文章目录
- Pre
- 一、大模型的"幻觉"之谜
- 1.1 何为"幻觉"现象?
- 1.2 专业场景的致命挑战
- 二、RAG技术解析:给大模型装上"知识外挂"
- 2.1 核心原理:动态知识增强
- 2.2 技术实现三部曲
- 三、RAG vs 微调:技术选型指南
- 3.1 核心差异对比
- 3.2 黄金选择法则
Pre
LLM - 白话向量模型和向量数据库
一、大模型的"幻觉"之谜
1.1 何为"幻觉"现象?
大模型会以高度自信的姿态输出错误信息,犹如天才学生考试时"编造答案"。这种现象主要源于:
- 知识缺陷:训练数据存在错误/过时信息(如2021年前的GPT模型)
- 推理偏差:过度泛化语言模式(将"鸟类会飞"套用于企鹅)
- 领域盲区:缺乏垂直行业知识(如企业私有产品数据)
1.2 专业场景的致命挑战
在医疗诊断、法律咨询等场景中,10%的错误率可能带来灾难性后果。
二、RAG技术解析:给大模型装上"知识外挂"
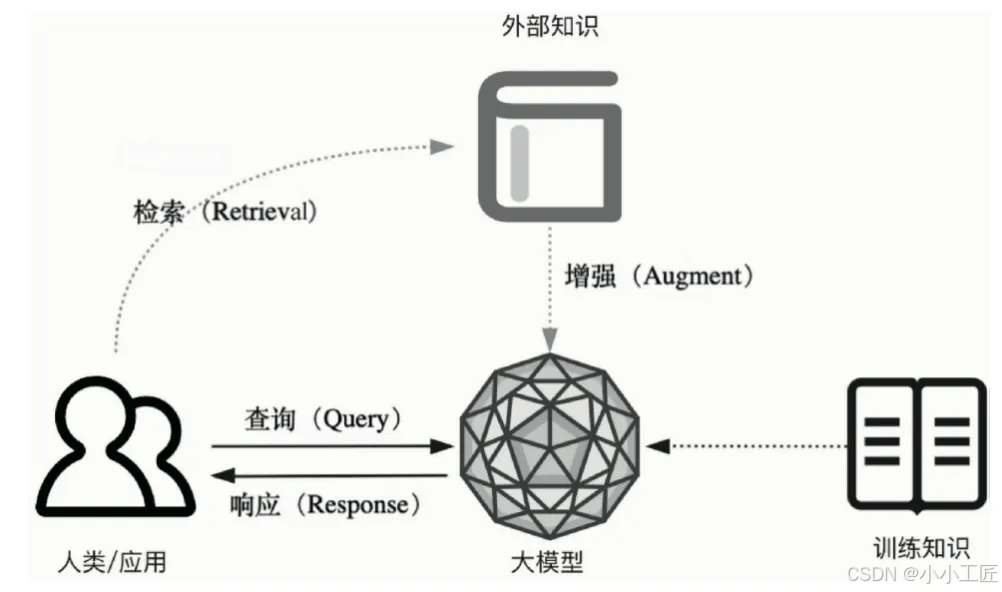
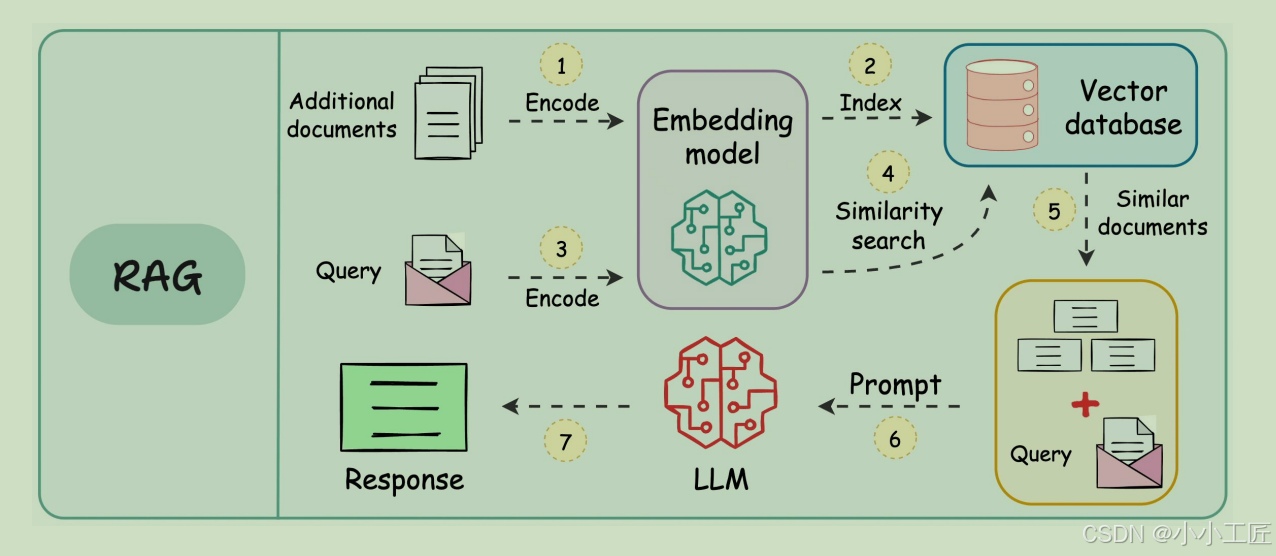
2.1 核心原理:动态知识增强
RAG(Retrieval-Augmented Generation)通过实时检索外部知识库,为生成过程提供精准参考。其创新之处在于:
| 传统大模型 | RAG增强模型 |
|---|---|
| 依赖静态训练数据 | 动态整合最新知识 |
| 单一生成过程 | 检索-生成双阶段流程 |
| 通用知识覆盖 | 领域知识深度定制 |
2.2 技术实现三部曲
案例:构建智能客服系统
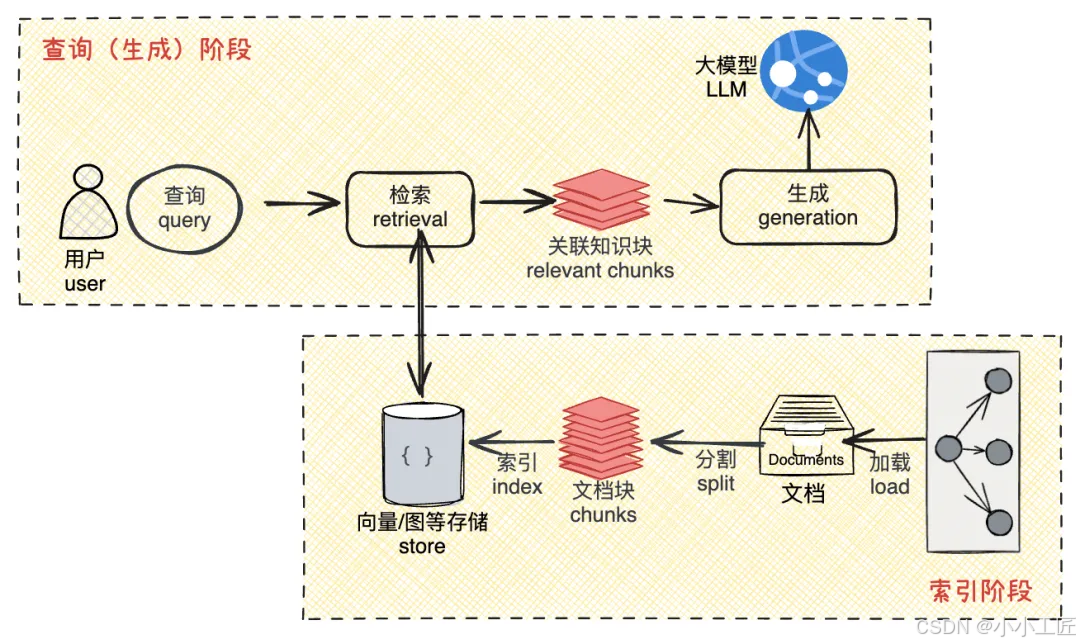
- 知识索引构建
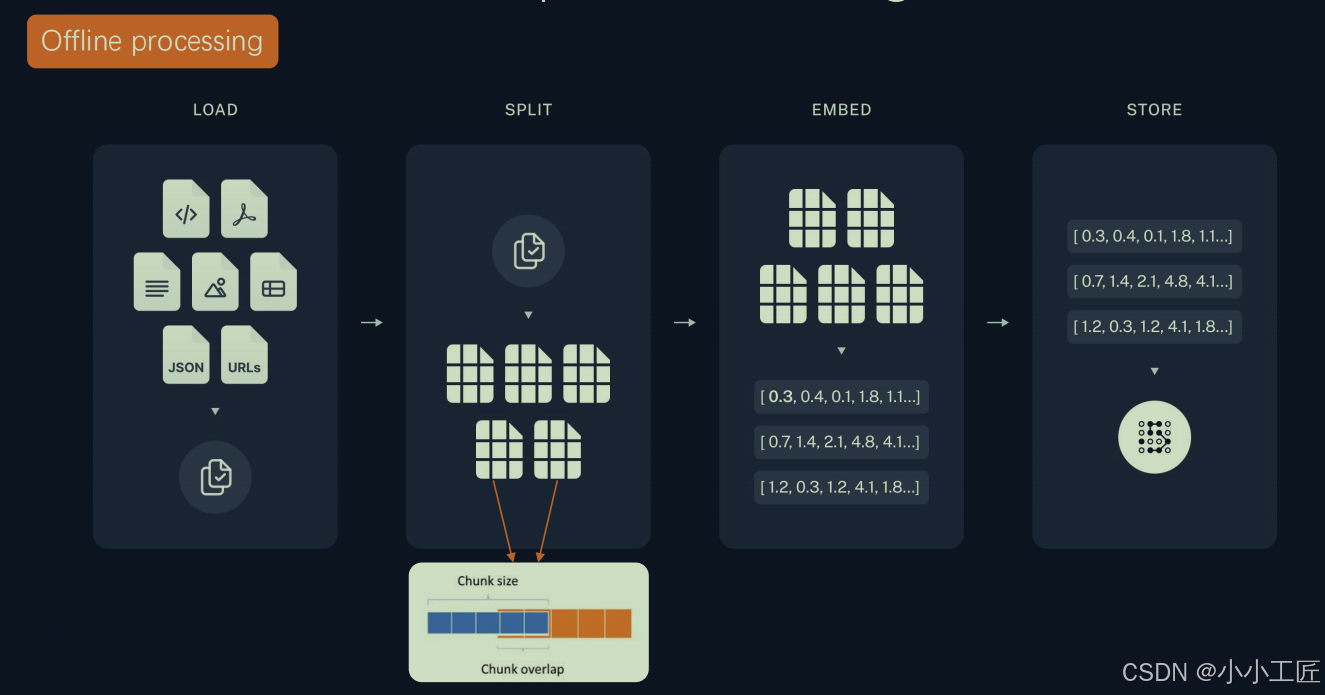
-
智能检索阶段
-
增强生成阶段
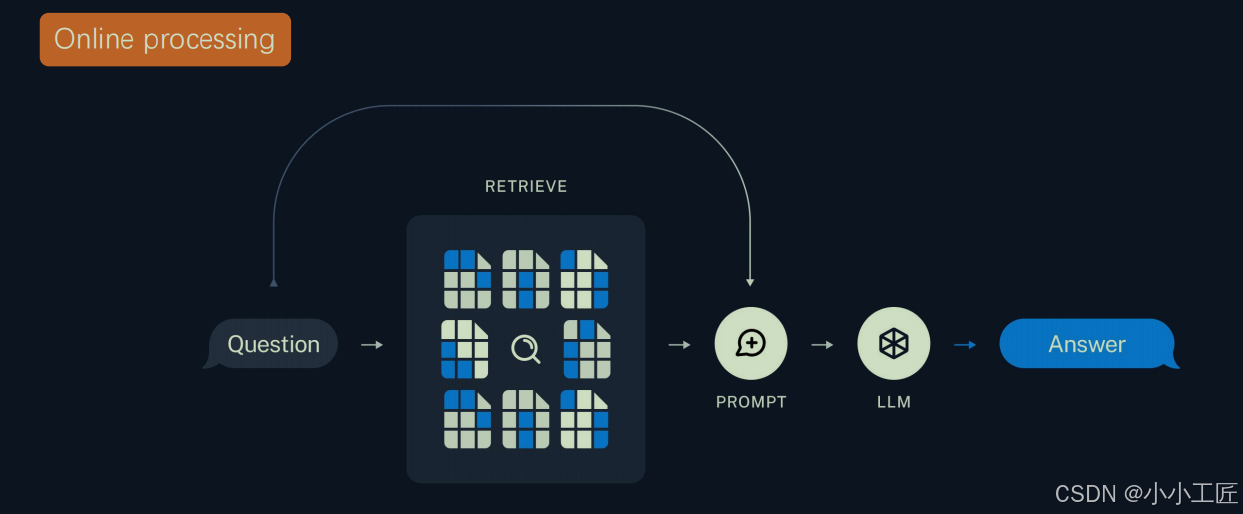

// 使用LangChain4j实现电商智能客服的RAG流程
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.retriever.EmbeddingStoreRetriever;
import dev.langchain4j.store.embedding.EmbeddingStore;public class RagProductAssistant {// 1. 检索增强组件private final EmbeddingModel embeddingModel;private final EmbeddingStore<TextSegment> embeddingStore;// 2. 大模型组件private final ChatLanguageModel chatModel;public RagProductAssistant(EmbeddingModel embeddingModel, EmbeddingStore<TextSegment> embeddingStore,ChatLanguageModel chatModel) {this.embeddingModel = embeddingModel;this.embeddingStore = embeddingStore;this.chatModel = chatModel;}// 核心RAG处理流程public String answerQuestion(String userQuery) {// 阶段1:检索上下文List<TextSegment> relevantContexts = retrieveRelevantContext(userQuery);// 阶段2:增强生成return generateAugmentedResponse(userQuery, relevantContexts);}// 上下文检索方法private List<TextSegment> retrieveRelevantContext(String query) {// 生成查询向量Embedding queryEmbedding = embeddingModel.embed(query).content();// 向量数据库检索(取Top3)int maxResults = 3;List<EmbeddingMatch<TextSegment>> matches = embeddingStore.findRelevant(queryEmbedding, maxResults);// 提取文本片段return matches.stream().map(EmbeddingMatch::embedded).collect(Collectors.toList());}// 增强生成方法private String generateAugmentedResponse(String query, List<TextSegment> contexts) {// 构建增强提示词String promptTemplate = """基于以下产品信息回答用户问题:${contexts}用户问题:${query}要求:1. 使用中文回答2. 如果信息不足请明确说明3. 保持专业性""";// 拼接上下文String contextStr = contexts.stream().map(TextSegment::text).collect(Collectors.joining("\n\n"));// 填充模板String finalPrompt = promptTemplate.replace("${contexts}", contextStr).replace("${query}", query);// 调用大模型生成return chatModel.generate(finalPrompt);}
}// 使用示例
public class RagDemo {public static void main(String[] args) {// 1. 初始化组件EmbeddingModel embeddingModel = new AllMiniLmL6V2EmbeddingModel();EmbeddingStore<TextSegment> embeddingStore = createProductEmbeddingStore();ChatLanguageModel chatModel = OpenAiChatModel.builder().apiKey("your_key").modelName("gpt-3.5-turbo").build();// 2. 创建RAG助手RagProductAssistant assistant = new RagProductAssistant(embeddingModel, embeddingStore, chatModel);// 3. 处理用户查询String question = "你们最新款手机支持多少倍光学变焦?";String answer = assistant.answerQuestion(question);System.out.println(answer);}// 初始化产品知识库private static EmbeddingStore<TextSegment> createProductEmbeddingStore() {// 实际场景中连接Redis/Elasticsearch等向量数据库InMemoryEmbeddingStore<TextSegment> store = new InMemoryEmbeddingStore<>();// 加载产品文档(示例数据)List<String> productSpecs = Arrays.asList("型号X30 Pro: 支持100倍混合变焦,搭载潜望式镜头","型号X30: 支持30倍光学变焦,夜景拍摄增强");// 生成嵌入并存储productSpecs.forEach(text -> {Embedding embedding = embeddingModel.embed(text).content();store.add(embedding, TextSegment.from(text));});return store;}
}
三、RAG vs 微调:技术选型指南
3.1 核心差异对比
| 维度 | RAG | 微调 |
|---|---|---|
| 知识更新 | 实时动态 | 需重新训练 |
| 硬件需求 | CPU可运行 | 需GPU资源 |
| 实施周期 | 小时级部署 | 周级准备 |
| 可解释性 | 检索记录可溯源 | 黑盒决策 |
3.2 黄金选择法则
- 选择RAG:知识频繁更新、需要结果溯源、快速迭代场景
- 选择微调:专业术语理解、特殊任务适配、长期稳定场景
典型案例:
- 医院病历系统:微调+医学知识库RAG
- 法律咨询平台:法条库RAG+裁判文书微调
