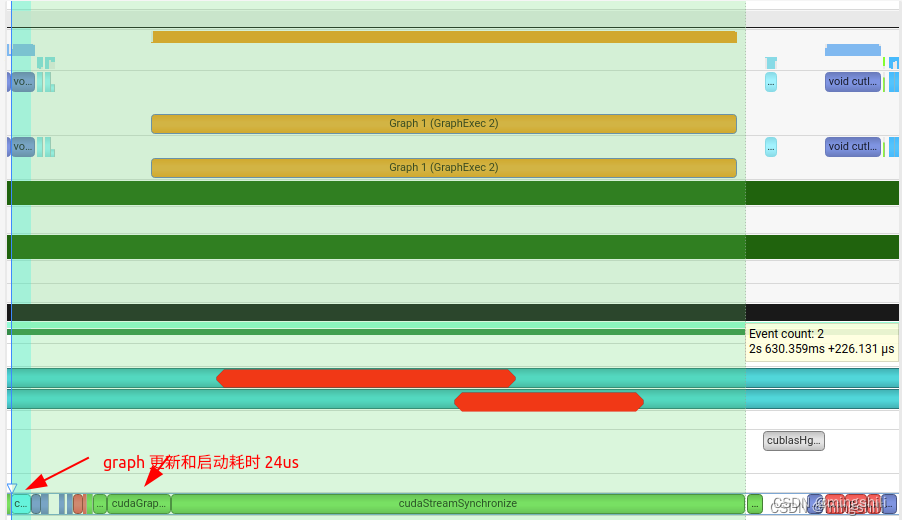
cuda graph在一个kernel要多次执行,且每次只更改kernel 参数或者不更改参数时使用效果更加;但是如果将graph替换已有的kernel组合,且没有重复执行,感觉效率不是很高反而低于原始的kernel调用;【此外, graph启动还需要耗时】 基本范式, 通过start capture 和end Capture 以及 构建graph exec方式实现graph执行,效率不高;用于graph多次执行的情况。ref: cuda_sample: jacobi 不需要GraphCreate 一个graph对象。cudaStreamEndCapture 会直接创建一个graph。 checkCudaErrors ( cudaStreamBeginCapture ( stream, cudaStreamCaptureModeGlobal) ) ; checkCudaErrors ( cudaMemsetAsync ( d_sum, 0 , sizeof ( double ) , stream) ) ; if ( ( k & 1 ) == 0 ) { JacobiMethod<< < nblocks, nthreads, 0 , stream>> > ( A, b, conv_threshold, x, x_new, d_sum) ; } else { JacobiMethod<< < nblocks, nthreads, 0 , stream>> > ( A, b, conv_threshold, x_new, x, d_sum) ; } checkCudaErrors ( cudaMemcpyAsync ( & sum, d_sum, sizeof ( double ) , cudaMemcpyDeviceToHost, stream) ) ; checkCudaErrors ( cudaStreamEndCapture ( stream, & graph) ) ; if ( graphExec == NULL ) { checkCudaErrors ( cudaGraphInstantiate ( & graphExec, graph, NULL , NULL , 0 ) ) ; } else { cudaGraphExecUpdateResult updateResult_out; checkCudaErrors ( cudaGraphExecUpdate ( graphExec, graph, NULL , & updateResult_out) ) ; if ( updateResult_out != cudaGraphExecUpdateSuccess) { if ( graphExec != NULL ) { checkCudaErrors ( cudaGraphExecDestroy ( graphExec) ) ; } printf ( "k = %d graph update failed with error - %d\n" , k, updateResult_out) ; checkCudaErrors ( cudaGraphInstantiate ( & graphExec, graph, NULL , NULL , 0 ) ) ; } } checkCudaErrors ( cudaGraphLaunch ( graphExec, stream) ) ; checkCudaErrors ( cudaStreamSynchronize ( stream) ) ;
class MyCudaGraph { public: CudaGraph ( ) : graph_ ( nullptr) , graph_instance_ ( nullptr) , stream_ ( nullptr) , is_captured_ ( false) { RPV_CUDA_CHECK ( cudaGraphCreate ( & graph_, 0 ) ) ; } ~ CudaGraph ( ) { if ( graph_ != nullptr) { RPV_CUDA_CHECK ( cudaGraphDestroy ( graph_) ) ; } if ( graph_instance_ != nullptr) { RPV_CUDA_CHECK ( cudaGraphExecDestroy ( graph_instance_) ) ; } } void set_stream ( const cudaStream_t & stream) { stream_ = stream; } const cudaGraph_t & graph ( ) const { return graph_; } const cudaGraphExec_t & graph_instance ( ) const { return graph_instance_; } void CaptureStart ( ) const { RPV_CUDA_CHECK ( cudaStreamBeginCapture ( stream_, cudaStreamCaptureModeGlobal) ) ; } void CaptureEnd ( ) const { RPV_CUDA_CHECK ( cudaStreamEndCapture ( stream_, & graph_) ) ; } bool IsCaptured ( ) const { return is_captured_; } void Launch ( ) const { if ( graph_instance_ == nullptr) { RPV_CUDA_CHECK ( cudaGraphInstantiate ( & graph_instance_, graph_, nullptr, nullptr, 0 ) ) ; } RPV_CUDA_CHECK ( cudaGraphLaunch ( graph_instance_, stream_) ) ; } void UpdateLaunch ( ) const { cudaGraphExecUpdateResult update_result; RPV_CUDA_CHECK ( cudaGraphExecUpdate ( graph_instance_, graph_, nullptr, & update_result) ) ; if ( update_result != cudaGraphExecUpdateSuccess) { if ( graph_instance_ != nullptr) { RPV_CUDA_CHECK ( cudaGraphExecDestroy ( graph_instance_) ) ; } LOG ( WARNING) << "cuda graph update failed." ; RPV_CUDA_CHECK ( cudaGraphInstantiate ( & graph_instance_, graph_, nullptr, nullptr, 0 ) ) ; } RPV_CUDA_CHECK ( cudaGraphLaunch ( graph_instance_, stream_) ) ; } void AddKernelNode ( cudaGraphNode_t & node, cudaKernelNodeParams& param) const { node_ = node; cudaGraphAddKernelNode ( & node_, graph_, nullptr, 0 , & param) ; } void ExecKernelNodeSetParams ( cudaKernelNodeParams& param) const { cudaGraphExecKernelNodeSetParams ( graph_instance_, node_, & param) ; RPV_CUDA_CHECK ( cudaGraphLaunch ( graph_instance_, stream_) ) ; } private: mutable cudaGraphNode_t node_; mutable cudaGraph_t graph_; mutable cudaGraphExec_t graph_instance_; mutable cudaStream_t stream_; mutable bool is_captured_; DISALLOW_COPY_AND_ASSIGN ( CudaGraph) ;
} ;
ref: cuda sample: jacobi 注意node的方式需要 构建每个node的依赖node。并且通过更新kernel param的方式来更新graph exec, 效率可能更高。但是 cudaGraph_t graph; cudaGraphExec_t graphExec = NULL ; double sum = 0.0 ; double * d_sum = NULL ; checkCudaErrors ( cudaMalloc ( & d_sum, sizeof ( double ) ) ) ; std:: vector< cudaGraphNode_t > nodeDependencies; cudaGraphNode_t memcpyNode, jacobiKernelNode, memsetNode; cudaMemcpy3DParms memcpyParams = { 0 } ; cudaMemsetParams memsetParams = { 0 } ; memsetParams. dst = ( void * ) d_sum; memsetParams. value = 0 ; memsetParams. pitch = 0 ; memsetParams. elementSize = sizeof ( float ) ; memsetParams. width = 2 ; memsetParams. height = 1 ; checkCudaErrors ( cudaGraphCreate ( & graph, 0 ) ) ; checkCudaErrors ( cudaGraphAddMemsetNode ( & memsetNode, graph, NULL , 0 , & memsetParams) ) ; nodeDependencies. push_back ( memsetNode) ; cudaKernelNodeParams NodeParams0, NodeParams1; NodeParams0. func = ( void * ) JacobiMethod; NodeParams0. gridDim = nblocks; NodeParams0. blockDim = nthreads; NodeParams0. sharedMemBytes = 0 ; void * kernelArgs0[ 6 ] = { ( void * ) & A, ( void * ) & b, ( void * ) & conv_threshold, ( void * ) & x, ( void * ) & x_new, ( void * ) & d_sum} ; NodeParams0. kernelParams = kernelArgs0; NodeParams0. extra = NULL ; checkCudaErrors ( cudaGraphAddKernelNode ( & jacobiKernelNode, graph, nodeDependencies. data ( ) , nodeDependencies. size ( ) , & NodeParams0) ) ; nodeDependencies. clear ( ) ; nodeDependencies. push_back ( jacobiKernelNode) ; memcpyParams. srcArray = NULL ; memcpyParams. srcPos = make_cudaPos ( 0 , 0 , 0 ) ; memcpyParams. srcPtr = make_cudaPitchedPtr ( d_sum, sizeof ( double ) , 1 , 1 ) ; memcpyParams. dstArray = NULL ; memcpyParams. dstPos = make_cudaPos ( 0 , 0 , 0 ) ; memcpyParams. dstPtr = make_cudaPitchedPtr ( & sum, sizeof ( double ) , 1 , 1 ) ; memcpyParams. extent = make_cudaExtent ( sizeof ( double ) , 1 , 1 ) ; memcpyParams. kind = cudaMemcpyDeviceToHost; checkCudaErrors ( cudaGraphAddMemcpyNode ( & memcpyNode, graph, nodeDependencies. data ( ) , nodeDependencies. size ( ) , & memcpyParams) ) ; checkCudaErrors ( cudaGraphInstantiate ( & graphExec, graph, NULL , NULL , 0 ) ) ; NodeParams1. func = ( void * ) JacobiMethod; NodeParams1. gridDim = nblocks; NodeParams1. blockDim = nthreads; NodeParams1. sharedMemBytes = 0 ; void * kernelArgs1[ 6 ] = { ( void * ) & A, ( void * ) & b, ( void * ) & conv_threshold, ( void * ) & x_new, ( void * ) & x, ( void * ) & d_sum} ; NodeParams1. kernelParams = kernelArgs1; NodeParams1. extra = NULL ; int k = 0 ; for ( k = 0 ; k < max_iter; k++ ) { checkCudaErrors ( cudaGraphExecKernelNodeSetParams ( graphExec, jacobiKernelNode, ( ( k & 1 ) == 0 ) ? & NodeParams0 : & NodeParams1) ) ; checkCudaErrors ( cudaGraphLaunch ( graphExec, stream) ) ; checkCudaErrors ( cudaStreamSynchronize ( stream) ) ; if ( sum <= conv_threshold) { checkCudaErrors ( cudaMemsetAsync ( d_sum, 0 , sizeof ( double ) , stream) ) ; nblocks. x = ( N_ROWS / nthreads. x) + 1 ; size_t sharedMemSize = ( ( nthreads. x / 32 ) + 1 ) * sizeof ( double ) ; if ( ( k & 1 ) == 0 ) { finalError<< < nblocks, nthreads, sharedMemSize, stream>> > ( x_new, d_sum) ; } else { finalError<< < nblocks, nthreads, sharedMemSize, stream>> > ( x, d_sum) ; } checkCudaErrors ( cudaMemcpyAsync ( & sum, d_sum, sizeof ( double ) , cudaMemcpyDeviceToHost, stream) ) ; checkCudaErrors ( cudaStreamSynchronize ( stream) ) ; printf ( "GPU iterations : %d\n" , k + 1 ) ; printf ( "GPU error : %.3e\n" , sum) ; break ; } } 对比发现 graph 反而耗时更长 官方其他实例,通过更新值 ref: mandrake: wtsne_gpu capture_stream. capture_start ( ) ; wtsneUpdateYKernel< real_t > << < block_count, block_size, 0 , capture_stream. stream ( ) >> > ( device_ptrs. rng, get_node_table ( ) , get_edge_table ( ) , device_ptrs. Y, device_ptrs. I, device_ptrs. J, device_ptrs. Eq, device_ptrs. qsum, device_ptrs. qcount, device_ptrs. nn, device_ptrs. ne, eta0, nRepuSamp, device_ptrs. nsq, bInit, iter_d. data ( ) , maxIter, device_ptrs. n_workers, n_clashes_d. data ( ) ) ; cub:: DeviceReduce:: Sum ( qsum_tmp_storage_. data ( ) , qsum_tmp_storage_bytes_, qsum_. data ( ) , qsum_total_device_. data ( ) , qsum_. size ( ) , capture_stream. stream ( ) ) ; cub:: DeviceReduce:: Sum ( qcount_tmp_storage_. data ( ) , qcount_tmp_storage_bytes_, qcount_. data ( ) , qcount_total_device_. data ( ) , qcount_. size ( ) , capture_stream. stream ( ) ) ; update_eq< real_t > << < 1 , 1 , 0 , capture_stream. stream ( ) >> > ( device_ptrs. Eq, device_ptrs. nsq, qsum_total_device_. data ( ) , qcount_total_device_. data ( ) , iter_d. data ( ) ) ; capture_stream. capture_end ( graph. graph ( ) ) ; const auto start = std:: chrono:: steady_clock:: now ( ) ; for ( iter_h = 0 ; iter_h < maxIter; ++ iter_h) { graph. launch ( graph_stream. stream ( ) ) ; if ( iter_h % MAX ( 1 , maxIter / 1000 ) == 0 ) { Eq_device_. get_value_async ( & Eq_host_, graph_stream. stream ( ) ) ; n_clashes_d. get_value_async ( & n_clashes_h, graph_stream. stream ( ) ) ; real_t eta = eta0 * ( 1 - static_cast< real_t > ( iter_h) / ( maxIter - 1 ) ) ; check_interrupts ( ) ; graph_stream. sync ( ) ; update_progress ( iter_h, maxIter, eta, Eq_host_, write_per_worker, n_clashes_h) ; } if ( results-> is_sample_frame ( iter_h) ) { Eq_device_. get_value_async ( & Eq_host_, copy_stream. stream ( ) ) ; update_frames ( results, graph_stream, copy_stream, curr_iter, curr_Eq, iter_h, Eq_host_) ; } }
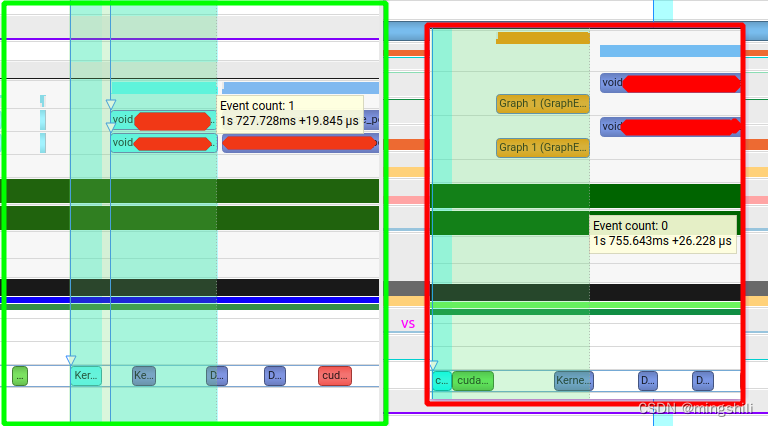
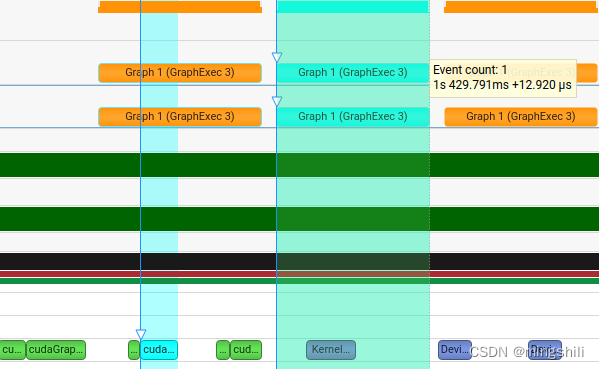
当连续执行graph多次,且存在kernel 参数更新的话,可以看到下一个graph启动与上一个graph执行存在并行,从而实现了graph的启动隐藏,并且graph执行要比kernel执行更加快,因此对于某个kernel重复执行多次且更改不大的情况下或者多流处理时,可以考虑用graph. 比如一些固定输入的kernel 需要多次执行,且可以用stream并行,那么可以考虑用graph来高效执行。 # if CUDA_VERSION < 12000 { } ; cudaGraphNode_t error_node = nullptr; OF_CUDA_CHECK ( cudaGraphExecUpdate ( graph_exec_, graph, & error_node, & update_result) ) ; if ( update_result == cudaGraphExecUpdateSuccess) { return ; }
# else { } ; OF_CUDA_CHECK ( cudaGraphExecUpdate ( graph_exec_, graph, & update_result) ) ; if ( update_result. result == cudaGraphExecUpdateSuccess) { return ; }
# endif