之前的博客也有对YOLO11的损失函数进行过源码分析,可以参考:YOLOv11小白的进击之路(六)创新YOLO的iou及损失函数时的源码分析_yolov11的损失函数是什么-CSDN博客最近在做小目标检测的时候注意到了NWD损失函数,这里对其源码进行分析,结合YOLO11更改损失函数后在我自己的数据集上有一定的提升,但是效果并不是很明显(可能我的数据集目标尺寸并没有特别小?)这里留待之后讨论。
NWD
NWD是一种用于目标检测的损失函数,通过将边界框建模为高斯分布,并计算两个分布之间的Wasserstein距离来衡量相似性。具体步骤包括:
-
边界框参数化:将边界框 R=(cx,cy,w,h)(中心点坐标和宽高)转换为高斯分布,其中均值为中心点 (cx,cy),协方差矩阵由宽高 (w,h)决定。
-
Wasserstein距离计算:衡量两个分布之间的差异,公式为 W2=∥c1−c2∥2+∥w1−w2∥2+∥h1−h2∥2W2=∥c1−c2∥2+∥w1−w2∥2+∥h1−h2∥2,其中 c为中心点,w,h 为宽高。
-
归一化相似度:通过指数归一化将距离转换为相似度值 NWD=exp(−W/C),其中 C常数。
优势
NWD相较于传统IoU(交并比)的改进主要体现在:
-
对小目标更友好:对小尺度目标的检测更稳定,避免因像素级偏差导致的IoU剧烈波动。
-
处理不重叠框的能力:即使两个边界框完全不重叠,NWD仍能有效度量相似性,而IoU此时为0,无法提供梯度。
-
尺度不变性:对目标尺寸变化不敏感,更适合多尺度检测任务。
应用场景
-
小目标检测:如卫星图像、医学影像中的微小物体检测。
-
密集场景检测:在目标重叠或遮挡严重时,NWD能更平滑地优化模型
源码分析
def wasserstein_loss(pred, target, eps=1e-7, constant=12.8):r"""`Implementation of paper `Enhancing Geometric Factors intoModel Learning and Inference for Object Detection and InstanceSegmentation <https://arxiv.org/abs/2005.03572>`_.Code is modified from https://github.com/Zzh-tju/CIoU.Args:pred (Tensor): Predicted bboxes of format (x_min, y_min, x_max, y_max),shape (n, 4).target (Tensor): Corresponding gt bboxes, shape (n, 4).eps (float): Eps to avoid log(0).Return:Tensor: Loss tensor."""b1_x1, b1_y1, b1_x2, b1_y2 = pred.chunk(4, -1)b2_x1, b2_y1, b2_x2, b2_y2 = target.chunk(4, -1)w1, h1 = b1_x2 - b1_x1, b1_y2 - b1_y1 + epsw2, h2 = b2_x2 - b2_x1, b2_y2 - b2_y1 + epsb1_x_center, b1_y_center = b1_x1 + w1 / 2, b1_y1 + h1 / 2b2_x_center, b2_y_center = b2_x1 + w2 / 2, b2_y1 + h2 / 2center_distance = (b1_x_center - b2_x_center) ** 2 + (b1_y_center - b2_y_center) ** 2 + epswh_distance = ((w1 - w2) ** 2 + (h1 - h2) ** 2) / 4wasserstein_2 = center_distance + wh_distancereturn torch.exp(-torch.sqrt(wasserstein_2) / constant)我们现将参数分解:
b1_x1, b1_y1, b1_x2, b1_y2 = pred.chunk(4, -1)
b2_x1, b2_y1, b2_x2, b2_y2 = target.chunk(4, -1)-
目的:将预测框(
pred)和真实框(target)的坐标拆分成左上角(x1, y1)和右下角(x2, y2)。 -
chunk(4, -1):沿最后一个维度(即列方向)将每个框的4个坐标拆分成4个变量。例如,pred的格式是(x_min, y_min, x_max, y_max),拆分成4个张量后分别对应这四个坐标值。
再计算框的宽高:
w1, h1 = b1_x2 - b1_x1, b1_y2 - b1_y1 + eps
w2, h2 = b2_x2 - b2_x1, b2_y2 - b2_y1 + eps-
目的:计算预测框和真实框的宽度(
w)和高度(h)。 -
+ eps:为了防止宽高为0时出现数值不稳定(例如除零错误),加上一个极小值eps(默认为1e-7)。
计算中心点坐标:
b1_x_center, b1_y_center = b1_x1 + w1 / 2, b1_y1 + h1 / 2
b2_x_center, b2_y_center = b2_x1 + w2 / 2, b2_y1 + h2 / 2-
目的:通过左上角坐标和宽高,计算预测框和真实框的中心点坐标。
计算中心点距离:
center_distance = (b1_x_center - b2_x_center)**2 + (b1_y_center - b2_y_center)**2 + eps-
目的:计算两个框中心点的欧氏距离的平方。
计算宽高距离:
wh_distance = ((w1 - w2)**2 + (h1 - h2)**2) / 4-
目的:计算两个框宽高差异的平方,并除以4(对应高斯分布协方差矩阵的推导)。
合并得到Wasserstein距离:
wasserstein_2 = center_distance + wh_distance-
目的:将中心点距离和宽高距离相加,得到最终的Wasserstein距离平方。
-
数学依据:
将边界框建模为高斯分布后,两个分布的Wasserstein距离平方可以分解为:
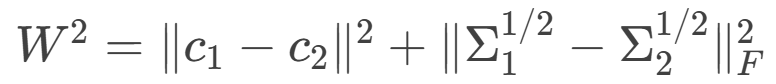
其中协方差矩阵 ΣΣ 由宽高决定( )。
)。
最后归一化损失值:
return torch.exp(-torch.sqrt(wasserstein_2) / constant)-
目的:将Wasserstein距离转换为相似度值(取值范围0~1),作为损失函数。
-
步骤:
-
开平方:
torch.sqrt(wasserstein_2)得到真正的Wasserstein距离 WW。 -
归一化:通过指数函数归一化,公式为 NWD=exp(−W/C),其中 C 是归一化常数
-
损失值:NWD越大,表示两个框越相似,因此损失函数需要最小化 1−NWD。这里我们直接返回相似度值,实际使用时可以用
1 - NWD作为损失。
-
最后
欢迎一起交流探讨 ~ 砥砺奋进,共赴山海!
文章推荐YOLOv11小白的进击之路(二)从YOLO类-DetectionModel类出发看YOLO代码运行逻辑..._if isinstance(m, detect,afpn4head): # includes all-CSDN博客
YOLOv11小白的进击之路(七)训练输出日志解读以及训练OOM报错解决办法_yolo日志-CSDN博客