一、引言
Java 集合框架是 Java 开发中不可或缺的基础组件,它提供了数据存储、检索和操作的高效机制。从List、Set到Map,再到Queue和Stack,每种集合都有特定的使用场景。然而,很多开发者在实际使用时,容易陷入性能、线程安全、内存占用等问题的陷阱。
二、集合框架核心概念
1. Collection 接口(存储单个元素)
• List(有序、可重复)
• ArrayList
基于数组,查询快,插入和删除慢
• LinkedList
基于链表,适用于频繁插入和删除,查询性能较低
注:
在尾部插入时,性能与ArrayList相近(无需遍历链表),
但中间插入仍需遍历,应根据实际场景选择合适的数据结构。
• Set(无序、不可重复)
• HashSet
基于HashMap,查询快但无序
• TreeSet
基于红黑树,支持排序
• LinkedHashSet
插入有序,基于LinkedHashMap
• Queue/Deque(FIFO/LIFO)
注:
Stack类为遗留类,推荐使用Deque接口的实现(如ArrayDeque)来替代栈功能。
• PriorityQueue
基于小顶堆,适合优先级任务
• ArrayDeque
双端队列,高效插入删除
• ConcurrentLinkedQueue
线程安全队列
2.Map 接口(键值对存储)
• HashMap(无序,查询快)
• TreeMap(基于红黑树,有序存储)
• LinkedHashMap(按插入顺序排序)
• ConcurrentHashMap(高并发推荐)
三、高频问题与解决方案
1. List 的选型问题
场景:大量随机访问数据
推荐:ArrayList,查询操作快
避免:LinkedList,链表结构导致get(index)变慢
场景:频繁插入删除数据
推荐:LinkedList,插入删除快
避免:ArrayList,插入删除会触发元素移动
2. HashMap 并发问题
问题:
在多线程环境下,HashMap可能导致数据不一致或死循环问题(JDK 1.7)。JDK 1.8 已通过改为尾插法解决死循环问题,但HashMap依然不具备线程安全性。
解决方案:
在多线程环境中,应使用ConcurrentHashMap替代HashMap,以确保线程安全和数据一致性。
3. Set 选型
问题:
如何高效去重?
解决方案:
• 无序去重:使用HashSet,提供 O(1) 查找效率。
• 有序去重:使用TreeSet,提供 O(log n) 查找效率,保持元素有序。
• 并发去重:使用ConcurrentSkipListSet,适用于高并发场景。
• 线程安全的无序 Set:通过ConcurrentHashMap.newKeySet()创建,适用于无需排序的并发场景。
4. 线程安全的集合
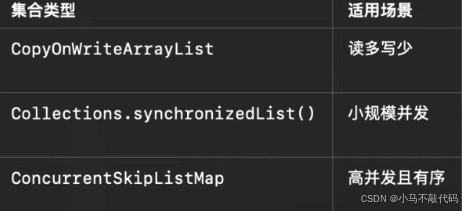
5. 避免扩容带来的性能开销
问题:HashMap插入大量数据时,频繁扩容导致性能下降
解决方案:初始化时设置合理的initialCapacity,减少扩容开销
四、集合框架实战指南
在实际开发中,合理使用集合框架可以极大提升系统的性能和可扩展性。以下是两个高并发场景下的优化方案,避免常见的集合陷阱,并提升系统稳定性。
1. 商品推荐系统(百万级数据统计)
问题:
• 直接使用HashMap记录商品浏览/购买次数,可能导致频繁扩容,影响性能。
• 多线程更新时,可能出现线程安全问题,导致数据统计不准确。
优化方案:
• 预估initialCapacity,避免HashMap频繁扩容。
• 使用ConcurrentHashMap 和 AtomicInteger,保证多线程安全。
优化代码示例:
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.atomic.AtomicInteger;
import java.util.Map;public class ProductRecommendation {public static void main(String[] args) {// 预估商品种类数,例如 200 种,按负载因子 0.75 计算初始容量int initialCapacity = (int) Math.ceil(200 / 0.75); // 267// 线程安全的商品浏览计数器Map<String, AtomicInteger> productViews = new ConcurrentHashMap<>(initialCapacity);// 初始化某个商品的浏览计数productViews.putIfAbsent("product_123", new AtomicInteger(0));// 多线程环境下安全递增productViews.get("product_123").incrementAndGet();// 获取某个商品的浏览次数System.out.println("Product 123 views: " + productViews.get("product_123").get());}
}
优化效果:
• 避免了HashMap扩容的开销,提高了查询效率。
• 通过AtomicInteger确保高并发环境下的数据一致性。
高并发量优化建议:
• 对于非常高并发的场景,考虑使用LongAdder替代AtomicInteger,它在并发写入频繁时表现更好,能够减少 CPU 的竞争,提升性能。
• 若并发量极高,可以使用ConcurrentHashMap的merge()或computeIfAbsent()方法来简化并发更新的操作,并避免额外的同步控制。
2. 热点搜索词统计(千万级数据)
问题:
• TreeSet排序效率较低,适合小数据规模。
• 查找 Top-K 时性能受限。
优化方案:
• 使用HashMap统计词频,查找效率 O(1)。
• 使用PriorityQueue(小顶堆)维护 Top-K,插入效率 O(log K)。
优化代码:
import java.util.*;public class HotSearchTracker {private static final int TOP_K = 10; // 维护前10个高频搜索词private final Map<String, Integer> searchFrequency = new HashMap<>();private final PriorityQueue<String> topKHeap;private final Set<String> topKSet; // 用于快速判断是否在堆中public HotSearchTracker() {// 小顶堆,按照搜索词频率排序this.topKHeap = new PriorityQueue<>(Comparator.comparingInt(searchFrequency::get));this.topKSet = new HashSet<>();}public void recordSearch(String keyword) {// 更新搜索词频次searchFrequency.put(keyword, searchFrequency.getOrDefault(keyword, 0) + 1);// 维护 Top-K 关键词if (topKSet.contains(keyword)) {topKHeap.remove(keyword); // 移除旧数据,避免频率更新后堆排序失效topKSet.remove(keyword);}topKHeap.offer(keyword);topKSet.add(keyword);if (topKHeap.size() > TOP_K) {String removed = topKHeap.poll(); // 维持堆大小topKSet.remove(removed);}}public List<String> getTopKSearches() {List<String> result = new ArrayList<>(topKHeap);result.sort(Comparator.comparingInt(searchFrequency::get).reversed()); // 按词频排序return result;}public static void main(String[] args) {HotSearchTracker tracker = new HotSearchTracker();tracker.recordSearch("java");tracker.recordSearch("java");tracker.recordSearch("python");tracker.recordSearch("java");tracker.recordSearch("c++");tracker.recordSearch("python");tracker.recordSearch("go");System.out.println("Top search keywords: " + tracker.getTopKSearches());}
}
优化效果:
• HashMap:用于统计词频,查询时间为 O(1),避免了频繁的扩容开销。
• PriorityQueue:维护 Top-K 高频搜索词,插入和删除操作时间复杂度为 O(log K),适合高效地维护排名数据。
总结
这两个案例展示了如何利用ConcurrentHashMap和AtomicInteger实现高并发计数,以及利用HashMap和PriorityQueue进行高效的 Top-K 统计。
• 商品推荐系统:通过预估初始容量避免扩容,提高了计数的稳定性。
• 热点搜索统计:使用小顶堆优化 Top-K 计算,提升了大数据量处理的效率。
五、总结
1. 选型黄金法则
• 读多写少:ArrayList
• 写多读少:LinkedList
• 高并发读写:ConcurrentHashMap
• 需要排序:TreeSet(小规模)或 PriorityQueue(Top-K)
2.性能优化技巧
• 避免扩容成本,合理设置初始容量
• 高并发计数用LongAdder代替AtomicInteger
• PriorityQueue适用于动态 Top-K 统计
• 内存敏感场景优先使用ArrayList
• ConcurrentLinkedQueue替代LinkedList以避免锁竞争
3. 避坑 Checklist
• entrySet()遍历比keySet()快 30%。
• ConcurrentHashMap.size()是 O(n),避免在循环中调用。
• 高性能优化库推荐:FastUtil、Koloboke(数据量 100 万+)。