotsample(omniglot)
plt.show()

plotsample(svhn)
plt.show()
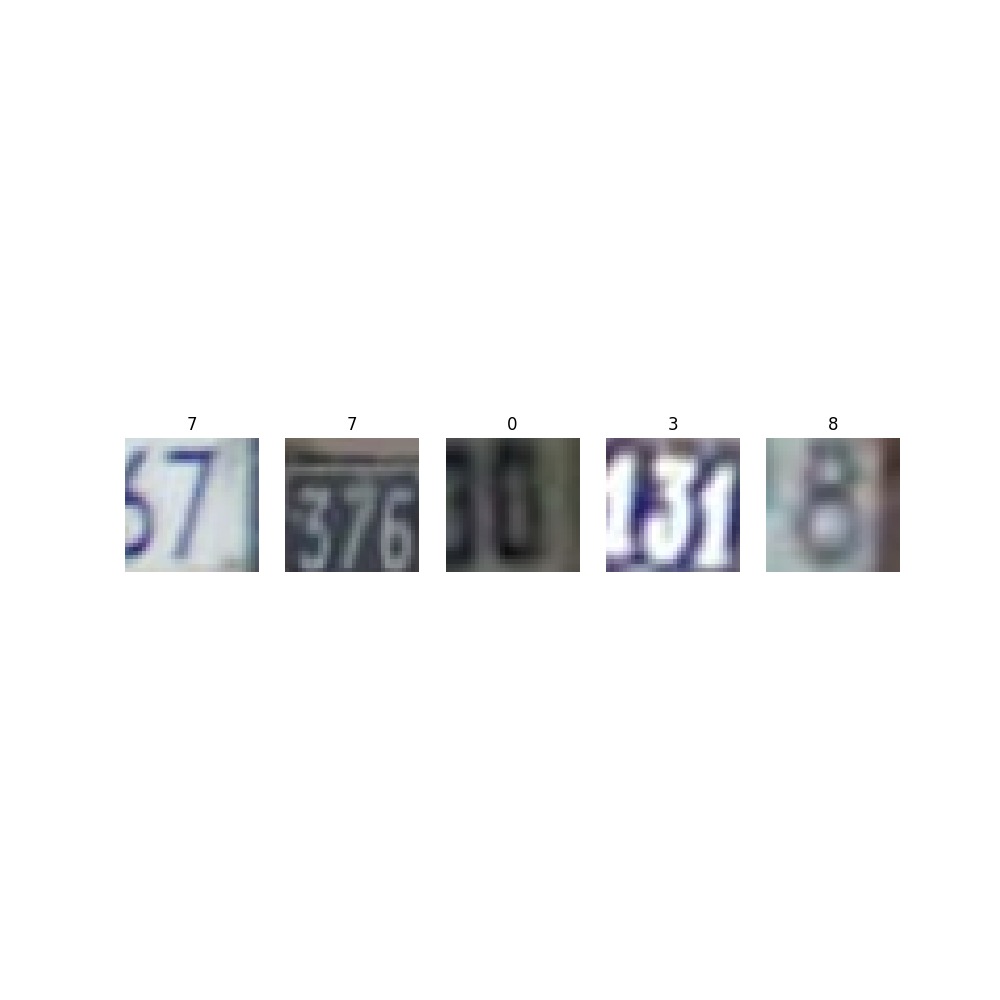
plotsample(fminst)
plt.show()

根据类的不同,参数train可能变为split,还可能增加一些其他的参数,具体可以参照datasets页面。MNIST一组的数据集户都可以被用于简单的识别项目,是测试架构的最佳数据。在提出新架构或新方法时,学者们总会在MNIST或Fashion-MNIST数据集上进行测试,并将这些数据拿到高分(>95%)作为新架构有效的证明之一。
1.2竞赛数据:ImageNet、COCO、VOC、LSUN
除了数字和字母识别以外,最熟悉且最瞩目的就是各大竞赛的主力数据。之前在讲解大规模视觉挑战赛ILSVRC的时候,介绍过ImageNet数据集,和ImageNet数据一样,竞赛数据往往诞生于顶尖大学、顶尖科研机构或大型互联网公司的人工智能实验室,属于推动整个深度学习向前发展的数据集,因此这些数据集通畅数据量巨大、涵盖类别广泛、标签异常丰富、可以被用于各类图像任务,并且每年会更新迭代,且在相关竞赛停止或关闭之后会下架数据集。作为计算机视觉的学习者,我们没有用过这些数据,但是必须要知道它们的名字和基本信息。作为计算机视觉工程师,在每个项目上线之前,都需要使用这些数据来进行测试。现在就来了解一下这些数据集吧。
| 数据名称 | 数据说明 |
|---|---|
| ImageNet2012 | ImageNet大规模视觉挑战赛(ILSVRC)在2012年所使用的比赛数据。1000分类通用数据,涵盖了动植物、人类、生活用品、食物、景色、交通工具等类别。任何互联网大厂在深度学习模型上线之前必用的数据集。2012年版本数据集由于版权原因已在全网下架,现只分享给拥有官方学术头衔的机构或个人(这意味着,在申请数据集时必须使用xxx@xxx.edu的电子邮件,任何免费的、非学术机构性质的电子邮件地址都不能获得数据申请。因此,PyTorch中的torchvision.datasets.ImageNet类已经失效。 |
| ImageNet2019 | ILSVRC在2017年之后就取消了识别任务,并将比赛赚到Kagg了上举办,现在ImageNet2019版本可以在Kaggle上免费现在,主要用于检测任务。 |
| PASCAL VOCSegmentation PASCAL VOCDetection | 模式分析,统计建模和计算机学习大赛(Pattern Analysis, Statistical Modeling and Computation Learning, PSACAL),视觉对象分类(Visual Object Classes)数据集。与ImageNet类型相似,覆盖动植物、人类、生活用品、食物、交通等类别,但数据量相对较小。在PyTorch中被分为VOCSegementation与VOCDetection两个类,分别支持分割和检测任务,虽然带有类别标签但基本不支持识别任务。同时,PyTorch支持从2007到2012年的五个版本的下载,通畅我们都是用最新版本。 |
| CocoCaptions CocoDetection | 微软Microsoft Common Objects in Context数据集,是大规模场景理解挑战赛(Large-scale Scene Understanding challenge,LSUN)中的核心数据,主要覆盖复杂的日常场景,是继ImageNet之后,最受关注的物体检测、语义分割、图像理解(Caption)方面的数据集,也是唯一关注图像理解的大规模挑战赛。其中,用于图像理解的部分是2015年之前的数据,用于检测和分割的则是2017年及之后的版本。需要安装COCO API才可以调用。PyTorch没有提供用于分割的API,但我们依然可以自己下载数据集用于分割。 |
| LSUN | 城市景观、城市建筑、人文风光数据集,包含10中场景、20中对象的大猩猩数据集。其中,场景图像被用于LSUN大规模题场景理解挑战赛。20分类包含交通工具、动物、人类等图像,可用于识别任务。在我们导入数据时,我们会选择LSUN中的某一个场景或对象进行训练,因此个人给予LSUN进行的识别任务是二分类的。 |
1.3景物、人脸、通用、其他
17.3.2将二维表及其他结构转换为四维tensor
要点1:多项式升维:from sklearn.preprocessing import PolynomialFeatures as PF. 在多项式升维中,维度指的是特征维度,而非张量的维度。
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。