一、原理
逻辑回归是一种用于解决二分类问题的机器学习算法。其原理基于线性回归 模型,通过使用逻辑函数(也称为sigmoid函数)将线性回归的结果映射到 一个0到1之间的概率值,从而进行分类。

在实际生活中,通常一件事的结果往往有很多个影响因素,影响因素的不同 会导致该事件会走向不同的结果。比如我们以人的饱腹感和食物的多少为 例,假如吃的全是馒头,那么人吃饱与否除了与馒头的数量有关,还与馒头 的大小有关。
二、Sigmoid激活函数
主要用于二分类问题的输出层,或早期神经网络中的隐藏层。
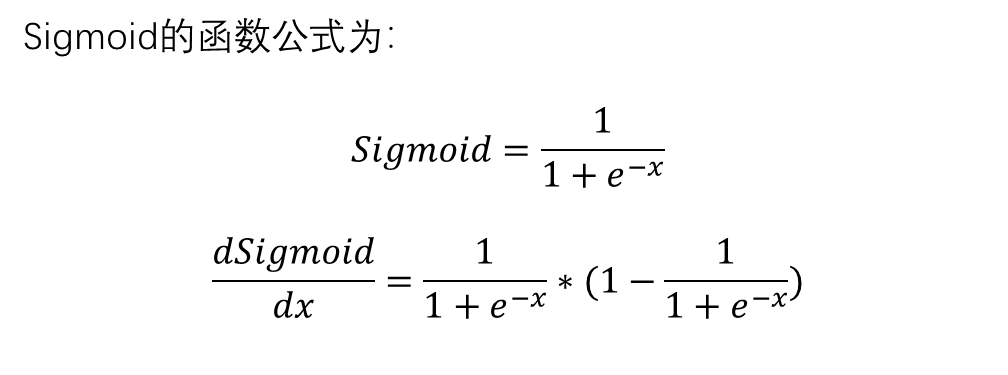
特点:
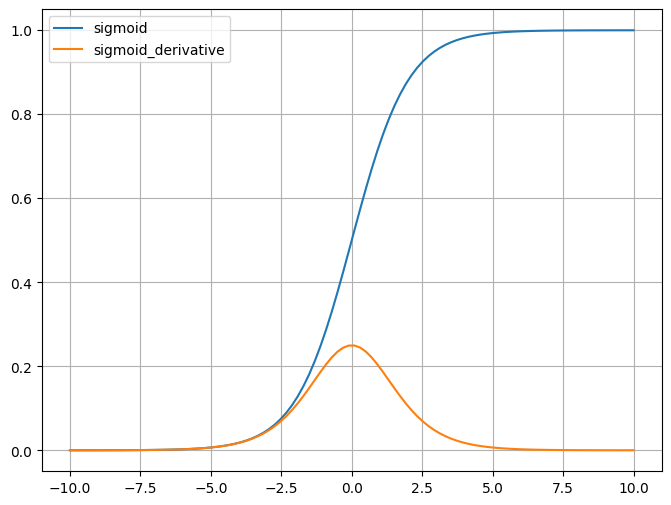
Sigmoid 函数的输出范围被限制在 0 到 1 之间,这使得它适用于需要将输 出解释为概率或者介于 0 和 1 之间的 任何其他值的场景。 Sigmoid 函数的两端,导数的值非常 接近于零,这会导致在反向传播过程 中梯度消失的问题,特别是在深层神 经网络中。
Sigmoid激活函数有着如下几种缺点:
梯度消失:Sigmoid函数趋近0和1的时候变化率会变得平坦,从导数图像可以看出,当x值趋向两 侧时,其导数趋近于0,在反向传播时,使得神经网络在更新参数时几乎无法学习到低层的特征, 从而导致训练变得困难。
不以零为中心:Sigmoid函数的输出范围是0到1之间,它的输出不是以零为中心的,会导致其参数 只能同时向同一个方向更新,当有两个参数需要朝相反的方向更新时,该激活函数会使模型的收敛 速度大大的降低。 在 Sigmoid 函数中,输出值恒为正。这也就是说,如果上一级神经元采用 Sigmoid 函数作为激 活函数,那么我们无法做到此层的输入 和 符号相反。此时,模型为了收敛,不得不向逆风 前行的风助力帆船一样,走 Z 字形逼近最优解。 模型参数走绿色箭头能够最快收敛,但由于输入值的符号总是为正,所以模型参数可能走类似红色 折线的箭头。如此一来,使用 Sigmoid 函数作为激活函数的神经网络,收敛速度就会慢上不少了。
计算成本高:Sigmoid激活函数引入了exp()函数,导致其计算成本相对较高,尤其在大规模的深度 神经网络中,可能会导致训练速度变慢。
不是稀疏激活:Sigmoid函数的输出范围是连续的,并且不会将输入变为稀疏的激活状态。在某些 情况下,稀疏激活可以提高模型的泛化能力和学习效率。
三、损失函数
选用交叉熵损失函数作为损失函数。因为交叉熵比均方差更适合分类问题,而均方差比交叉熵更适合回归问题。

四、反向传播

五、设计思路
5.1、散点输入
import numpy as npclass1_points = np.array([[1.9, 1.2],[1.5, 2.1],[1.9, 0.5],[1.5, 0.9],[0.9, 1.2],[1.1, 1.7],[1.4, 1.1]])class2_points = np.array([[3.2, 3.2],[3.7, 2.9],[3.2, 2.6],[1.7, 3.3],[3.4, 2.6],[4.1, 2.3],[3.0, 2.9]])
x1_data = np.concatenate((class1_points[:, 0], class2_points[:, 0]))
x2_data = np.concatenate((class1_points[:, 1], class2_points[:, 1]))
label = np.concatenate((np.zeros(len(class1_points)), np.ones(len(class2_points))))
5.2、前向计算
def forward(w1,w2,b):z=w1*x1_data+w2*x2_data+ba=sigmoid(z)return a5.3、sigmoid函数
def sigmoid(x):return 1/(1+np.exp(-x))5.4、参数初始化
w1=0.1
w2=0.1
b=0
lr=0.055.5、损失函数
def loss_func(a):loss=-np.mean(label*np.log(a)+(1-label)*np.log(1-a))return loss5.6、开始选代
for epoch in range(1,1001):a=forward(w1,w2,b)deda=(a-label)/(a*(1-a))dadz=a*(1-a)dzdw1=x1_datadzdw2=x2_datadzdb=1gradient_w1 = np.dot(dzdw1, (deda * dadz)) / len(x1_data)gradient_w2 = np.dot(dzdw2, (deda * dadz)) / len(x2_data)gradient_b = (deda * dadz * dzdb).sum() / len(x1_data)w1 -= lr * gradient_w1w2 -= lr * gradient_w2b -= lr * gradient_bif epoch%100==0 or epoch==1:a=forward(w1,w2,b)loss=loss_func(a)print(epoch,loss)5.7、可视化
from matplotlib import pyplot as plt
fig, (ax1, ax2) = plt.subplots(2, 1)
epoch_list = []
loss_list = []
for epoch in range(1,1001):a=forward(w1,w2,b)deda=(a-label)/(a*(1-a))dadz=a*(1-a)dzdw1=x1_datadzdw2=x2_datadzdb=1gradient_w1 = np.dot(dzdw1, (deda * dadz)) / len(x1_data)gradient_w2 = np.dot(dzdw2, (deda * dadz)) / len(x2_data)gradient_b = (deda * dadz * dzdb).sum() / len(x1_data)w1 -= lr * gradient_w1w2 -= lr * gradient_w2b -= lr * gradient_bif epoch%100==0 or epoch==1:a=forward(w1,w2,b)loss=loss_func(a)print(epoch,loss)x1_min, x1_max = x1_data.min(), x1_data.max()x2_min, x2_max = -(w1 * x1_min + b) / w2, -(w1 * x1_max + b) / w2# 绘制散点图和决策边界ax1.clear()ax1.scatter(x1_data[:len(class1_points)], x2_data[:len(class2_points)])ax1.scatter(x1_data[len(class1_points):], x2_data[len(class2_points):])ax1.plot((x1_min, x1_max), (x2_min, x2_max))ax2.clear()epoch_list.append(epoch)loss_list.append(loss)ax2.plot(epoch_list, loss_list)
plt.show()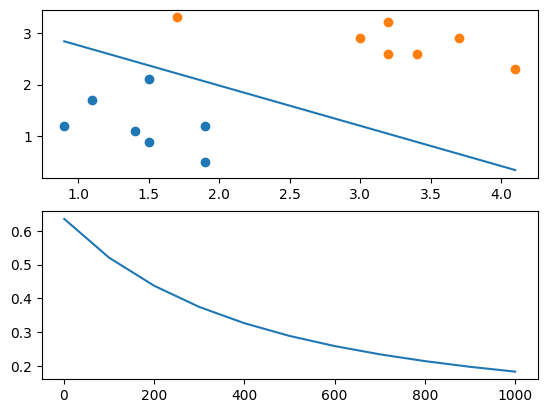
六、完整代码
import numpy as np # 导入 NumPy 库以进行数组和数学运算
import matplotlib.pyplot as plt # 导入 Matplotlib 库以绘制图形 # 定义类1的数据点
class1_points = np.array([[1.9, 1.2], [1.5, 2.1], [1.9, 0.5], [1.5, 0.9], [0.9, 1.2], [1.1, 1.7], [1.4, 1.1]]) # 定义类2的数据点
class2_points = np.array([[3.2, 3.2], [3.7, 2.9], [3.2, 2.6], [1.7, 3.3], [3.4, 2.6], [4.1, 2.3], [3.0, 2.9]]) # 将类1和类2的 x (特征1) 数据合并
x1_data = np.concatenate((class1_points[:, 0], class2_points[:, 0]))
# 将类1和类2的 y (特征2) 数据合并
x2_data = np.concatenate((class1_points[:, 1], class2_points[:, 1])) # 为类1和类2合并标签,类1为 0,类2为 1
label = np.concatenate((np.zeros(len(class1_points)), np.ones(len(class2_points)))) # 前向传播函数
def forward(w1, w2, b): z = w1 * x1_data + w2 * x2_data + b # 计算线性组合 a = sigmoid(z) # 应用sigmoid激活函数 return a # Sigmoid 激活函数
def sigmoid(x): return 1 / (1 + np.exp(-x)) # 计算 Sigmoid 值 # 初始化权重和偏置
w1 = 0.1
w2 = 0.1
b = 0
lr = 0.05 # 学习率 # 损失函数
def loss_func(a): loss = -np.mean(label * np.log(a) + (1 - label) * np.log(1 - a)) # 计算交叉熵损失 return loss # 创建图形及子图
fig, (ax1, ax2) = plt.subplots(2, 1)
epoch_list = [] # 用于存储每个epoch的数量
loss_list = [] # 用于存储每个epoch的损失值 epoches = 1000 # 定义总迭代次数
for epoch in range(1, epoches + 1): # 前向传播,计算输出 a = forward(w1, w2, b) # 计算损失对输出的导数 deda = (a - label) / (a * (1 - a)) dadz = a * (1 - a) # Sigmoid 导数 # 计算损失对权重和偏置的导数 dzdw1 = x1_data dzdw2 = x2_data dzdb = 1 # 对于偏置来说,导数始终是 1 # 计算权重和偏置的梯度 gradient_w1 = np.dot(dzdw1, (deda * dadz)) / len(x1_data) gradient_w2 = np.dot(dzdw2, (deda * dadz)) / len(x2_data) gradient_b = (deda * dadz * dzdb).sum() / len(x1_data) # 更新权重和偏置 w1 -= lr * gradient_w1 w2 -= lr * gradient_w2 b -= lr * gradient_b # 每 100 次迭代打印损失并更新图形 if epoch % 100 == 0 or epoch == 1: a = forward(w1, w2, b) # 计算新的输出值 loss = loss_func(a) # 计算新的损失值 print(loss) # 打印损失 # 更新决策边界的坐标 x1_min, x1_max = x1_data.min(), x1_data.max() x2_min, x2_max = -(w1 * x1_min + b) / w2, -(w1 * x1_max + b) / w2 ax1.clear() # 清空第一张子图 # 绘制类1和类2的数据点 ax1.scatter(x1_data[:len(class1_points)], x2_data[:len(class1_points)], c='blue', label='Class 1') ax1.scatter(x1_data[len(class1_points):], x2_data[len(class2_points):], c='orange', label='Class 2') # 绘制当前的决策边界 ax1.plot((x1_min, x1_max), (x2_min, x2_max), label='Decision Boundary', color='green') ax1.legend() # 显示图例 ax2.clear() # 清空第二张子图 epoch_list.append(epoch) # 将当前epoch添加到列表 loss_list.append(loss) # 将当前损失添加到列表 ax2.plot(epoch_list, loss_list) # 绘制损失变化图 plt.show() # 显示图形