目录
摘要
Abstract
文献阅读
问题引入
研究背景
研究意义
研究目的
方法论
位移时间序列分解
基于注意力的深度学习模型
可解释性方法
创新点
CNN-Attention-BiGRU模型
变分模态分解
模型的可解释性
实验研究
数据集
模型训练与预测
结果评估
时间序列预处理
缺失值的插值法
平滑处理
总结
摘要
这篇文献围绕滑坡位移预测展开研究。文章结构上,依次介绍研究背景、区域概况、研究方法、实验结果、讨论分析和研究结论,逻辑连贯、条理清晰。其最大特点是将MT-InSAR技术与基于注意力机制的深度学习方法相结合,构建了CNN-Attention-BiGRU模型。该模型优势明显,不仅能有效整合多源数据,还提高了预测精度和模型可解释性。 研究成果主要应用于滑坡位移预测,之所以采用这种方法,是因为传统监测手段成本高、范围受限,而现有深度学习方法存在“黑箱”问题。通过实验对比发现,该模型在捕捉滑坡变形与触发因素的非线性关系上表现卓越,相比BiLSTM、BiGRU等传统模型,在均方根误差(RMSE)和平均绝对误差(MAE)方面有显著改善,分别降低了21%-55%和23%-56%。 不过研究仍有改进空间,未来可以融入更多环境和地质因素,进一步提升预测的准确性。总的来说,这项研究为滑坡灾害预警和防治提供了可靠的技术支持,在地质灾害研究和遥感监测领域具有重要的应用价值和发展潜力。
Abstract
This literature focuses on the prediction of landslide displacement. In terms of article structure, it sequentially introduces the research background, regional overview, research methods, experimental results, discussion and analysis, and research conclusions, with logical coherence and clear organization. Its biggest feature is the combination of MT InSAR technology with attention based deep learning methods, constructing the CNN Attention BiGRU model. This model has obvious advantages, not only can it effectively integrate multi-source data, but also improve prediction accuracy and model interpretability. The research results are mainly applied to landslide displacement prediction. The reason for adopting this method is that traditional monitoring methods have high costs and limited scope, while existing deep learning methods have a "black box" problem. Through experimental comparison, it was found that this model performs excellently in capturing the nonlinear relationship between landslide deformation and triggering factors. Compared with traditional models such as BiLSTM and BiGRU, it has significant improvements in root mean square error (RMSE) and mean absolute error (MAE), reducing them by 21% -55% and 23% -56%, respectively. However, there is still room for improvement in research, and in the future, more environmental and geological factors can be incorporated to further enhance the accuracy of predictions. Overall, this study provides reliable technical support for landslide disaster warning and prevention, and has important application value and development potential in the fields of geological disaster research and remote sensing monitoring.
文献阅读
title:An interpretable attention-based deep learning method for landslide prediction based on multi-temporal InSAR time series: A case study of Xinpu landslide in the TGRA
DOI:10.1016/j.rse.2024.114580
问题引入
研究背景
滑坡是全球最严重的地质灾害之一。滑坡位移监测对于早期预警和风险降低至关重要。然而,传统的基于地面的位移测量方法(如水准测量或全球导航卫星系统GNSS)由于成本高、数据点有限,难以在大范围内应用。近年来,随着合成孔径雷达干涉测量(InSAR)技术的发展,解决了其实时和远程高精度的问题。此外,深度学习方法在处理多变量数据和揭示隐藏数据关系方面表现出色,但其中时间序列的预测存在“黑箱”局限性。因此,如何结合深度学习的强预测能力和可解释性机制,成为当前滑坡预测研究的重要方向。
研究意义
本研究提出了一种基于深度学习的可解释方法,用于基于多时相合成孔径雷达干涉测量(MT-InSAR)时间序列的滑坡位移预测。该方法通过引入注意力机制,不仅提高了模型对滑坡变形及其触发因素之间复杂非线性关系的捕捉能力,还增强了模型的可解释性,使其能够揭示影响滑坡变形的关键因素及其相对重要性。这对于提高滑坡灾害预警系统的准确性和可靠性具有重要意义。
研究目的
旨在构建一个结合可解释深度学习和MT-InSAR技术的滑坡位移预测模型,通过引入注意力机制和双向门控循环单元(BiGRU),提高滑坡位移预测的准确性和可解释性。
方法论
位移时间序列分解
step1 时间序列预处理
包括数据插值、缺失值处理、平滑处理
数据插值法是一种常用的时间序列缺失值插补技术。它有助于使用周围的两个已知数据点估计丢失的数据点。常见的方法有:基于时间的插值法、样条插值和线性插值。
平滑处理
萨维茨基-戈莱滤波器( Savitzky-Golay Filter)是一种数字滤波器,可应用于一组数字数据点,目的是平滑数据,即在不扭曲信号趋势的情况下提高数据的精度。
step2 时间序列分解
变分模态分解 (Variational Mode Decomposition, VMD) 是一种新型的自适应信号分解方法,它具有优越的抗噪性能和对非平稳非线性信号的适应性。
标准VMD算法的核心思想是将输入信号分解成若干个具有有限带宽的模态分量 (Intrinsic Mode Functions, IMFs),并最小化模态带宽之和。
VMD的分解步骤如下:
step2.1 构造
首先需要进行变分问题的构造以获得各个模态分量的解析信号,常见的方法就是进行希尔伯特变换(Hilbert Transform),是在信号处理中将实信号转换为解析信号,转换的过程如下:
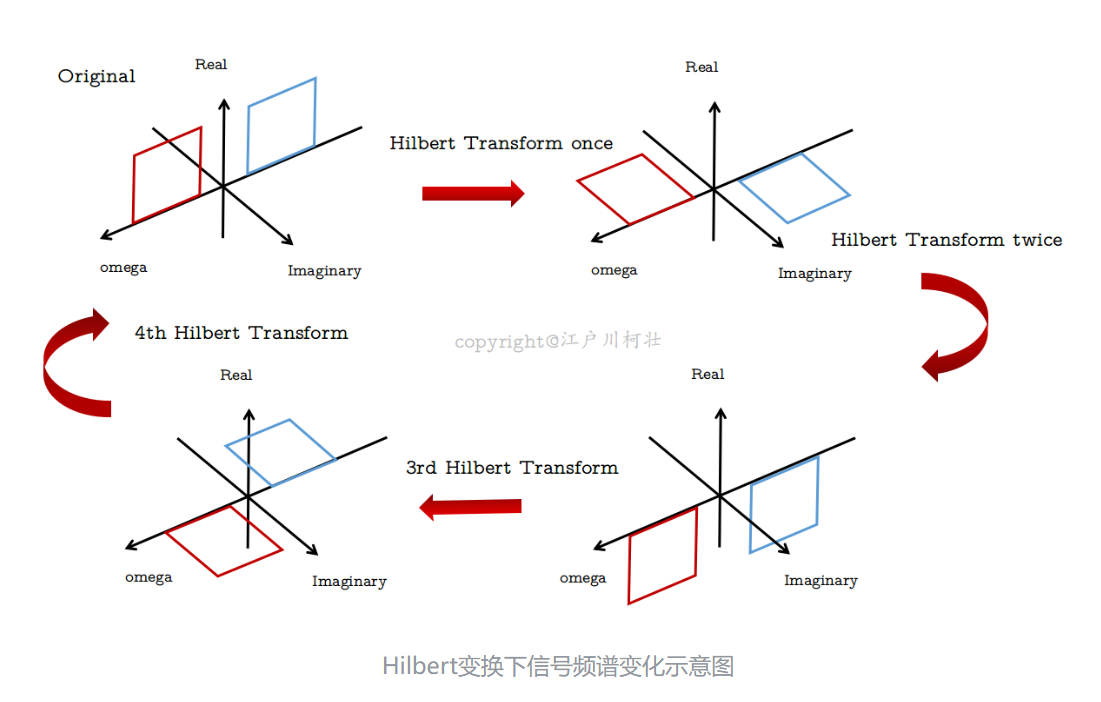
信号的变化如下:
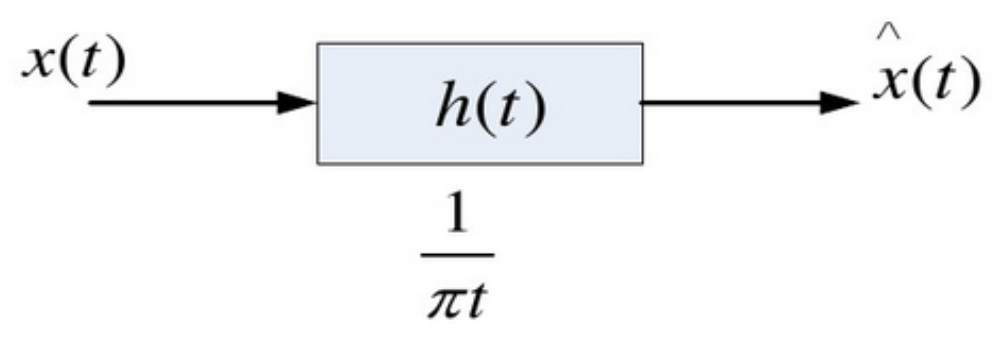
step2.2 求解
为了将上述约束性转化为非约束性变分问题,引入二次惩罚因子和拉格朗日乘法算子,采用乘法算子交替方向法进行求解
交替方向乘子法(ADMM)通常用于解决存在两个优化变量的等式约束优化类问题
假设增广拉格朗日函数定义如下:
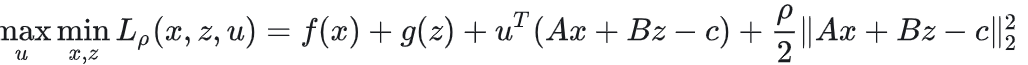
简单来说,就是轮流将增广拉格朗日的参数进行交替重复更新
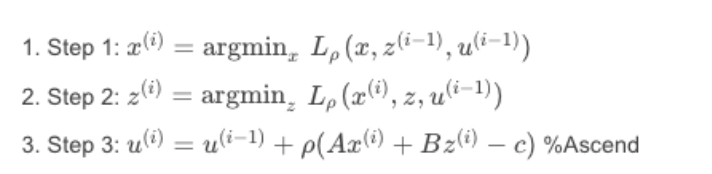
基于注意力的深度学习模型
(1)趋势预测
该文献中采用ARIMA方法进行滑坡位移的趋势预测
ARIMA方法包含:自回归部分(AR)、积分部分和移动平均部分(MA)
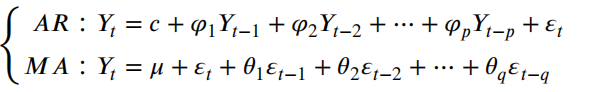
ARIMA方法详细的推导在前面的周报中已有体现
(2)季节性预测
该文献中采用CNN进行滑坡位移的季节性预测
本文中提出的CNN-Attention-GRU模型如下:
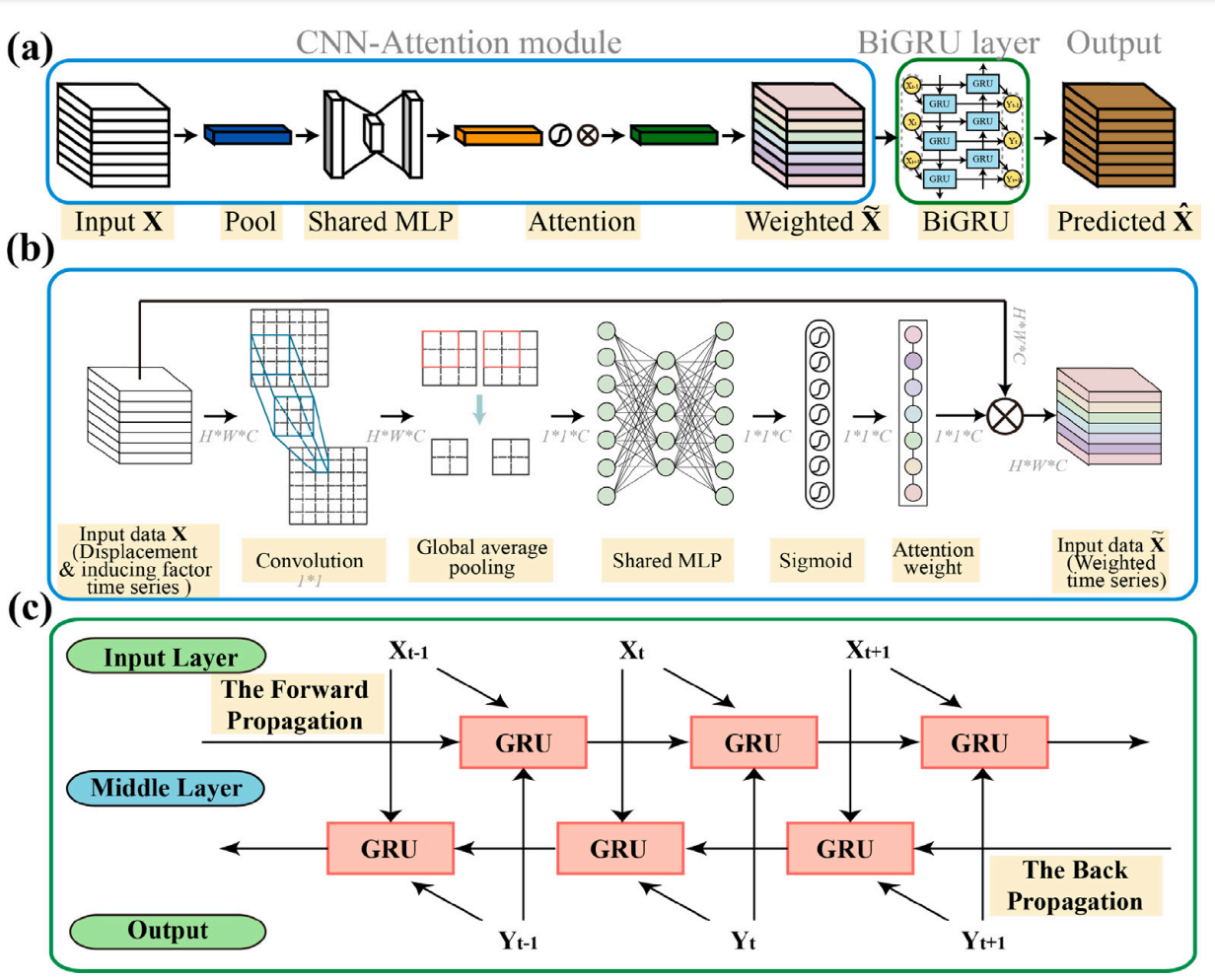
其中CNN用来提取局部有效特征,自注意力机制用来获取全局特征,BiGRU凭借未来和过去的数据来实现时间序列的预测。
上述模型的各个部分的原理在前面的周报中也有所体现。
可解释性方法
可解释性方法,是不同与传统的“黑箱”模型难以看出模型内部的决策方法,它是一种能够提供模型内部决策方法、特征重要性及模型输出结果背后逻辑的方法。 在很多应用场景之下,仅仅提高模型的准确度是不够的,还需要用户来了解模型的决策依据以此来确保其准确性和可靠性。具体细分以下三种方法:全局可解释性方法、局部可解释性方法、可视化方法
文中采用以下几种方法来增强模型的可解释性:
1、注意力机制
在 CNN-Attention-BiGRU 模型中,注意力机制为不同特征分配权重。其通过 CNN-Attention 卷积层输出通道注意力权重,突出重要通道特征。
2、时间序列分解
运用变分模态分解(VMD)将 InSAR 获取的滑坡位移时间序列分解为趋势项、季节项和残差项。
3、模型输入因素分析
在预测滑坡位移时,收集多种影响因素数据,并分类为不同序列。通过灰色关联分析(GRA)验证这些因素与滑坡位移变化的相关性。
创新点
CNN-Attention-BiGRU模型
提出 CNN-Attention-BiGRU 模型,结合 CNN 强大的特征提取能力、注意力机制对重要特征的聚焦能力以及 BiGRU 处理时间序列的优势,有效捕捉滑坡变形与触发因素间的非线性关系
变分模态分解
采用变分模态分解(VMD)技术将滑坡位移时间序列分解为趋势、季节和噪声成分,从而更好地解释滑坡的长期和短期行为。
模型的可解释性
引入注意力机制为模型赋予可解释性。通过分析注意力权重,明确影响滑坡位移预测的关键因素及重要时段,如每年 4 - 8 月对滑坡位移影响较大,揭示了触发因素与滑坡变形间的动态关系,克服了深度学习模型 “黑箱” 问题,使预测结果更具可靠性和说服力。
实验研究
数据集
在 InSAR 数据方面,收集 2016 年 3 月至 2022 年 6 月哥白尼哨兵 1 号的 168 幅 SAR 图像,结合 30 米分辨率的哥白尼 DEM 进行处理,获取滑坡位移时间序列;同时,收集新浦雨量站降雨数据和三峡水库每日 RWL 数据,并整理成不同时间尺度的累积降水量、平均 RWL 及变化量等,作为模型预测季节性位移的输入;此外,还选取 GNSS 站在新浦滑坡上的变形数据,与 InSAR 数据交叉对比,验证 InSAR 监测结果的准确性 。
模型训练与预测
位移时间序列的分解
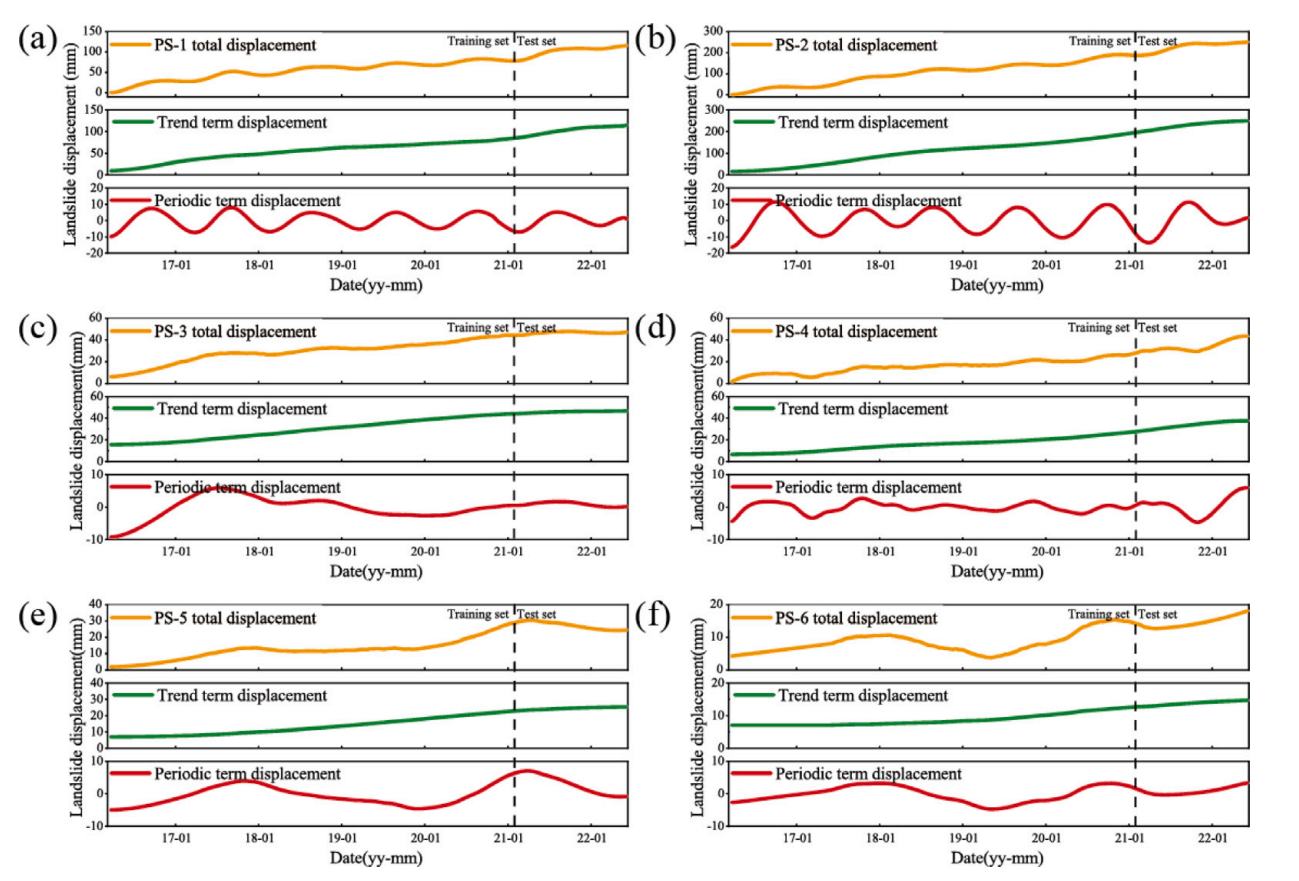 结论:趋势位移比较平稳,说明滑坡在持续发生位移并且发展态势很稳定;周期位移波动较大,说明滑坡位移受季节性或周期性因素影响。总位移既包含了长期增长的趋势成分,又体现了周期性波动成分。
结论:趋势位移比较平稳,说明滑坡在持续发生位移并且发展态势很稳定;周期位移波动较大,说明滑坡位移受季节性或周期性因素影响。总位移既包含了长期增长的趋势成分,又体现了周期性波动成分。
趋势和季节成分的预测
趋势成分预测结果如下:
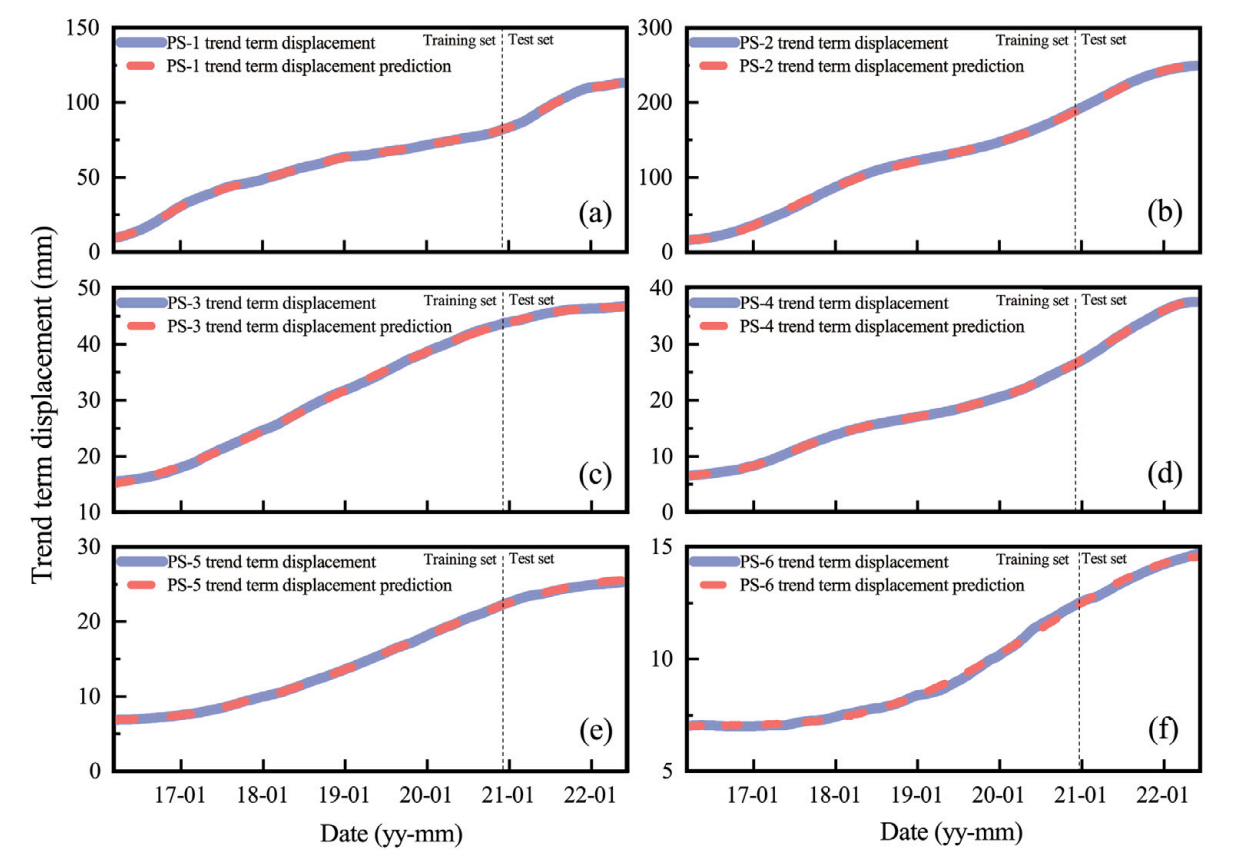 结论:红色的预测曲线与蓝色的实际趋势项位移曲线整体拟合较好,表明预测模型能较好捕捉趋势项位移的变化规律。在训练集阶段,两者贴合紧密,说明模型在训练过程中能有效学习趋势项位移特征 。
结论:红色的预测曲线与蓝色的实际趋势项位移曲线整体拟合较好,表明预测模型能较好捕捉趋势项位移的变化规律。在训练集阶段,两者贴合紧密,说明模型在训练过程中能有效学习趋势项位移特征 。
灰色关联度分析:
灰色关联度分析是一种多因素统计分析方法 。当数据量少、信息不完全明确时,该方法能有效揭示因素间的关联关系。
在滑坡研究领域,灰色关联度分析可用于确定影响滑坡位移的关键因素。比如将滑坡位移数据作为参考数列,降雨、地下水位、地震活动等因素数据作为比较数列,通过计算关联度,找出与滑坡位移关联程度高的因素。
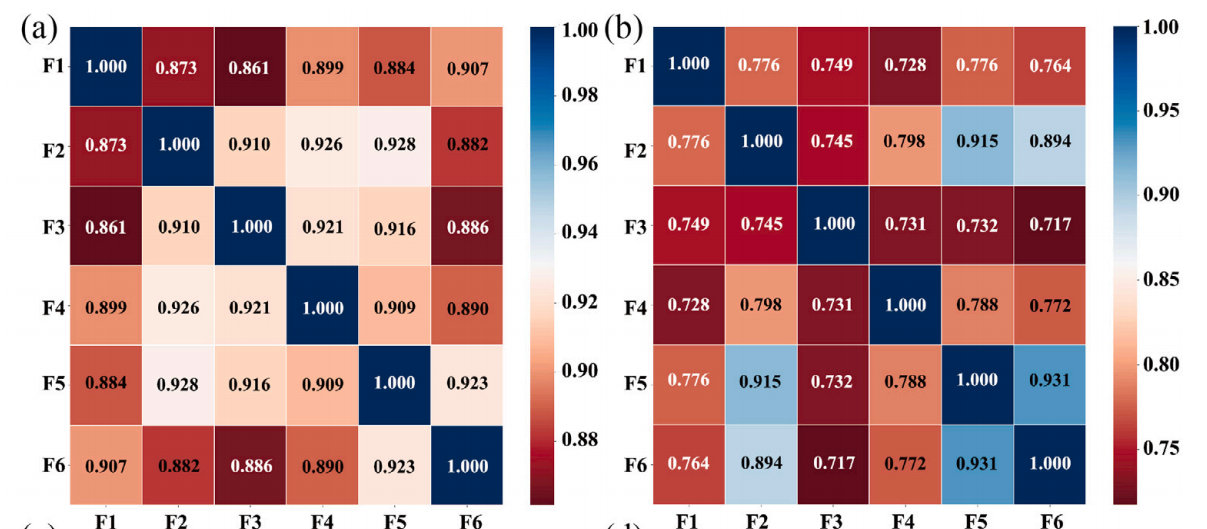
左边关系图中特征相关性普遍较高,而右边特征相关性较弱。
滑坡位移的时间序列组成
其累积时间序列是由趋势成分时间序列和季节成分时间序列相加而成的。
结果评估
稳健性评估
(1)多次预测验证
多次预测选定散射点(如 PS - 1 和 PS - 2 )的周期性分量和总滑坡运动。结果显示,不同预测结果均在真实位移附近一定范围内波动,未出现较大偏差,证明模型预测结果具有稳定性,在多次预测中表现较为可靠,能够稳定反映滑坡位移情况。
(2)调整策略对比
调整时间序列分解策略进行实验,对比不同策略下模型预测效果。尽管新策略误差稍大,但仍能有效捕捉滑坡运动特征,且符合深度学习时间序列预测标准做法。这表明模型在不同数据处理策略下,仍具备一定预测能力,对数据处理方式变化有一定适应性,侧面体现了模型的稳健性。
CNN-attention模型特征权重的特性
(1)对触发因素特征的聚焦
注意力机制为输入的触发因素特征赋予权重,从而突出对滑坡位移预测起关键作用的因素。通过通道注意力权重,能清晰呈现各因素在不同时段的重要程度。如在每年 4 - 8 月,降水和水库水位(RWL)相关特征权重较高,这是因为该时段降水和 RWL 波动大,对滑坡活动影响显著。
(2)体现触发因素与滑坡变形的动态关系
不同时段触发因素特征权重的变化,反映了其与滑坡变形间的动态关联。在 4 - 8 月,降水和 RWL 权重高,说明此时它们对滑坡位移影响大;而在其他月份,一些特征权重降低,凸显了触发因素影响程度的季节性差异,有助于深入理解滑坡位移变化的内在机制。
时间序列预处理
该部分学习了时间序列预处理的几种方法,并进行了代码实践
缺失值的插值法
以air passenger数据集为例
数据格式处理
import pandas as pd# 定义月份映射
month_map = {'January': '01','February': '02','March': '03','April': '04','May': '05','June': '06','July': '07','August': '08','September': '09','October': '10','November': '11','December': '12'
}df = pd.read_csv('AirPassengers.csv') # 读取CSV文件df['month'] = df['month'].map(month_map) # 应用映射转换月份列
df['Date'] = pd.to_datetime(df['year'].astype(str) + '-' + df['month'].astype(str)) # 合并年和月列为日期格式,格式为 'YYYY-MM'
df.drop(['year', 'month'], axis=1, inplace=True) # 删除原始的年和月列
df.rename(columns={'passengers': 'Passengers'}, inplace=True) # 重命名乘客列(如果需要)
df.to_csv('transformed_data.csv', index=False) # 保存到新的CSV文件,如果需要
print(df) # 显示结果#数据时间列转换为日期时间数据类型
df['Date'] = pd.to_datetime(df['Date'])
df.sort_values(by=['Date'], inplace=True, ascending=True)
print(df)
要将时间数据先整合为“xx-yy”格式的数据时间,再将数据时间转换为日期时间的数据类型
绘制插补前的缺失的时间序列图
from matplotlib.pyplot import figure
import matplotlib.pyplot as plt#绘制插补前的数据分布
figure(figsize=(12, 5), dpi=80, linewidth=10)
plt.plot(df['Date'], df['Passengers'])
plt.title('Air Passengers Raw Data with Missing Values')
plt.xlabel('Years', fontsize=14)
plt.ylabel('Number of Passengers', fontsize=14)
plt.show() 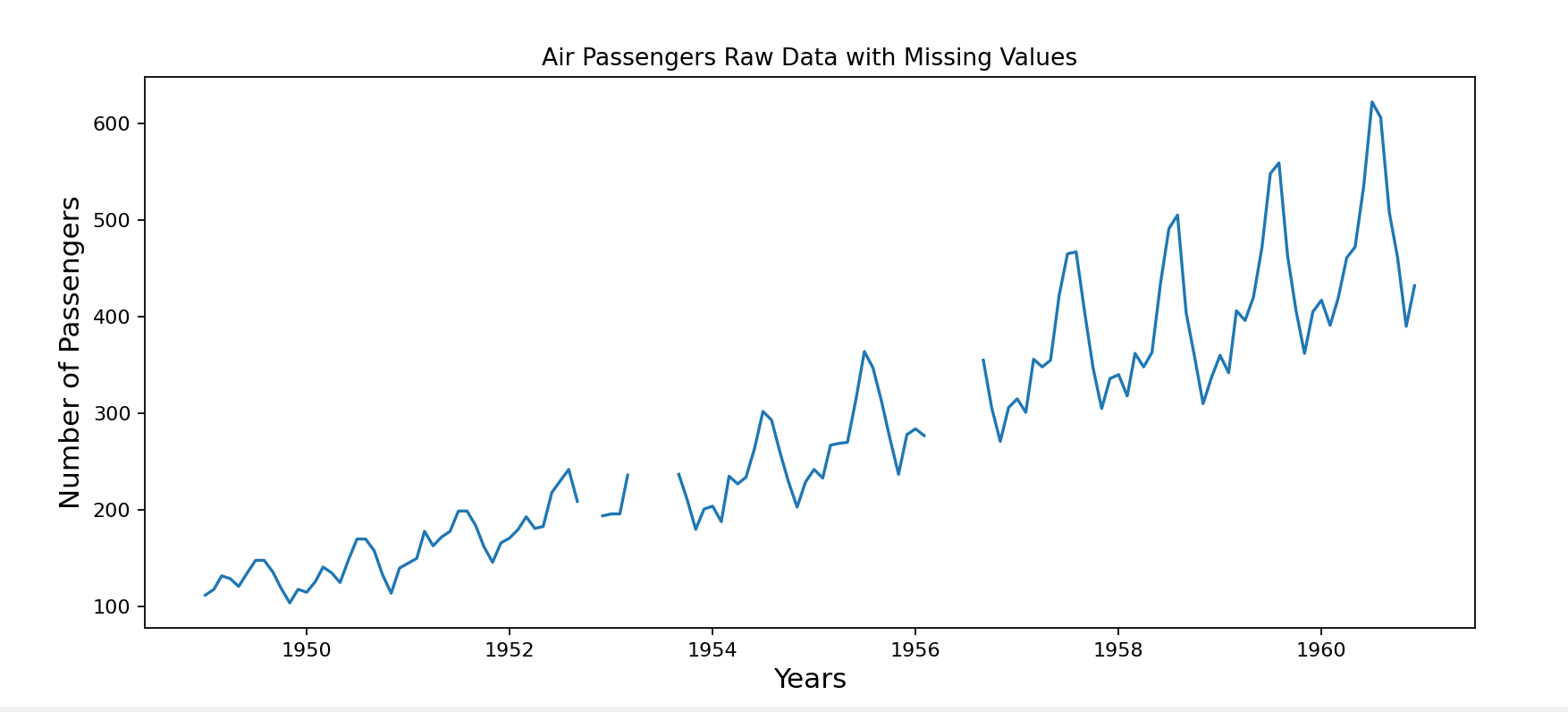
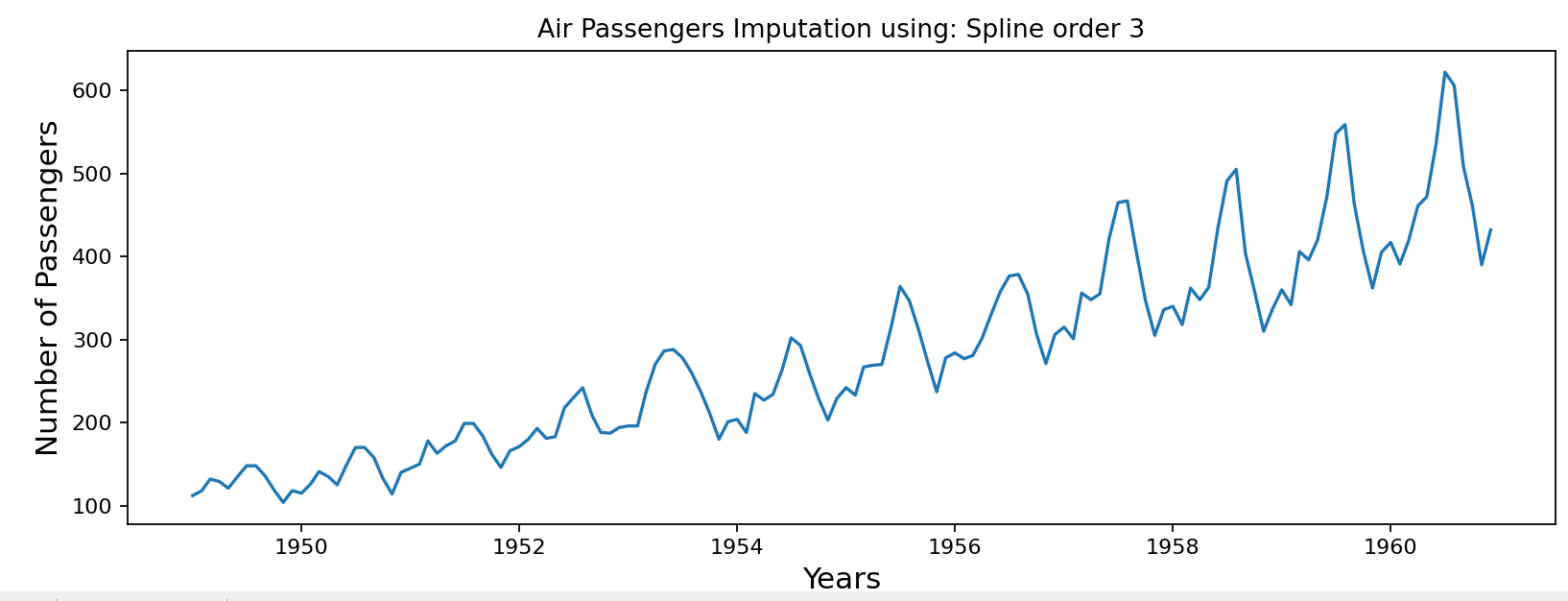
采用线性插值和样条插值进行数据补齐
#绘制2种方法插补后的数据分布
df['Linear'] = df['Passengers'].interpolate(method='linear') #线性插值
df['Spline order 3'] = df['Passengers'].interpolate(method='spline', order = 3) #样条插值methods = ['Linear', 'Spline order 3']from matplotlib.pyplot import figure
import matplotlib.pyplot as pltfor method in methods:figure(figsize=(12, 4), dpi=80, linewidth=10)plt.plot(df["Date"], df[method])plt.title('Air Passengers Imputation using: '+ method)plt.xlabel("Years", fontsize=14)plt.ylabel("Number of Passengers", fontsize=14)plt.show() 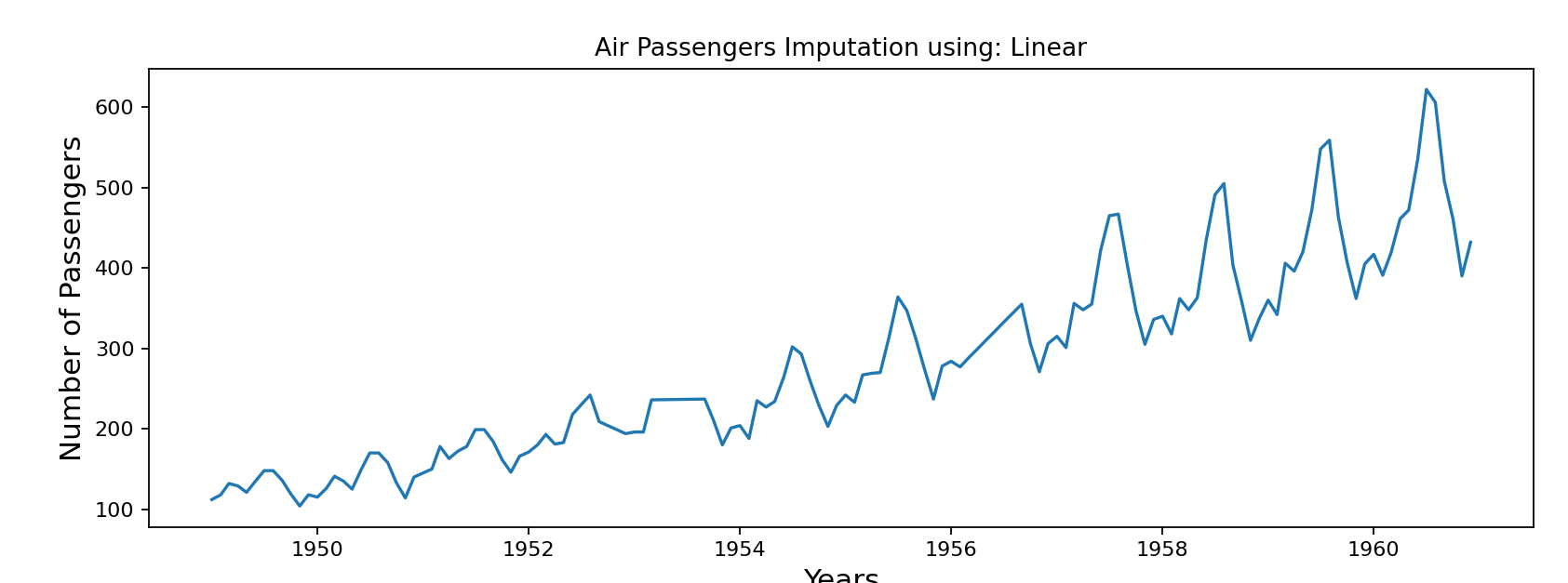
平滑处理
加载数据集并展现波动
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import scipy.stats as stats
from scipy.signal import savgol_filter
import plotly.express as px
from statsforecast import StatsForecast
from tqdm.autonotebook import tqdm#加载数据集并展现波动
train = pd.read_csv('M4-Hourly.csv')
uid = np.array(['H386'])
df_train = train.query('unique_id in @uid')
fig=StatsForecast.plot(df_train, plot_random = False, engine='plotly')
fig.show() 
4种平滑结果的比较
#4种平滑的比较
computed_features = [] # I will need this list to plot later the smoothed series
for window_size in [10, 25]:df_train.loc[:,f'moving_average_{window_size}'] = df_train['y'].rolling(window=window_size, center=True).mean()df_train.loc[:,f'savgol_filter_{window_size}'] = savgol_filter(df_train['y'], window_size, 2)computed_features.append(f'moving_average_{window_size}')computed_features.append(f'savgol_filter_{window_size}')print(df_train.tail(30))
 原始数据和平滑后数据对比
原始数据和平滑后数据对比
# 绘制原始数据和平滑后的数据进行比较
plt.figure(figsize=(15, 7))
plt.plot(df_train['y'], label='Original', color='gray')for feature in computed_features:plt.plot(df_train[feature], label=feature)plt.legend()
plt.savefig('./smooth_data/smooth.png')
plt.close() # 关闭图表,避免显示
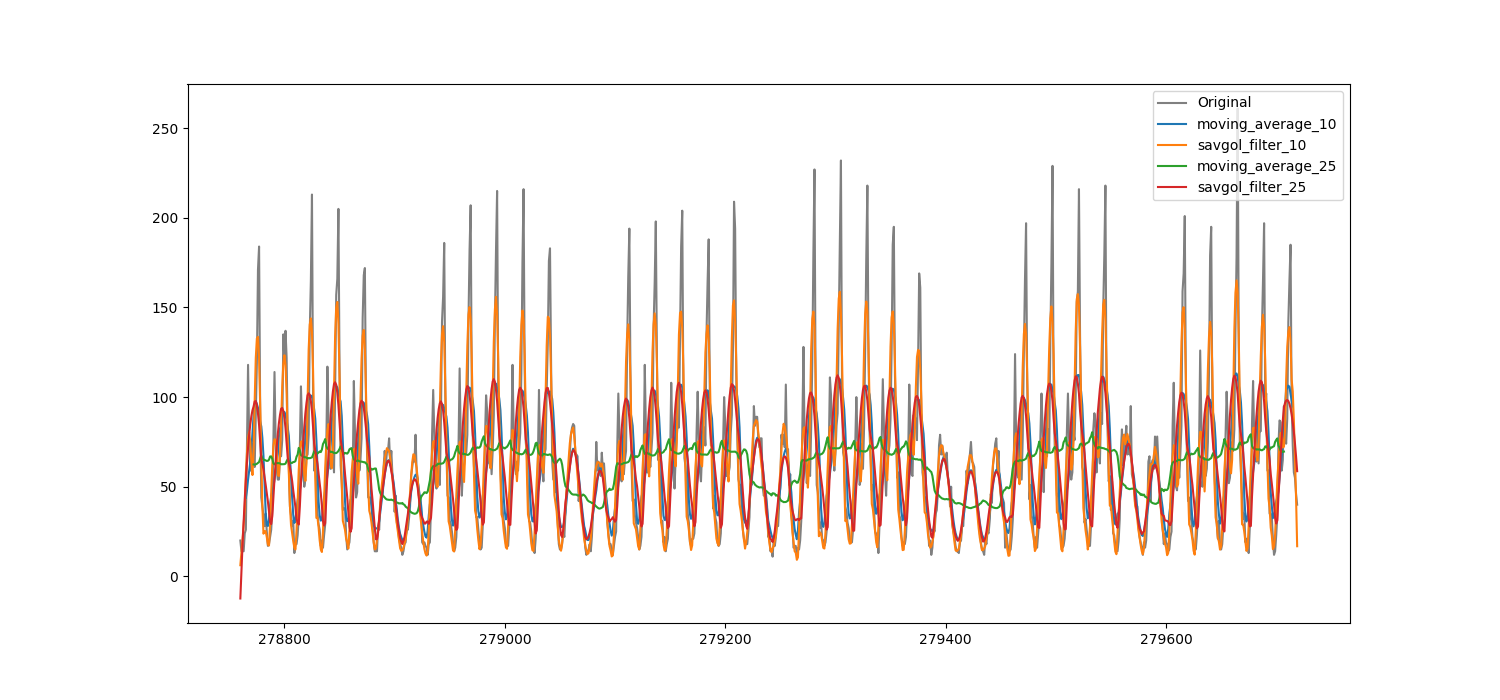
小结:Savitzky-Golay滤波器在适当调整窗口大小后,能够保持信号的高保真度,同时去除不必要的噪声和异常。尽管移动平均仍然可以用于计算时间序列的平均值,但同样的结果可以通过增大Savitzky-Golay滤波器的窗口大小(并且可能更精确)来实现。在大多数平滑应用中,Savitzky-Golay滤波器的表现要更好。
总结
本周阅读的文献,提出了CNN-Attention-BiGRU的深度学习模型,加入了自注意力机制和门控机制后,提高滑坡位移预测的准确性和可解释性。并且了解到了什么是模型的可解释性,以及通过何种方式能够提高其可解释性。最后,由于文中出现了时间序列的分解和预处理,所以更进一步学习了VMD分解方法,以及预处理的方法——插值处理缺失值和平滑。