1. DeepSeek R1-Zero
在训练DeepSeek R1之前,深度求索团队尝试做了一个DeepSeek R1-Zero的模型,只进行强化学习而不需要监督微调,以此来强化模型自我推理的能力。
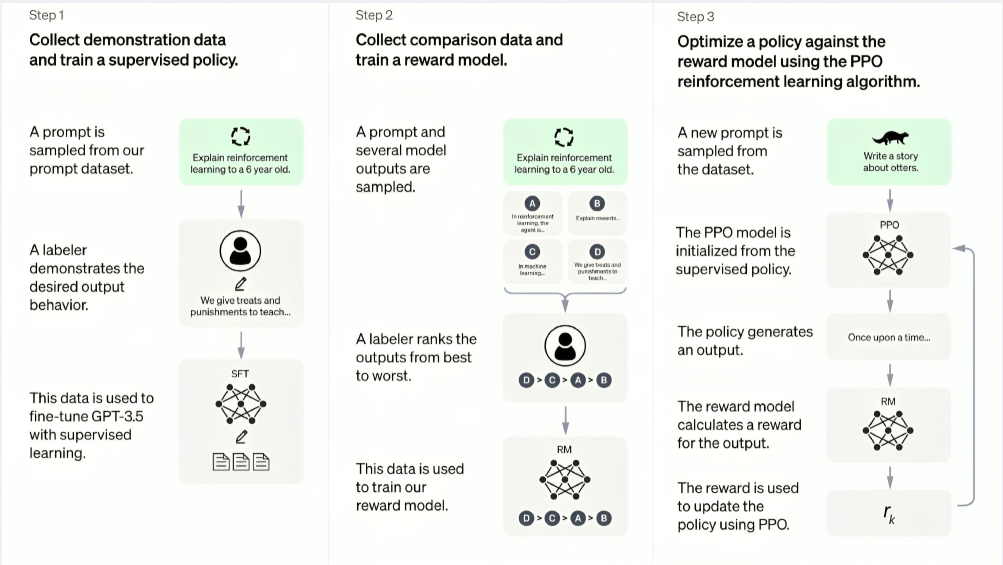
通过下图回顾下ChatGPT的做法:首先SFT,然后训练奖励模型,最后通过PPO来迭代模型参数。而DeekSeek R1-Zero省略掉了SFT这一步骤,直接采用没有critic的GRPO来进行参数迭代,这种做法可以摒弃掉人类数据,让模型自我进行博弈从而完成模型迭代进化。
而这种做法之所以在很多任务中表现优秀主要体现在以下三个方面:GPRO、奖励机制、训练模板。
GPRO。为了节省强化学习的训练成本,作者采取组相对策略优化GRPO,放弃与策略模型参数相近的critic模型,而是从组得分中估计baseline。
奖励机制。奖励是训练信号的来源,决定了强化学习的方向。作者提出了一种基于规则的奖励系统,由准确性奖励和规则性奖励组成,这意味着模型不仅要回答正确还要保证推理思路是正确的。
训练模板。该训练模板要求模型首先要生成推理过程再得出对应的答案。
A conversation between User and Assistant. The user asks a question, and the Assistant solves it.
The assistant first thinks about the reasoning process in the mind and then provides the user with the answer. The reasoning process and answer are enclosed within <think> </think> and <answer> </answer> tags
respectively, i.e., <think> reasoning process here </think> <answer> answer here </answer>. User: What is 7 + 3*7 = ?. Assistant:
DeekSeek R1-Zero的成功,展示出模型可以仅依靠强化学习就能自我迭代出强大的推理能力。
2. DeepSeek R1
应对DeekSeek R1-Zero中出现的可读性差、语言混乱等问题,深度求索团队提出了DeepSeek R1模型,该模型训练包括四个阶段:冷启动数据SFT、面向推理的强化学习、拒绝采样SFT、面向通用能力的强化学习。
冷启动SFT。使用DeekSeek R1-Zero创建一些冷启动数据,挑选出可读性强的,并人工标注后,作为冷启动微调数据。
面向推理的强化学习。在R1-Zero的基础上加入了语言一致性奖励,奖励规则包括:准确性奖励、规则性奖励、语言一致性奖励,模型不仅要有正确的推理思路和准确的答案,生成的内容还要保证语言一致性。
拒绝采样SFT。采用60W的推理数据和20W的非推理数据(翻译、写作等)构建微调数据集,保证模型在其他通用性领域也具有不错的效果。
面向通用能力的强化学习。为了进一步使模型符合人类偏好,提出一个辅助的强化学习阶段,旨在提升模型的有用性和无害性,同时优化其推理能力。
3. R1蒸馏版模型
使用R1数据蒸馏其他通用性模型,直接使用 DeepSeek-R1 阶段三中精心挑选的 80 万个样本对开源模型如 Qwen(Qwen, 2024b)和 Llama(AI@Meta,2024)进行了微调。