LRU Cache
LCR(Least Recently Used,最近最少使用)缓存是一种缓存替换算法,它的核心思想是:当缓存容量满了时,将最近最少使用的那部分数据剔除。这种策略基于一个直观的假设——过去不常使用的数据,在未来也不太可能被频繁访问。
这里的 Cache 指的是速度相差较大的两种硬件之间, 用于协调两者数据传输速度差异的结构。
作为一种数据结构,LRU Cache 主要是在代码中模拟硬件 Cache 的容量有限,当有新的数据需要添加到 Cache 中时,需要挑选出一部分内容舍弃,以此腾出空间存储新数据的特点。
1. LRU Cache的实现
实现 LRU Cache 的思路有很多种,但要确保查询和更新的时间复杂度都是 O ( 1 ) O(1) O(1) ,就得使用哈希表 + 双向链表的组合来实现。因为哈希表增删改查都是 O ( 1 ) O(1) O(1) ,当哈希表和双向链表绑定后,双向链表的插入和删除也是 O ( 1 ) O(1) O(1) 。
单链表不是 O ( 1 ) O(1) O(1) ,是因为单链表需要找到前后节点来重新链路,如果没有双向链路,就需要 O ( N ) O(N) O(N) 才能找到前驱或后驱节点。
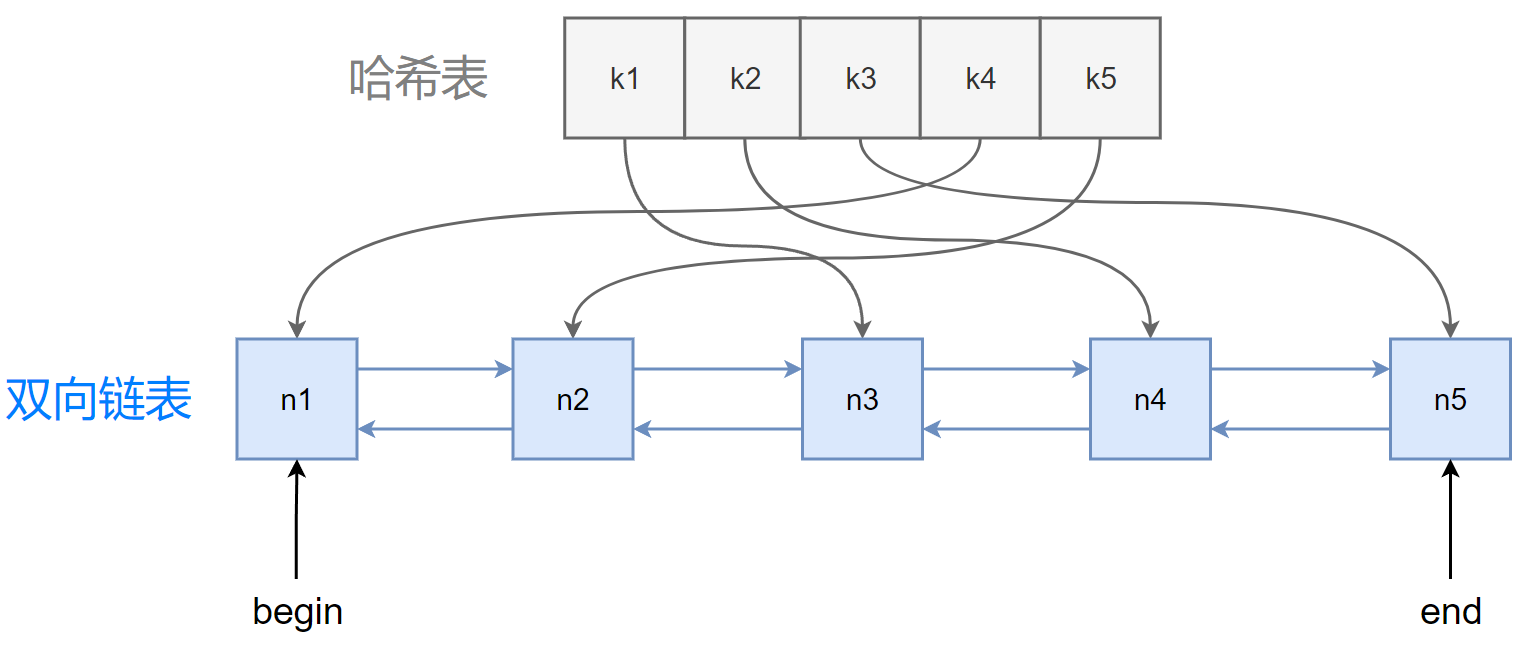
注意 splice() 接口,它能够将迭代器指向的节点移动到链表头部,即使高频访问的数据能够刷新到链表前端,又避免了迭代器失效。
#include <unordered_map>
#include <list>
using namespace std;class LRUCache
{LRUCache(int capacity): _capacity(capacity){}//查询int get(int key){auto ret = _hashMap.find(key);if (ret != _hashMap.end()){auto it = ret->second; //找到迭代器_LRUList.splice(_LRUList.begin(), _LRUList, it);return (*it).second;}else{return -1;}}//添加或更新void put(int key, int value){auto ret = _hashMap.find(key);if (ret == _hashMap.end()){if (_hashMap.size() == _capacity){_hashMap.erase(_LRUList.back().first);_LRUList.pop_back();}_LRUList.push_front(make_pair(key, value));_hashMap[key] = _LRUList.begin();}else{auto it = ret->second;it->second = value;_LRUList.splice(_LRUList.begin(), _LRUList, it);}}
private:typedef list<pair<int, int>>::iterator LtIter; //能够在 O(1) 时间内对节点进行读写操作unordered_map<int, LtIter> _hashMap; // 存储 key 到链表中对应节点的映射,便于快速查找list<pair<int, int>> _LRUList; // 存储缓存项,pair 的 first 为 key, second 为 valuesize_t _capacity;
};
2. 适用场景
- 操作系统: 内存管理中使用 LRU 算法来决定哪些页面需要调出内存。
- 数据库: 缓存热点数据,减少对磁盘的频繁读取,提升查询速度。
- Web 缓存: 在高流量网站中,利用 LRU 缓存常用的页面或数据,降低后端服务器压力。
- 移动设备: 有限的存储资源中,优先保存用户经常使用的数据,提高响应速度。