近四年中,学者们在计算机视觉(CV)、自然语言处理(NLP)、图神经网络(GNN)、强化学习(RL)以及多模态领域探索了在训练阶段融入可解释性机制以提升模型鲁棒性的方法。
一、显著图指导训练提高模型稳健性(Ismail et al., NeurIPS 2021)
[2111.14338] Improving Deep Learning Interpretability by Saliency Guided Training Improving Deep Learning Interpretability by Saliency Guided Training[2111.14338] Improving Deep Learning Interpretability by Saliency Guided Training
通过在训练中引入梯度显著性图的反馈来提升模型鲁棒性。具体来说,在每次迭代中他们屏蔽掉
梯度较小(不重要)的特征,并强制模型对屏蔽前后输入给出相似的输出,从而减少模型预测中由噪声梯度引起的不稳定因素。这种训练过程可被视为一种解释约束:显著图标识出模型判别依据的重要区域,训练时通过掩蔽和一致性约束,引导模型聚焦于真正重要的特征。
该方法主要提升了模型对噪声和无关特征扰动的鲁棒性。通过抑制梯度噪声,模型的特征归因更稳定可靠,降低了对偶然噪声模式的依赖。作者在图像、文本和时间序列数据集上的实验表明,该训练策略在保持原有预测性能的同时显著提高了模型解释性。由于模型更关注核心特征,有理由推测对输入噪声扰动的抵抗力也有所增强,提升了模型的稳健性。
1.研究问题
深度神经网络(DNNs)虽然在图像识别、自然语言处理、时间序列预测等任务中取得了巨大成功,但其“黑箱性”严重制约了其在高风险场景中的应用,比如医疗、金融、自动驾驶等。
目前解释神经网络的一种主流方式是梯度显著图(saliency map),即通过计算模型输出对输入的梯度来判断哪些特征对预测最关键。然而,这些显著图存在两个核心问题:
-
噪声严重:梯度往往非常不稳定,对输入的微小扰动就会产生剧烈变化,导致显著图上许多区域看似重要,其实毫无意义。
-
不忠实(Unfaithful):显著图无法真正反映模型做出预测时依赖的真实特征,有时甚至误导解释。
所以,本研究的核心问题是:如何从训练阶段就引导模型生成更稀疏、稳定、忠实的梯度,从而改善解释质量,同时又不损失模型预测性能?
2.相关工作
为了让神经网络“可解释”,大量研究聚焦于“后处理”(post-hoc)解释方法。主要可分为两类:
-
基于梯度的显著图方法:
-
直接计算输出对输入的梯度(Gradient);
-
平滑梯度:SmoothGrad【给输入加入噪声后平均梯度】;
-
积分梯度(Integrated Gradients):从参考点积分到真实输入;
-
DeepLIFT、Layer-wise Relevance Propagation:利用参考激活来传播重要性;
-
Gradient SHAP:用 SHAP 方法估计边际贡献。
-
-
基于扰动的解释方法:
-
通过移除或遮挡输入的某些部分,然后观察模型预测的变化,比如 LIME、RISE 等。
-
尽管这些方法广泛应用,但都基于“已训练好”的模型,解释过程并不影响训练过程。
而目前的工作中,主要是下面几种处理方式:
1. 后处理解释方法(Post-hoc Explanations)
-
典型代表如:Gradient、IG、DeepLIFT、SmoothGrad、Gradient SHAP 等。
-
面临的问题是:显著图中往往包含大量无意义的“视觉噪声”,即对解释没有帮助的梯度值。
2. 用解释改进训练(Explanation-Guided Learning)
-
如 Ross et al. 提出“Right for the right reason”:将人类标注的解释信息作为监督信号,加入训练目标,引导模型在“正确区域”做决策。
-
局限:需要额外解释数据(ground-truth rationales),在实际应用中很难获取。
3. 输入扰动训练策略
-
如 CutOut、Hide-and-Seek 等方法通过训练时遮挡输入图像局部区域来增强模型鲁棒性,但目标并非改善解释。
-
Wang et al. 尝试在训练时引入注意力分布增强性能。
-
上述方法均未将解释性作为训练目标本身。
3. 解决方案
这篇论文提出了一种全新的训练机制,称为:Saliency Guided Training(显著性引导训练),是一个与模型架构和具体解释方法无关的通用训练框架。
3.1 问题定义

传统神经网络的训练方式,没有任何解释性机制,也不涉及显著性(saliency)处理。
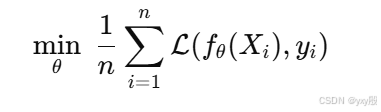

而文章解释性的基础就在于梯度:

那么根据梯度,作者设计了排序函数:

因此又设计了一个函数叫做遮蔽函数:

在 NLP 任务中,输入不是单一向量,而是词嵌入序列,每个词 xi∈Rd;排序方式是:将每个词的嵌入向量中每个维度的梯度求和,得到该词的总显著性;然后取显著性最小的 k个词进行遮蔽。
-
对于时间序列任务,输入是一个二维矩阵(时间步数 × 特征维度);
-
每个时刻 t 有 F个特征 xi,t;
-
显著性分析和遮蔽操作都针对 xi,t 单元进行。
接着使用KL散度:
3.2 解决方案
现有的基于梯度的显著图方法会产生大量噪声。这种噪声部分原因可能是由于偏导数中存在非信息性的局部波动。梯度本质上是局部导数,对输入中的微小扰动极其敏感;种“噪声”会误导用户对模型预测依据的理解。

目前ERM 是大多数深度学习训练的核心框架,但是它优化的是输出性能(准确率),并不在意梯度是否稳定或可解释;这就导致梯度(即显著图)非常不可靠,不能作为解释工具。如果基于梯度的解释方法能忠实地解释模型预测结果,那么那些与预测无关的特征,其梯度值应接近于零。
基于上述直觉,我们提出了“显著性引导训练”机制。
首先先进行训练。
--------------------------------------------------------------------------------------------------------------------------------
接着,对于每一个输入 X,我们通过遮蔽掉梯度值低的特征来构造一个新的输入 Xe:
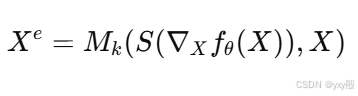

类似于就是把那些低特征的地方直接替换成无意义干扰(例如随机颜色、前面高显著词等)。
--------------------------------------------------------------------------------------------------------------------------------
然后,将 Xe输入模型,得到新的预测 fθ(Xe)。
接着将新的越策结果和之前的预测结果进行比对,这里使用了KL散度的方法。KL散度天然适合衡量两个“概率分布”之间的差异,尤其是在分类任务中(Softmax输出),是最合适不过的度量方式。
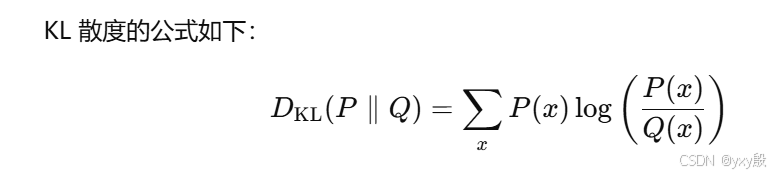
KL 散度是一个有方向性的失望指数,用来衡量两个概率分布的差异。
为什么使用KL散度呢?
(1)非常适合 softmax 输出的“概率分布”
神经网络最后一层分类输出是 softmax,输出是一个概率分布:
猫:0.7 狗:0.2 鸟:0.1
KL 是专门设计来比较两个“分布”的,正好拿来对比:
遮蔽前你说是猫的概率 0.7;
遮蔽后你说是猫的概率变成 0.4;
KL 就会狠狠罚你:“你怎么改口啦?”
而像 MSE 是比较“数值大小”,不能体现出“语义变化”
(2)不对称,符合训练逻辑

除了分类损失外,显著性引导训练还最小化原始输入fθ(X)和遮蔽输入fθ(Xe)的KL散度。

因此完整优化目标如下:
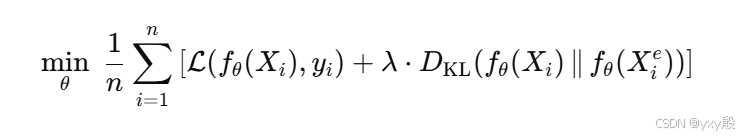

-
如果遮蔽了“无用”的特征,模型预测不应改变;
-
因此训练目标就会鼓励模型降低这些特征的梯度值;
-
久而久之,模型自然会让无关特征的 saliency ≈ 0,从而提升解释图的忠实性。
在图像和时间序列中,梯度低的特征会被其特征值范围内的随机值替换。而在语言任务中,低显著词会被替换为前一个高显著词。
-
目的是保留输入结构(如句子长度);
-
遮蔽不代表“删除”,而是用“更有意义的内容”覆盖;
-
这种替换使得模型不会因格式突变而预测失真。
至于 要“遮蔽掉”的输入特征数量K,选择依赖于具体的数据集。例如,MNIST 中大部分像素是背景,因此适合选择较大的 k。不过仅在训练过程中对输入特征进行遮蔽,测试时不遮蔽。与传统训练相比,该方法计算开销更大。因为除了原始 batch,还需要存储遮蔽后的 batch,显著增加了内存需求。
如果要解释他的算法:




输入 X
↓
计算 ∇X fθ(X)
↓
排序梯度值 → 找到最小的 k 个特征
↓
遮蔽这些特征 → 得到 X̃
↓
两次 forward:
fθ(X) 和 fθ(X̃)
↓
计算损失:
交叉熵 + λ × KL(fθ(X) || fθ(X̃))
↓
反向传播,更新模型参数
二、边界框注释指导视觉模型抗偏见(Rao et al., ICCV 2023)
本文提出了一种 使用边界框注释来引导视觉模型减少社会偏见(如性别偏见) 的新方法。该方法在不影响模型主任务性能的前提下,显著减少了模型对偏见属性(如性别)的依赖,从而提高了模型的公平性与可解释性。
1.研究问题
近年来,视觉模型(如图像分类和图文匹配模型)已被广泛部署于实际应用中,但研究发现,这些模型常常学习到 不公平的社会偏见(如性别偏见),尤其当训练数据存在统计偏差时。为了实现公平的模型预测行为,亟需设计有效的偏见缓解策略。然而,当前方法大多存在以下问题:
-
依赖于目标属性标签(如性别),而这些标签在现实中往往不可用。
-
牺牲主任务性能,即缓解偏见的同时模型准确性下降。
-
不具备可解释性,无法说明缓解偏见的机制。
本文旨在通过一种新的监督方式 —— 边界框注释(bounding box) 来解决上述问题。
2.相关工作
目前的相关工作有以下缺陷:
-
公平性与偏见缓解:包括基于目标属性标签的再加权、对抗训练等方法。
-
辅助监督策略:如注意力监督、分割图监督,但这些方式通常较为复杂且在不同任务中适应性不佳。
-
视觉可解释性与因果推理:通过解释模型关注区域与输出之间的因果关系,分析模型偏差来源。
因此文章提出了边界框注释:
-
无需目标属性标签(如性别):利用边界框作为间接监督信号,绕过对敏感属性的显式依赖。
-
任务无关性强:该方法可广泛应用于图像分类、图文匹配等多种任务。
-
性能与公平性兼得:不仅降低了偏见,还维持甚至提升了主任务性能。
-
实现因果可解释性:通过遮蔽实验(masking)验证模型在偏见区域的关注变化,展示了方法的可解释能力。
3.解决方案
FairBox 是一种利用边界框注释引导模型注意偏见区域,从而缓解偏见的方法。其目标是:不依赖敏感属性标签(如性别),而是通过区域监督让模型少依赖潜在偏见区域(如背景或特定物品),提升公平性。
边界框注释是什么?
在计算机视觉任务中,边界框(bounding box)就是一种标注方式,用一个矩形框圈出图像中某个对象的位置。例如,在图像中的人、车、动物等,每个对象都会用一个矩形框标记出来,告诉模型“这里是我需要关注的区域”。
举个例子:假设我们给模型一张照片,照片里有一个人站在街上。为了告诉模型这个人是我们感兴趣的对象,我们会用边界框圈出这个人,而不是其他的背景或物体。
FairBox 构建在一个双分支结构之上,分别处理:
-
主任务(Primary Task):如图像分类、图文匹配;
-
区域监督任务(Bias Mitigation Task):借助边界框,引导模型“关注人”而非“背景/暗示性区域”。
每个训练样本包含:
-
图像输入 I;
-
标签 y;
-
对应的边界框区域(bounding box) B。
FairBox 如何工作?
FairBox 主要通过两方面来帮助模型减少偏见:
让模型关注目标区域:比如,在图像分类任务中,模型可能会学到一些不公平的特征(例如背景的颜色、物体的位置等),这些特征可能与性别或其他偏见相关。FairBox 的关键思想是通过边界框来引导模型只关注人或物体本身,而不是背景或其他无关区域。这就像是告诉模型:“你看到的这个人是重点,背景不重要。”
减少模型对偏见区域的依赖:在训练过程中,FairBox 会通过一种叫做 区域对比损失(Region Contrastive Loss, RCL) 的方法来训练模型。这个损失的作用是:
增加模型对目标区域的关注(比如“人”);
减少模型对背景区域的依赖(比如不小心学习到的性别偏见)。
3.1 区域感知特征提取(Region Feature Extraction)
-
将输入图像 I 输入视觉模型(如 ResNet 或 CLIP)得到中间特征图 F;
-
使用边界框掩码提取出:
-
目标区域特征
:边界框内;
-
背景区域特征
:边界框外。
-
通过掩码操作分离关注区域与非关注区域。
FairBox 方法会使用 边界框 注释来区分图像中的“目标区域”和“背景区域”。边界框就是矩形框,通常用来标记图像中感兴趣的区域(如人、物体等)。这一步的目的是将图像的 中间特征图 FFF 分割成目标区域特征和背景区域特征。
目标区域特征:是指位于边界框内的区域。我们假设目标区域是我们真正感兴趣的部分(比如图像中的一个人),这些区域的信息对任务(比如分类或检测)是有意义的。
掩码操作:掩码操作就是使用一个 二进制掩码(比如用0和1表示),把图像中 边界框内的区域 提取出来,保留其特征。
比如,假设图像中的“人”被边界框框住,那么就提取边界框内“人”这一部分的特征。
背景区域特征:是指图像中不在边界框内的区域。通常,这部分内容不直接影响模型的判断,或者包含一些无关的背景信息。比如,一个背景可能包含一些不希望模型关注的属性(如背景的颜色、纹理等),这些可能会引入偏见。
背景掩码:同样使用一个掩码来提取不在边界框内的部分特征。
3.2 区域对比损失(Region Contrastive Loss, RCL)
FairBox 使用一种专门设计的对比损失,目的是:
-
增强模型对边界框区域的判别能力;
-
抑制模型对非目标区域的依赖。
具体如下:
(1)正例对(positive pair):
-
同一图像内的边界框区域特征
(2)负例对(negative pair):
-
同一图像内的非边界框区域特征

损失形式使用 InfoNCE(或类Triplet)的对比损失:
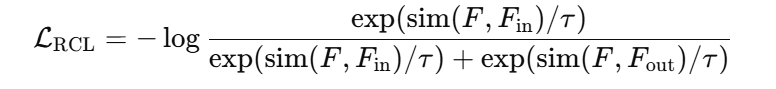
其中:
-
sim(a,b)表示相似度函数(如余弦相似度);
-
τ 是温度系数。
此损失鼓励模型更“信任”边界框区域,而“忽略”边界框外部区域的潜在偏见信息。
举个例子:
假设我们有以下图像输入:
图像内容:一个穿着蓝色外套的男性坐在公园长椅上。
我们的任务是通过模型判断这个人是男性还是女性。
步骤 1:边界框注释
我们为图像中的“人”加上 边界框,这个框只圈住 坐在长椅上的人,不包括背景。
目标区域是“人”,背景区域是公园草地和长椅。
步骤 2:区域特征提取
将图像输入模型,提取出 目标区域(人的部分)和 背景区域(草地、长椅)的特征。
步骤 3:区域对比损失计算
正例对:将 目标区域特征(人) 和 整张图像特征 进行对比,确保它们的相似度较高(模型应该关注“人”)。
负例对:将 背景区域特征 和 整张图像特征 进行对比,确保它们的相似度较低(模型不应受到背景的影响)。
步骤 4:训练
通过对比损失,模型会学会 专注于目标区域,忽略背景,从而减少性别或其他偏见信息的干扰。
步骤 5:预测
模型基于目标区域(人的部分)做出预测,不被背景中的草地、长椅或其他无关特征影响,提供更公平、无偏的性别分类结果。
TIP: FairBox 方法确实需要一定程度的人为干预,需要提供边界框注释(Bounding Box Annotations)。
三、Supervising Model Attention with Human Explanations for Robust Natural Language Inference
Supervising Model Attention with Human Explanations for Robust Natural Language Inference https://cdn.aaai.org/ojs/21386/21386-13-25399-1-2-20220628.pdf#:~:text=to%20learn%20features%20that%20will,model%20indi%02cates%20that%20human%20explanations
https://cdn.aaai.org/ojs/21386/21386-13-25399-1-2-20220628.pdf#:~:text=to%20learn%20features%20that%20will,model%20indi%02cates%20that%20human%20explanations
自然语言推理(NLI)模型已知会从训练数据中的偏差和伪影中学习,这会影响模型对其他未见过的数据集的泛化能力。现有的去偏方法侧重于防止模型学习这些偏差,但这可能导致模型过于受限,性能下降。我们则探讨了教会模型如何像人类一样处理NLI任务,从而学习到能够更好地泛化到未见过的示例的特征。通过自然语言解释,我们对模型的注意力权重进行监督,鼓励模型更多关注解释中出现的单词,从而显著提高了模型的性能。我们的实验表明,这种方法在分布内的改进也伴随着分布外的改进,经过监督的模型能够从那些能更好泛化到其他NLI数据集的特征中学习。对模型的分析表明,人类解释促使模型将更多注意力集中在重要单词上,特别是对前提中的单词给予更多关注,而对标点符号和停用词的关注减少。
1.研究背景
NLI 是自然语言处理中的一个核心任务,要求模型判断两个句子之间的逻辑关系:
-
前提(Premise):原始陈述;
-
假设(Hypothesis):待判断的句子;
-
目标:判断假设是否是前提的蕴含(Entailment)、矛盾(Contradiction),或中立(Neutral)。
尽管近年来如 BERT、RoBERTa、DeBERTa 等预训练语言模型在 NLI 上表现优异,但它们的推理方式存在严重缺陷。
(1)伪特征学习
很多NLI模型不是“真正理解”了语义,而是学会了“投机取巧”的规则:比如,模型可能只关注假设中的某些关键词,如“always”、“nobody”,因为这些词在训练集中往往与“矛盾”标签共现频繁。
(2)数据集偏差(Dataset Bias)
-
Gururangan et al. (2018) 提出“Hypothesis-only Bias”:即模型仅依靠假设句本身,就能做出预测,不再需要阅读前提;
-
Poliak et al. (2018) 表明,多数主流NLI数据集(如SNLI、MNLI)中存在显著的标注偏差,使得模型泛化能力大大下降。
(3)泛化能力弱(Out-of-distribution Generalization)
训练好的模型虽然在原始测试集上表现很好,但在其他分布的数据(如SNLI-Hard、HANS、ANLI)上性能严重下滑。
因此,本文作者提出,与其强制模型不去学伪特征,不如引导模型去学人类认为重要的特征。人类在做NLI时,会根据语义、逻辑关系、主谓宾结构等进行综合判断,而不是依赖某些关键词。因此,如果我们能够:
✅ 利用 e-SNLI 中的人类解释(如“a dog cannot be sleeping while he swims”)
✅ 来监督模型“关注”的内容(即 attention 权重)
✅ 让模型“看”和“人类解释”的词重合度更高
那么,模型可能会学到更可靠的决策模式。
这也回应了近年来“可解释人工智能(XAI)”中提到的关键议题:让模型不仅做得对,还要做得对的有道理。
2.相关工作
论文指出了之前利用人类解释训练 NLI 模型的尝试,但收效甚微:
-
Camburu et al.(2018)提出了 e-SNLI 数据集,并尝试用“解释再预测”策略,但在 MNLI 上提升有限;
-
Hase & Bansal(2021)指出解释数据集往往不满足“高相关性”等要求,因此直接使用反而会误导模型;
-
Zhao & Vydiswaran(2021)使用多阶段管线(RoBERTa + GPT2)生成类特定解释,提升了准确率,但训练成本高、泛化能力差。
这些方法在方法复杂性、可扩展性和实际效果方面都存在问题。
3.解决方案
3.1 注意力机制
在 e-SNLI 数据集(基于 SNLI 数据集构建)中,每个 NLI 样本都附有由人类标注员提供的解释。这些解释主要有两种形式,一个是自由文本解释(标注员用自然语言说明为什么前提和假设之间存在某种关系,例如“一个狗不可能在游泳的同时睡觉”),还有一个是高亮词解释(标注员直接在前提和假设中高亮出他们认为重要的单词或短语,这些词与推理的结论紧密相关)。
为了让模型在训练时能够理解这些“人类解释”,我们将每个词(token)是否被标注为重要构造成一个标签向量 ,其中每个 ei的值为 0 或 1,表示第 i 个 token 是否在解释中被认为是“重要”的。如果 token 出现在自由文本解释或被标注为高亮词,则该 token 的对应 ei=1,否则为 0。对于自由文本解释,停用词会被排除,而高亮解释中的停用词依然会被保留。
这个标签向量 E 作为监督信号用于指导模型的训练,帮助模型学习哪些词是做出推理决策时应当关注的关键元素。
接下来,我们利用标签向量 E 来生成模型的“目标注意力分布” 。注意力分布的生成过程是通过归一化 E 向量来实现的。具体来说,目标分布 D 的每个元素 di 的值为:
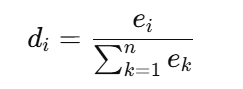
这个过程的关键在于将 ei转换为注意力分布,使得所有值加和为 1。目标分布 D就是一个标准化的向量,表示哪些词应该在模型的注意力机制中占据更多的权重。在训练过程中,我们希望模型的注意力权重 (即模型对每个 token 的注意力)能够尽量接近这些目标分布。
这个目标分布 D 会作为监督信号,特别是对于 [CLS] token(即模型用来进行最终分类的标记),在训练时引导模型将注意力更多地集中在与推理相关的词汇上。
而在 Transformer 模型中,注意力机制是通过一系列 注意力头 来实现的。在每一层,自注意力模块都会生成多个不同的注意力头。每个注意力头关注输入的不同方面(例如,词与词之间的关系、句子内部的语法结构等)。为了确保模型的注意力分布符合我们所期望的目标,我们在 Transformer 的最后一层,选择若干个(例如 3 个)注意力头,计算它们的注意力输出。然后通过**均方误差(MSE)**损失函数,监督这些注意力头的输出,使其与目标注意力分布 D 接近。
这个步骤的目的是使得模型的每个注意力头都能够关注到人类认为重要的词汇,并在学习过程中逐渐调整注意力分布,直到与人类的思维方式一致。
在训练过程中,模型的损失函数包含了两个部分:
-
主任务损失(NLI Loss):这是标准的交叉熵损失,计算模型在进行NLI任务时(判断前提和假设之间的关系)与真实标签之间的误差。
-
注意力监督损失(Attention Supervision Loss):这是基于 MSE 损失,用于确保模型的注意力分布h 与目标分布 D 接近,指导模型关注人类标注者认为重要的词汇。
因此,最终的总损失函数为:
其中,H 是被监督的注意力头数,λ 是用于调整两个损失项相对权重的超参数。通过这种方式,训练不仅是基于推理任务的准确性,还引入了人类的推理模式,指导模型的注意力机制更符合人类推理的思维方式。
重要的一点是,尽管在训练过程中使用了人类解释来监督模型的注意力分布,在测试阶段,模型依然只会接收到前提和假设,没有任何解释数据。模型仅凭前提和假设的内容进行推理,这意味着训练过程的监督信号不会影响到实际推理的流程。
这种做法确保了模型的实际应用能力,即它能够在没有外部解释的情况下进行推理。这也使得该方法具有良好的部署能力,能够在真实的推理任务中,无需额外的人工解释数据支持。
四、RES: A Robust Framework for Guiding Visual Explanation((KDD '22), August 14-18, 2022, Washington, DC, USA)
本篇论文提出了一种新的框架——RES (Robust Explanation Supervision),用于引导深度神经网络(DNN)的可解释性。该框架通过处理和优化人类注释标签的噪声、边界不准确和数据分布不一致等问题,改善了模型的可解释性并提升了任务性能。通过在两个实际的图像数据集上的实验,验证了该框架的有效性,并展示了它在提升解释合理性和增强模型性能方面的作用。
1.研究背景
随着深度学习的普及,可解释性人工智能(XAI)成为了一个重要的研究领域。尽管许多方法已被提出用于生成模型的局部解释,但关于解释的质量、准确性以及如何改进解释生成过程的研究仍然相对欠缺。此外,针对视觉数据的解释监督,尤其是在图像分类任务中,面临着上述挑战。已有的解释监督方法通常假设人类注释是准确的,但实际情况中,人类注释往往存在不准确和不完整的情况。
文章聚焦于当前可解释性技术中的几个核心挑战,尤其是在视觉任务中应用深度神经网络时的解释监督问题。主要研究问题包括:
-
人类注释的边界不准确性:如何处理模型解释中存在的边界问题?
-
人类注释的区域不完整性:如何处理注释区域的缺失?
-
人类注释与模型解释分布不一致:如何调和人类注释与模型生成的解释之间的差异?
2.相关工作
论文回顾了现有的几种局部解释技术,如Class Activation Mapping (CAM)、Grad-CAM、Layer-wise Relevance Propagation (LRP)等,并指出了这些方法在处理图像数据时存在的挑战。同时,还讨论了几种现有的解释监督方法,如GRADIA和HAICS,这些方法虽然通过额外的人工标注来改进模型解释,但在面对噪声注释时表现较差。相比之下,RES框架通过处理这些噪声注释和解释中的不一致性,能够更有效地提升模型的可解释性和性能。
文章的创新点在于:
-
引入了RES框架:该框架通过新颖的目标函数来处理噪声人类注释标签,从而提升模型的可解释性。
-
鲁棒性解释监督:论文提出的损失函数能够应对注释边界不准确、区域不完整等问题,从理论上证明了该方法对模型泛化能力的提升。
-
实验验证:通过大量实验,展示了RES框架在不同数据集和任务中的有效性,尤其是在性别分类和场景识别任务中,RES框架能够有效提升模型性能和解释质量。
3.解决方案
作者的核心思路就是在充分考虑人类标注“噪声性”的基础上,引导模型“近似”而非“完全”匹配注释标签,并在训练过程中保持一定的灵活度,以增强鲁棒性和泛化能力。
RES整个训练目标是由两部分组成的:

作者通过引入鲁棒的解释损失(Robust Explanation Loss),将解释质量作为监督信号引入训练过程,从而迫使模型在学习过程中关注那些“被人类认为重要”的区域,而不是仅依赖于容易过拟合的模式或噪声。



作者还从理论上证明了该损失对模型泛化能力有帮助:
-
推导了泛化误差上界
-
表明:在引入解释监督后,模型参数在多样样本分布下的表现更稳定。