Executor的核心功能
运行任务:Executor负责运行组成Spark应用的任务,并将结果返回给驱动器进程。
缓存管理:Executor通过自身的块管理器为用户程序中要求缓存的RDD提供内存或存储。
Master和Worker的角色
Master:负责资源调度和分配,进行集群监控,类似于YARN环境中的ResourceManager(RM)。
Worker:运行在集群服务器上的进程,负责并行处理和计算,类似于YARN环境中的NodeManager(NM)。
Application Master
作用:申请资源容器,运行用户程序任务,监控任务状态,检查任务是否失败等异常情况。
并行度
定义:并行度是指整个集群并行执行任务的数量。
特点:可以在代码中实现并行度,并且可以在应用运行时动态修改.
RDD(弹性分布式数据集)
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是 Spark 中最基本的数据处理模型。代码中是一个抽象类,它代表一个弹性的、不可变、可分区、里面的元素可并行计算的集合。
核心概念:RDD是Spark中最基本的数据处理模型,具有弹性、分布式、不可变、可分区等特点。
弹性:存储、容错、计算、分片等方面的弹性。
分布式:数据存储在大数据集群的不同节点上。
不可变:RDD封装了计算逻辑,不可改变,只能创建新的RDD。
可分区:可以进行分区并行计算。
RDD的核心属性
分区列表:用于执行任务时并行计算。
分区计算函数:在每一个分区进行计算的函数。
依赖关系:多个RDD之间的依赖关系,用于组合多个计算模型。
RDD的执行原理
- 启动 Yarn 集群环境
- 先申请资源,将应用程序的数据处理逻辑分解成计算任务。
- 将任务分发到分配资源的计算节点上进行计算,最后得到计算结果。
- 调度节点将任务根据计算节点状态发送到对应的计算节点进行计算
RDD序列化
内容:包括闭包检查、序列化方法和属性、序列化框架等。
包检查:确保算子外的数据可以序列化,避免闭包错误。
RDD依赖关系
血缘关系:记录RDD的转换行为,以便恢复丢失的分区数据。
依赖关系:相邻RDD之间的关系,分为窄依赖和宽依赖。
RDD 持久化
内容:包括RDD Cache 缓存 RDD 通过 Cache 或者 Persist 方法将前面的计算结果缓存。
RDD CheckPoint 检查点通过将 RDD 中间结果写入磁盘。
缓存和检查点区别:
- Cache 缓存只是将数据保存起来,不切断血缘依赖。Checkpoint 检查点切断血缘依赖。
- Cache 缓存的数据通常存储在磁盘、内存等地方,可靠性低。Checkpoint 的数据通常存储在 HDFS 等容错、高可用的文件系统,可靠性高。
- checkpoint()的 RDD 使用 Cache 缓存,否则需要再从头计算一次 RDD。
其他概念
转换算子和行动算子:转换算子对数据进行格式或内容上的转换,行动算子触发实际的计算。
分区器和首选位置:自定义数据分区和选择计算节点的位置。
Spark-Core编程
环境准备
- Jdk8版本
- Scala12版本
- Idea集成开发环境中需要安装scala插件
创建新文件及项目配置
创建新文件:通过点击“new”,选择“model”,然后在弹窗中选择“maven”,输入文件名并避免与现有文件名重复。
项目配置:在新窗口中打开项目,复制必要的配置文件和依赖到项目中,确保不删除原有内容。
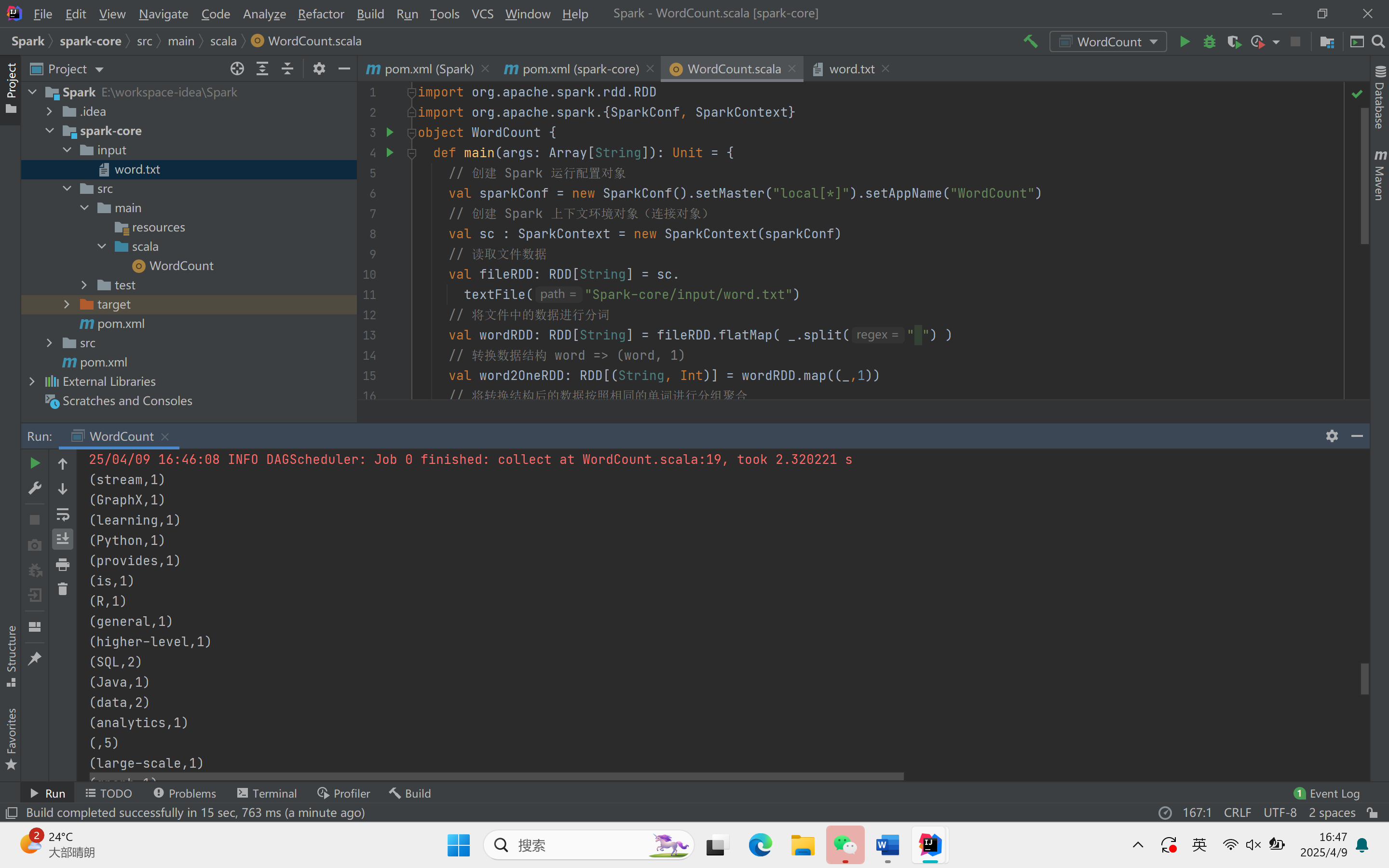
词典统计案例
导入包:导入Spark相关的包。
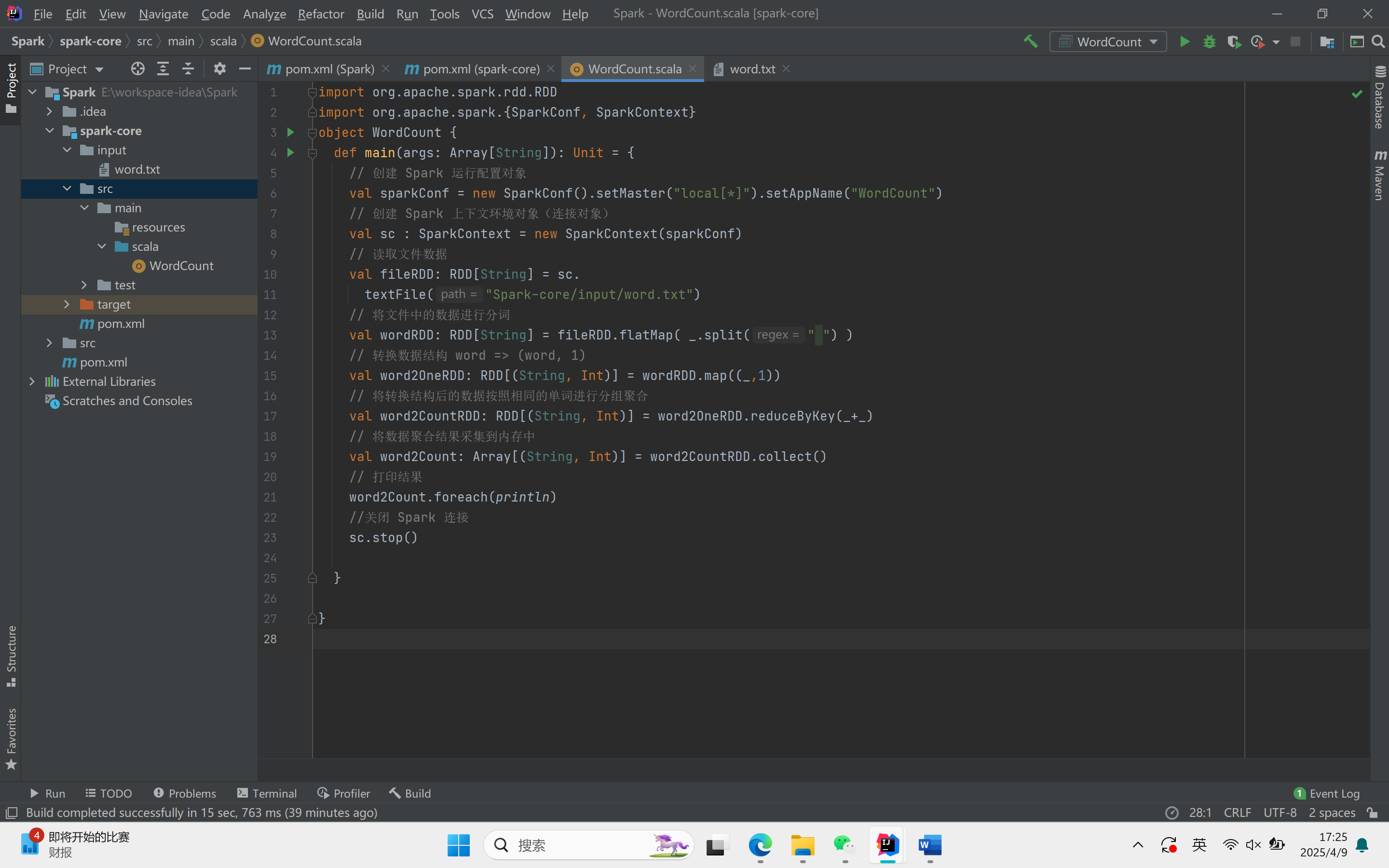
主方法:定义主方法。
创建RDD的三种方式
从集合内存中创建:使用SC.makeRDD方法。
从外部文件中创建:使用SC.textFile方法。
从其他RDD创建:通过映射和扁平化操作从其他RDD创建新的RDD。
代码示例