知识图谱
- 1.知识图谱
- 1.1知识图谱形态
- 1.2知识图谱架构
- 2.知识抽取
- 2.1实体抽取
- 2.2关系抽取
- 2.2.1限定领域
- pipeline
- Rbert实现(见论文):
- 联合训练(multi-task)
- 2.2.2 开放领域
- 3.知识融合
- 3.1实体对齐
- 3.2实体消歧
- 3.3属性对齐
- 4.知识推理
- 5.知识表示
- 6.图数据库
- 7.NL2SQL
- 7.1基于FAQ
- 7.2基于分类/抽取任务
- 7.3基于LLM
1.知识图谱
简介: 知识图谱是一种揭示实体之间关系的语义网络,可以对现实世界的事物及其相互关系进行形式化地描述。现在也泛指各种大规模数据库。
1.1知识图谱形态
简介: 三元组是知识图谱的一种通用表达形式或者说是单元。
三元组包含:
- 实体 - 关系 - 实体 案例: 萧炎–妻子–美杜莎
- 实体 - 属性 - 属性值 案例:萧炎–身高–226cm
- 实体 - 标签-标签值 案例:萧炎 - 标签 -养蛇爱好者
实体与其他的区别就在于,实体拥有属性、标签、和其他实体的关系。当然也可用根据实际的场景,去定义实体、属性、标签之间的区别和定义。
知识图谱可以是excel、json各种文件格式,其核心是数据中存在的三元组关系。
1.2知识图谱架构
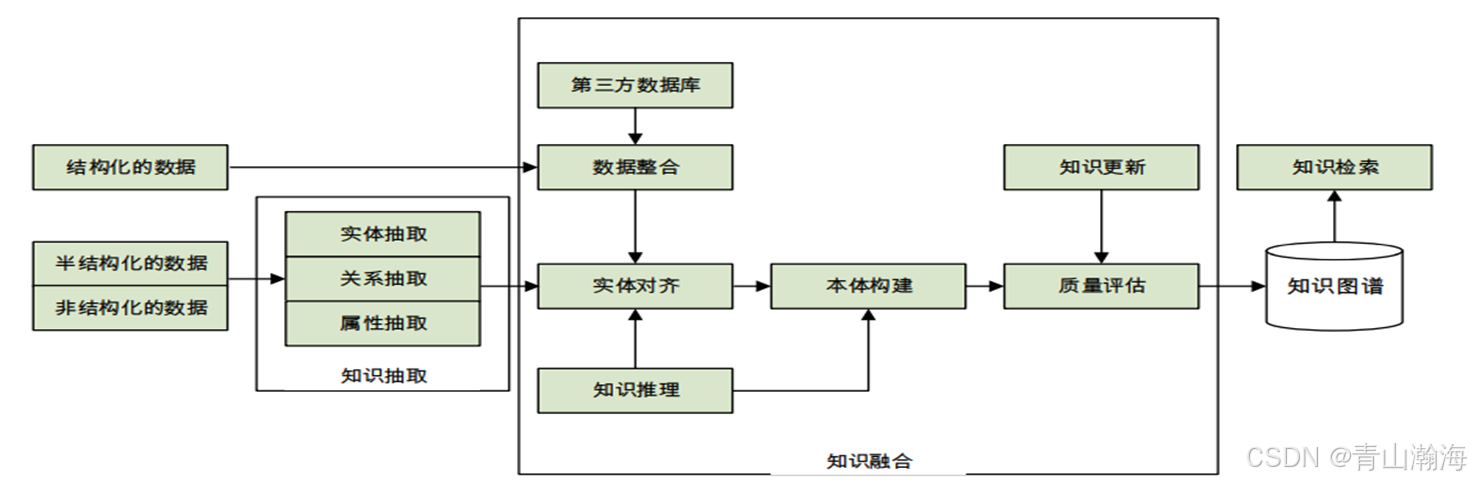
简介: 知识图谱构建的核心是知识抽取,实体对齐、知识推理这三个部分。
关键技术及作用:
- 知识抽取
从非结构化数据中 -> 获取结构化数据- 知识融合
即实体对齐,即消歧提升数据质量- 知识推理
挖掘扩充或补全数据- 知识表示 向量化
2.知识抽取
含义: 面向非结构化数据,过自 动化的技术抽取出可用的知识单元,即包含实体抽取、关系抽取、属性抽取。
介绍: 做实体抽取,关系抽取的方案,基本也能够使用在属性抽取上,没有太明显的区别,所以下面主要介绍实体抽取和关系抽取。
2.1实体抽取
重要性: 实体是知识图谱中的最基本元素,其抽取的完整性、准确率、召回率等将直接影响到知识 库的质量。
可以采用命名实体识别的相关方法:
- 基于规则和词典的方法
- 基于机器学习的模型预测方法
(序列标注问题)
2.2关系抽取
2.2.1限定领域
简介: 限定领域关系抽取,关系类型有限,已知。(比如:只抽取:父子、母子)
pipeline
1. NER:先进行实体抽取: 文本 -> 序列标注模型 -> 实体2. 结合实体和文本,去文本中分类这两者之间的关系: 文本+实体 -> 文本分类模型 -> 关系
Rbert实现(见论文):
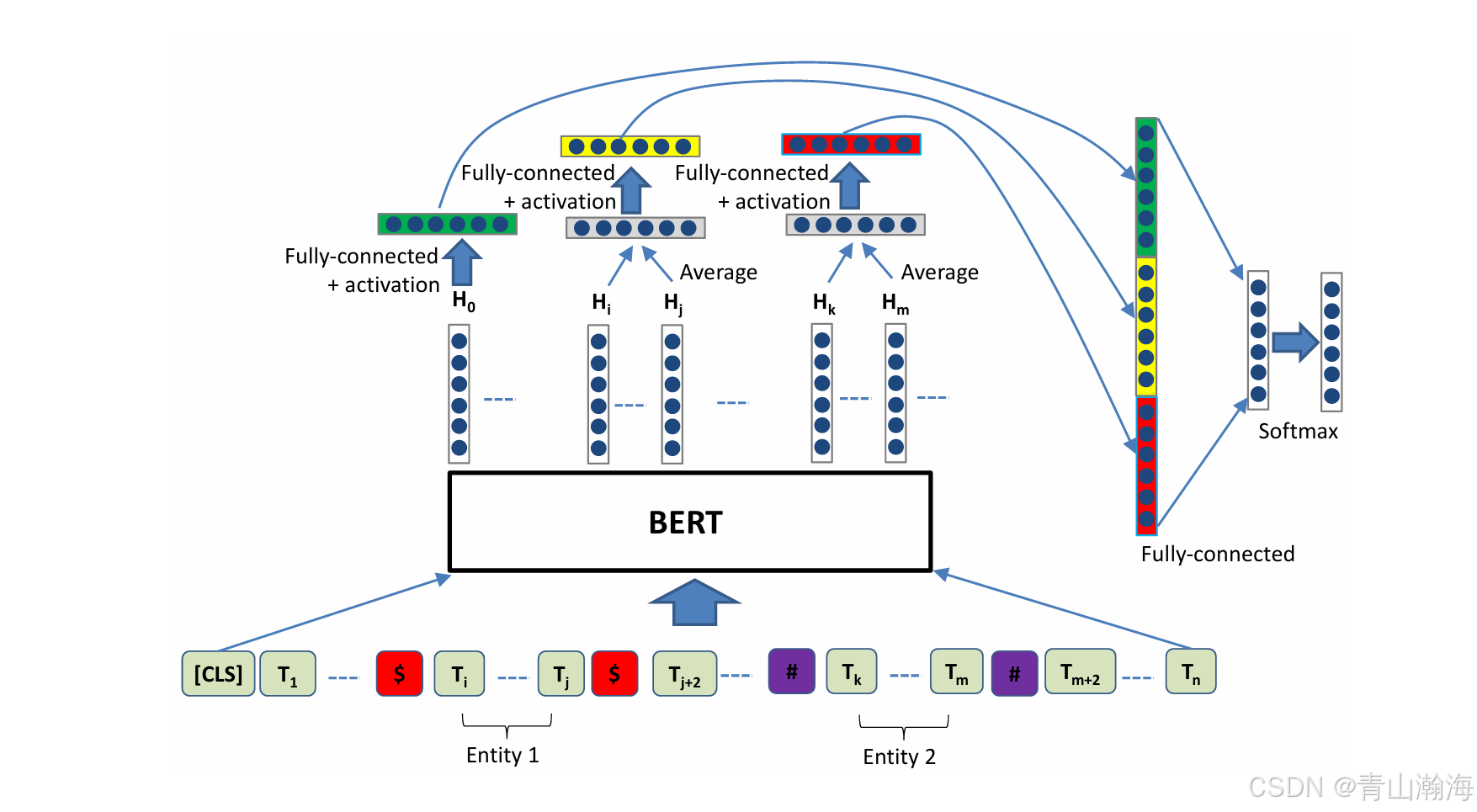
释义逻辑:
- 标注出两个实体的位置,并前后有做特殊的符号标记;
- 将其通过BERT表示出来,分别得到这句话、两个判断关系的实体的向量
- 实体的向量先求平均,再过线性层,过激活层,与句子结合在一起,过一个线性岑分类,得到两个句子间的关系。
- 使用模型时,则将上一层模型抽取的实体标记出来,送人到分类模型中预测结果。
联合训练(multi-task)
简介: 即将文本交给模型模型,直接输出实体和实体间的关系信息。
训练方法:
- 将文本经过embedding和模型层计算。
- 最后分为两个线性层计算,一个是序列标注出实体位置,有一个loss值
- 预测出实体关系的是一个loss值
- 通过将两个loss值,相加,可以将两个任务一起进行训练。
好处:
- 共用了线性层、Embedding层,极大减少了原有两个模型的所需要的资源。
- 一个模型完成预测,比两个模型串联预测,效率高,速度快。
注意:
- 由于
两个任务的loss值,相加成为最终的loss,在这个的基础上进行训练,由于难度不一样,所以会导致,一个任务已经基本接近拟合,另外一个还很初级(序列标注),所以在两个loss相加为一个进行计算时,需要设置一些系数,调整他们得到的训练量。- 正常来将,multi-task训练的结果可以和单独训练的结果相当。
- 这种情况,更倾向于材料中,只有一对实体和实体的关系。
2.2.2 开放领域
简介: 开放领域关系抽取,主要是基于序列标注做的。当前可以基于大模型做。
例子如下: subject 实体1、predict 关系、object 实体2;jinxBIO标注
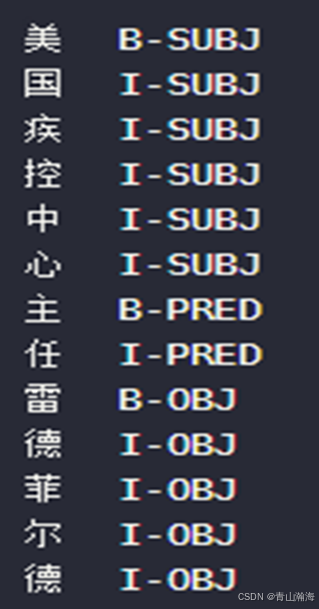
问题点:
- 知识图谱的构建在梳理实体关系后,还需要将这些抽取的知识融合,但是
开放式的抽取,实体关系就会非常多样,不好处理,会为后续的融合有较大的影响。- 用大模型做实体抽取,以当前的水平,仍然未能达到直接使用的完美状态,需要人工进行审核。
3.知识融合
简介: 由于知识图谱中的知识来源广泛,存在知识质量良莠不齐、来自不同数据源的知识重复、知识间的关联不够明确等问题,所以必须要进行知识的融合。简单说,就是对第一步知识抽取数据的清洗加工。常见的内容包含:实体对齐、实体消歧、属性对齐。
3.1实体对齐
简介: 将不同来源的知识认定为真实世界的同一实体。即名称相同、或者指代的是相同的事物,叫法不一样,需要将数据整合。
示意图:
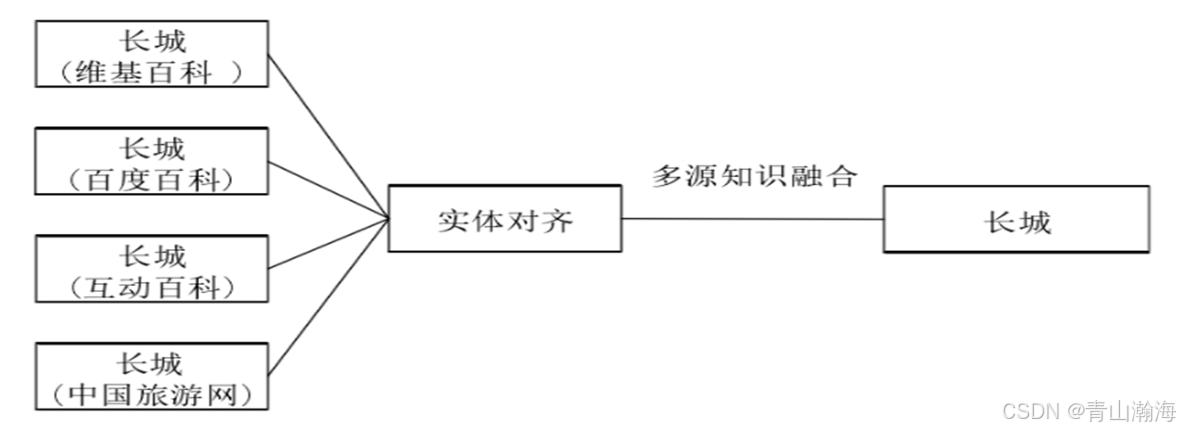
处理方法:
- 依据不同实体所包含的属性之间的相似度,来判断实体是否为同一实体,将这种相似的列举出来
- 人工对相似实体进行处理。
3.2实体消歧
简介: 将同一名称但指代不同事物的实体区分开。
示意图:
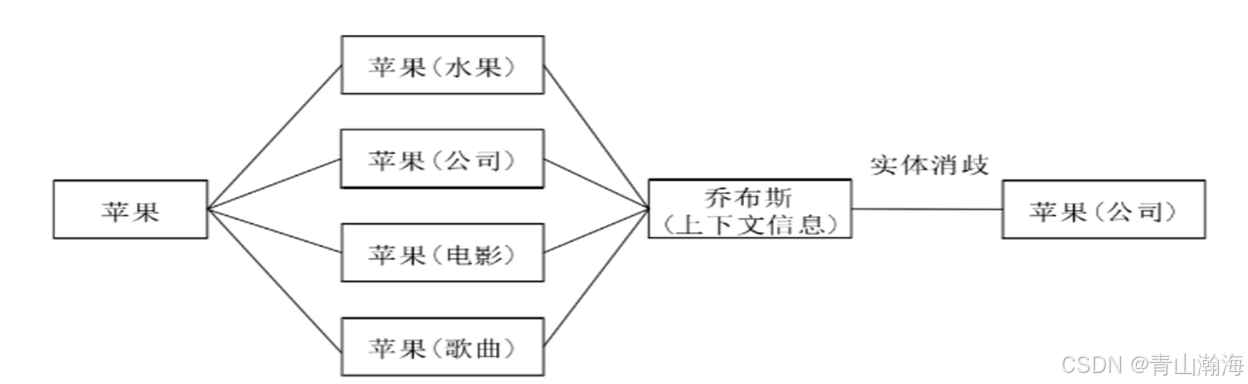
处理方案:
- 场景1,在整理的内容中,找出相同名称的实体,对比属性等信息进行消歧
- 场景2,有一个非结构的文段,识别出其中实体名称,现在归类到那个实体中呢,需要通过上下文,去进行匹配。
3.3属性对齐
简介: 不同数据源对于实体属性的记录可能使用不同的词语。
举例:
-
x度百科:姚明 - 生日 - 1980年9月12日
-
搜x百科:姚明 - 出生日期 - 1980年9月12日
-
wxkx百科:姚明 - 出生年月 - 1980年9月12日
处理方案:
使用属性和属性值做相似度计算。属性对齐在有些场景下,无法做好时,做一部分重复数据的冗余,对于使用也是没有问题的。比如上面举例的三条都存入知识图谱中。
4.知识推理
简介: 在已有的知识库基础上进一步挖掘隐含的知识,从而丰富、扩展知识库。
举例:
- 传递性:A-儿子-B,B-儿子-C, A-?-C
- 实例性:A-是-B,B属于C,A-?-C A是四川人,四川人属于中国人,所欲A是中国人。
挖掘方法: 基于特定的规则、句法;比如爸爸的爸爸是爷爷;这种方式在一些垂直领域内效果明显,比如医药。
使用模型来做: 基于模型的知识补全,给出两个实体,推断其关系,h + r -> t, h + t -> r , (h, r, t) -> {0, 1},相关论文 KG-Bert。
5.知识表示
简介: 将知识图谱中的实体,关系,属性等转化为向量,利用向量间的计算关系,反映实体间的关联性。
原理逻辑: 对于三元组(h, r, t),学习其向量表示lh lr lt 使其满足 lh + lr ≈ lt,即实体加上关系,应该接近另一个实体。
训练流程论文截图:

释义:
- 第一步份,即初始化三元组的实体、关系的向量,其中
e代表实体,l代表向量,l取值还需要除以它的模长。- 任取一个三元组,将其中的实体随机换成其他的三元组的实体,这样构成一个正样本和多个负样本;将所有的正样本三元组都构造一遍,存在Tbatch中。
- 训练的时候,有常量r,加上正样本:实体+关系 与另一个实体的距离;与负样本求距离做差。并且只有当值为正时,才做loss。
- 训练的方式,使得,配置r;可以训练最终,正样本的距离和负样本距离的区分度。即正样本距离应该比负样本距离,小于等于r。
扩展: 融合文本的知识表示,将文本表示和知识图谱中的实体关系表示放入同一个空间。使得学习到的实体表示可以在文本相关的任务中使用。在实体关系的计算中,实体是用向量表示的,用来转化向量的不一定需要使用真实的字词,可以是一段话的id、一个词的id;这样就可以将其之间的关系训练到一起。
6.图数据库
示意图:
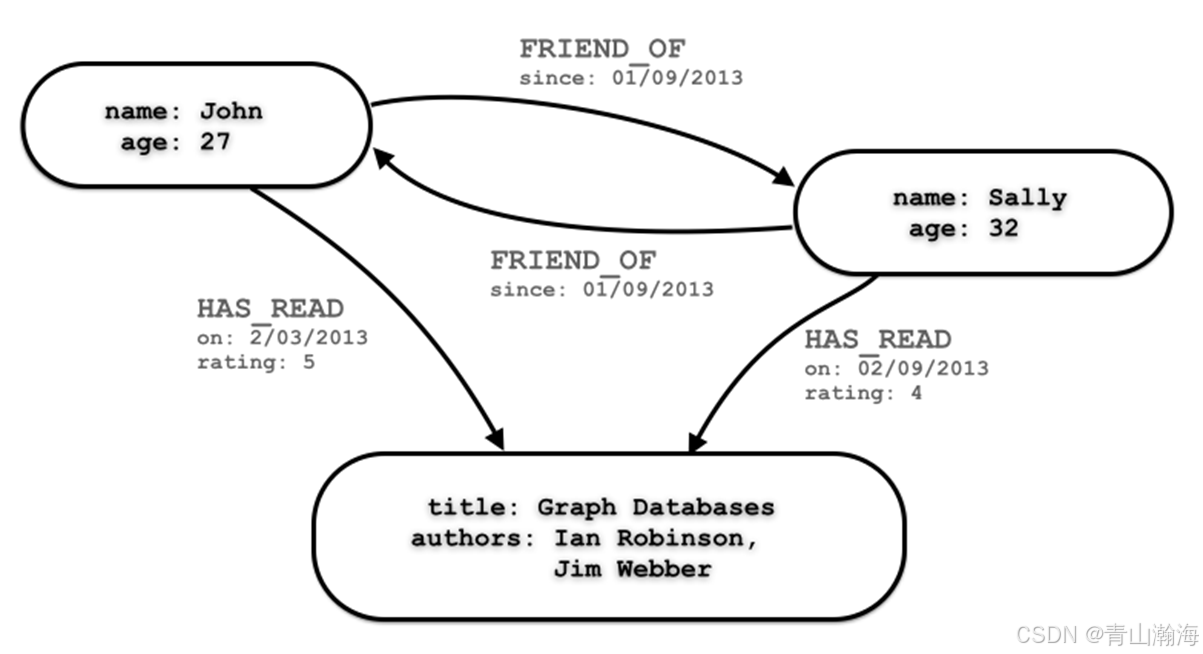
释义:
- 图数据库的每一个节点相当于原来的数据库的一条数据。
- 图数据库中,会允许设置不同数据之间的关系,在查询时,可以查询指定关系的值的数据内容。
- 图数据库是可以存储和查询知识图谱的数据容器。
- 常见的图数据库:
Neo4j,
通过python接口,pip install py2neo,连接数据库,执行cypher语句
7.NL2SQL
介绍: 即将文本或者自然语言转化成符合特定数据库使用的查询语句。
流程: 文本 --》 SQL --》 数据库 --》 结果
7.1基于FAQ
介绍: 基于模板+文本匹配,类似于faq库问答。
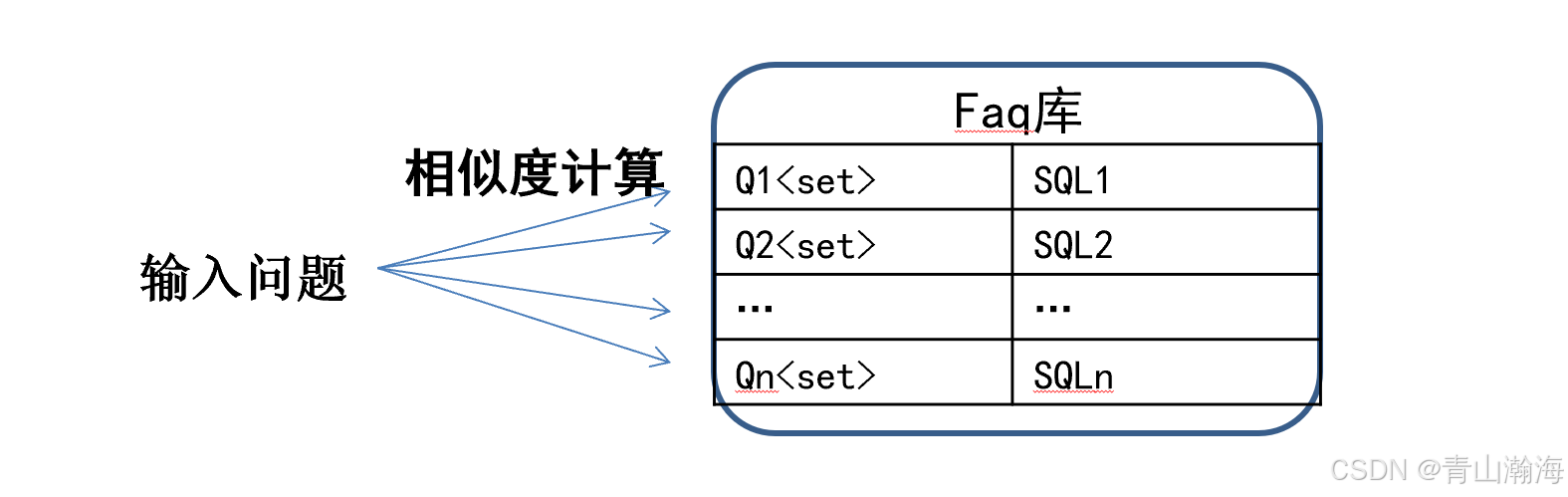
注意:
- 这里匹配的问答对中,问题是有卡槽的,即知识图谱中的实体、关系、属性信息。
- 答案中的内容,即为实际需要查询数据库的SQL,这里的SQL对应的也有属性值、实体卡槽。
优点:
- 即可以通过一条SQL完成一类查询语句的生成,即通过问题实体的抽取,将实体赋值到SQL中。
- 降低相似实体、属性名称的问题,由于匹配度较高,而被相似度匹配到。
缺点:
- 需要人工的构造模板,并且随时模板的增多,管理比较困难
举例:

- 进入一个问题,首先对问题进行实体、关系的抽取,进行数量的校验。(这里的
提取可以使用正则,因为在构建知识图谱时,已经知道现有的实体、实体关系、标签、属性有那些)效果不好的情况:有两个实体:周杰、周杰伦。- 在校验通过的问题中,进行打分,选择最高的问题对应的cypher。打分时,是将客户问到的问题,与
校验通过的Q进行匹配度的计算,这个时候的Q,应该是将抽取实体赋值上去的完整句子。- 将抽取的实体与关系放到cypher中,进行数据库查询,得到结果。
7.2基于分类/抽取任务
简介: 即将问题解析为sql的过程中,拆解成多个分类或抽取问题处理,也叫:semantic parsing。
示例图:

逻辑:
- 按照构造SQL的逻辑,逐步的去判断和拆解。
- 举例,上述中,在查询选择的列时,将问题和每一列列名都交由模型判断,得到是否采用的结果,是则在此处,标注序号。
- 其他部分都按照这个逻辑进行,最后得到sql拼接的一个json格式
- 按照固定格式解析json即可生成完整的SQL。
优点:
- 单表查询时,构建SQL灵活,查询范围、内容等多
缺点:
- 存在一些复杂的表嵌套、多表关联查询的SQL,比较难实现
7.3基于LLM
简介: 利用LLM的生成能力,直接生成SQL.
优点:
- 通过大模型可以方便生成一些简单的查询语句。
缺点:
- 对于复杂的SQL就无法完成任务,或者完成效果较差,比如:嵌套、多表查询等
- 需要完善表、表字段的释义,并且在迁移时,会有一些问题,比如不同的公司相同含义的字段名称不同、释义也不同。