
近日,计算机视觉和模式识别领域国际顶会CVPR 2025公布了论文录用结果,蚂蚁集团与浙江大学EAGLE实验室合作的论文 “MP-GUI: Modality Perception with MLLMs for GUI Understanding” 被成功录用。

IEEE国际计算机视觉与模式识别会议(CVPR,IEEE Conference on Computer Vision and Pattern Recognition)是由IEEE举办的计算机视觉和模式识别领域的顶级会议,被誉为计算机视觉领域三大顶会之一。CVPR 2025共有13008份有效投稿并进入评审流程,其中2878篇被录用,最终录用率为22.1%。

以下为论文作者团队对该论文的解读:
在现代社会,图形用户界面(GUI)无处不在,无论是日常使用的手机应用,还是专业的计算机软件,都是人与系统交互的重要窗口,已成为不可或缺的一部分。近年来,多模态大型语言模型(MLLM)发展迅猛,在各领域任务中展现出了巨大潜力。然而,GUI与自然图像具有着本质的区别和特殊的挑战。GUI是人工精心设计的产物,其中的图形元素,如按钮、菜单、图标等,不仅内隐了特定的语义信息,还能够通过灵活的页面布局来传达高阶语义信号;另一方面,手机屏幕中存在大量且紧凑布局的UI元素,如文本、控件、图标、功能区等等。
这使得MLLM难以有效解决GUI景中的各种下游任务。主要挑战在于:
(1)MLLM对屏幕中的细粒度信息,如小控件的定位模糊;
(2)MLLM自身缺乏对页面的空间感知能力,无法精准理解GUI元素间复杂的空间关系。
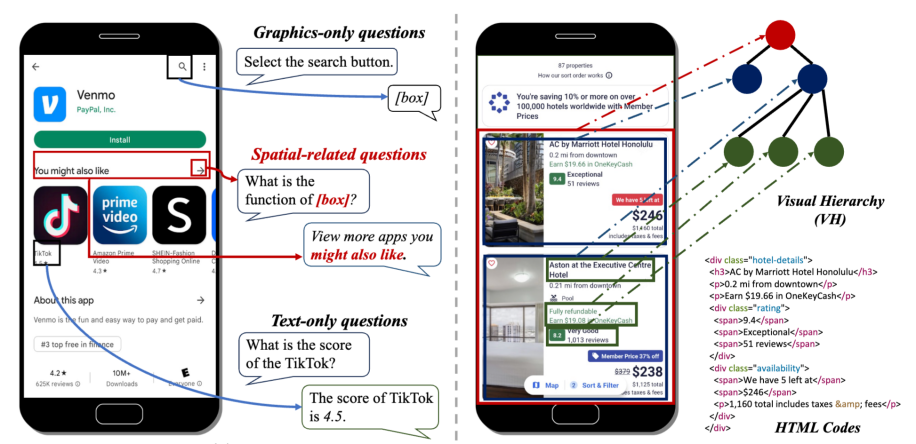
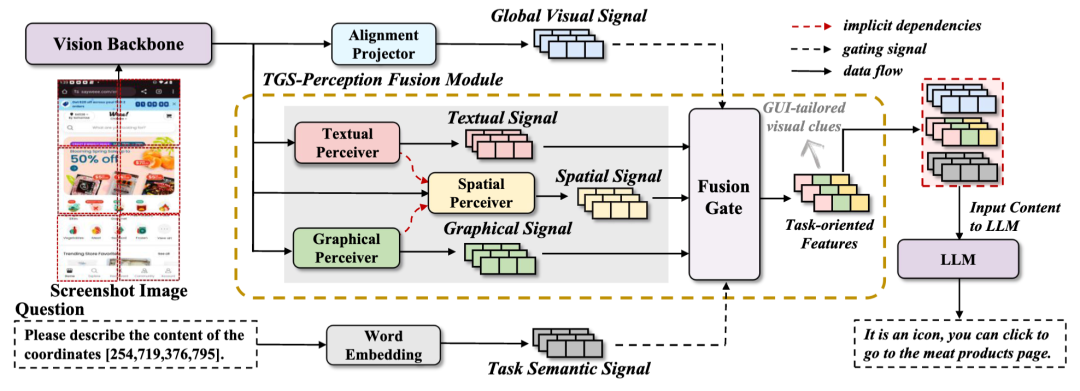
为了应对这些挑战,本研究提出了MP-GUI算法,旨在全方位增强MLLM的GUI理解能力。MP-GUI通过三个不同的GUI感知器来分别提取屏幕中的文本信号、图形信号和元素之间的空间关系信号,并利用一个由语义引导的动态融合门控模块,实现GUI信号的有效融合。在通用视觉线索的基础上为LLM提供额外的GUI定制视觉线索(GUI-tailored visual clues),从而增强MLLM的GUI感知能力,带动各种下游任务的性能提升。
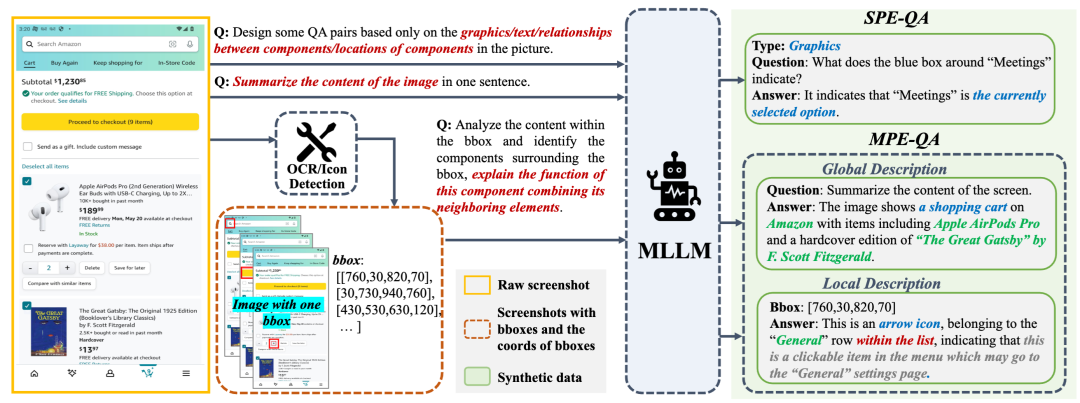
在数据收集方面,我们提出了一种利用MLLM合成训练数据的Pipeline来支撑融合门控模块的有效训练。
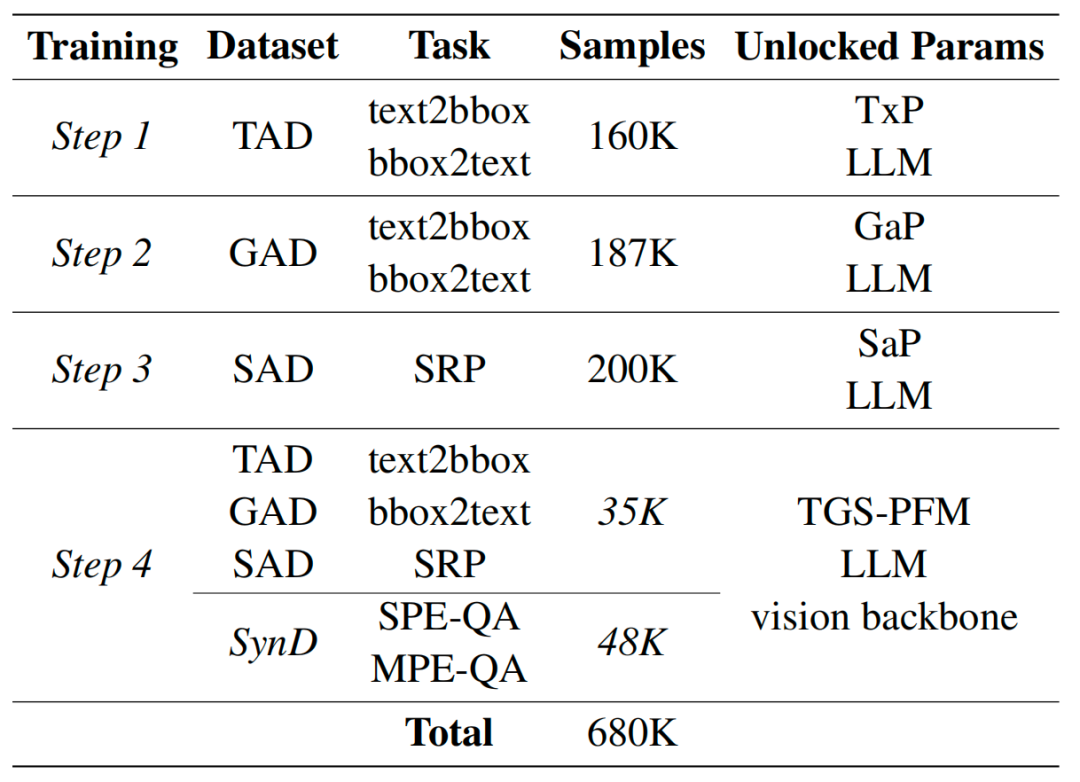
在训练策略方面,不同于当前的端到端隐式训练,我们针对MP-GUI的特殊架构设计了一种多阶段训练策略,并结合不同的训练目标和新颖的空间关系预测任务实现对模型的有效训练,显式地引导MLLM学习GUI知识。实验结果表明我们的的多阶段策略能够有效的帮助模型学习GUI知识。
多阶段训练策略(Multi-stage Training Strategy, MTS):
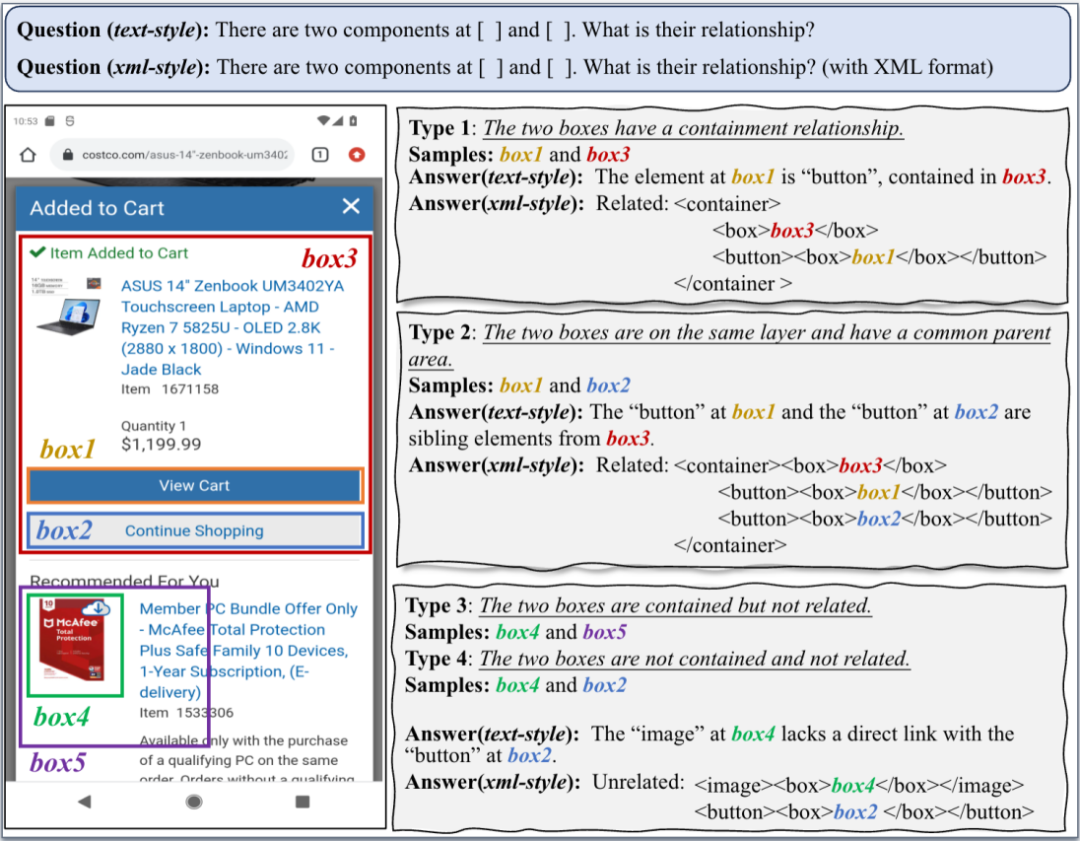
在数据层面,本研究提出了一种空间关系预测任务(SRP),通过显式构建页面UI元素之间的空间上下关系来增强模型的页面的空间上下文感知能力。通过在SRP上进行训练,模型能够学习对页面元素的空间上下文感知与理解。
此外,本研究还提出了一个数据生成pipeline,通过Qwen2VL-72B来合成海量的GUI-related训练数据。
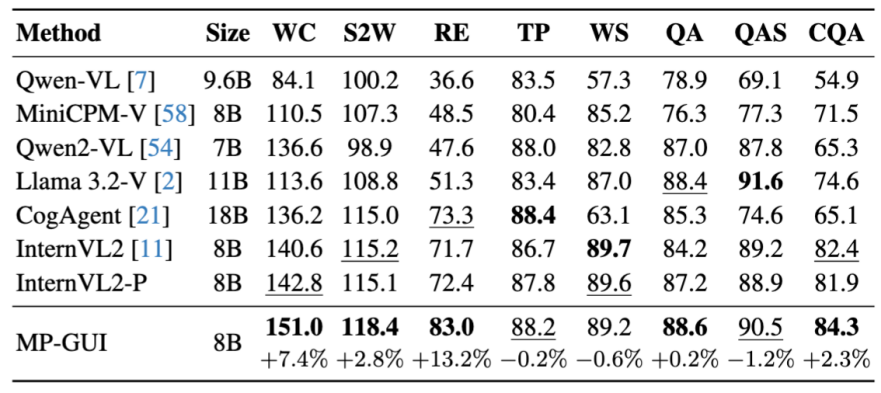
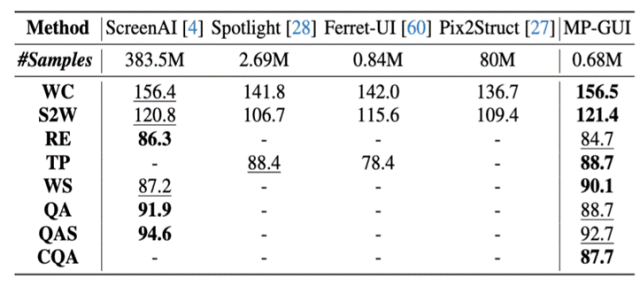
通过广泛的基准测评,我们验证了MP-GUI的先进性,尤其是对屏幕中细粒度视觉元素的定位和理解以及元素间空间上下文的感知,并发现通过对增强MLLM对屏幕中的GUI感知与理解能力,能够进一步提升各种下游任务的性能。
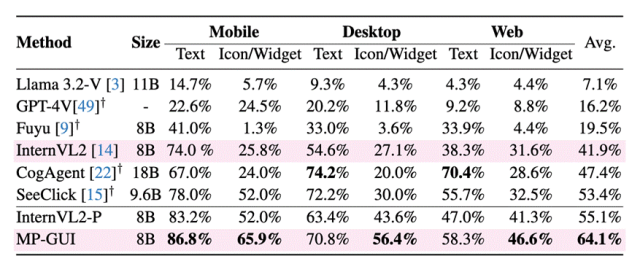
MP-GUI在基础的GUI理解基准上的性能对比,包括控件定位、控件/屏幕摘要、屏幕问答等任务:
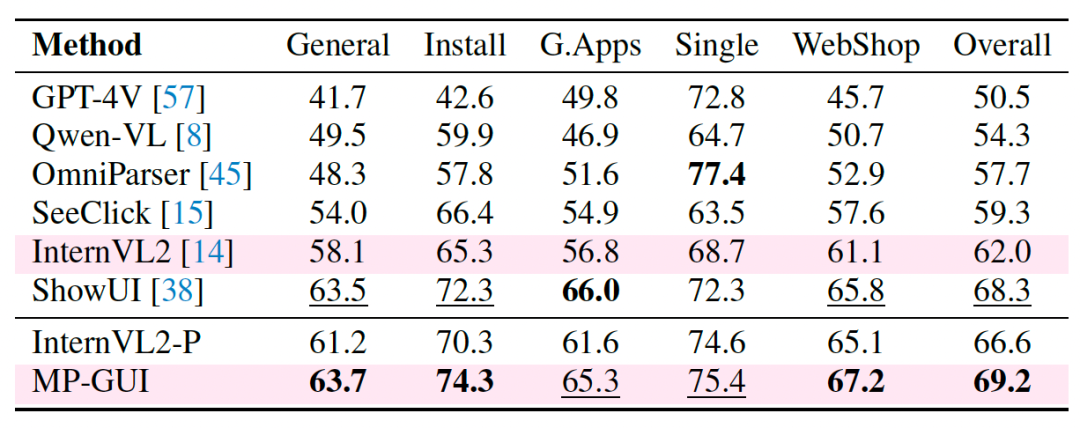
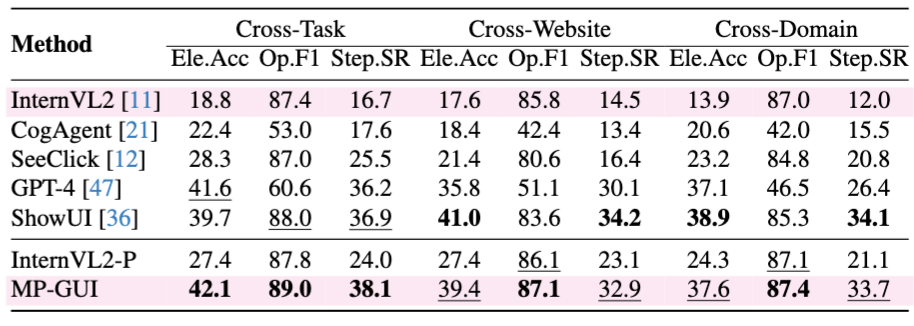
MP-GUI在screen navigation基准上的性能对比(AITW/Mind2Web):
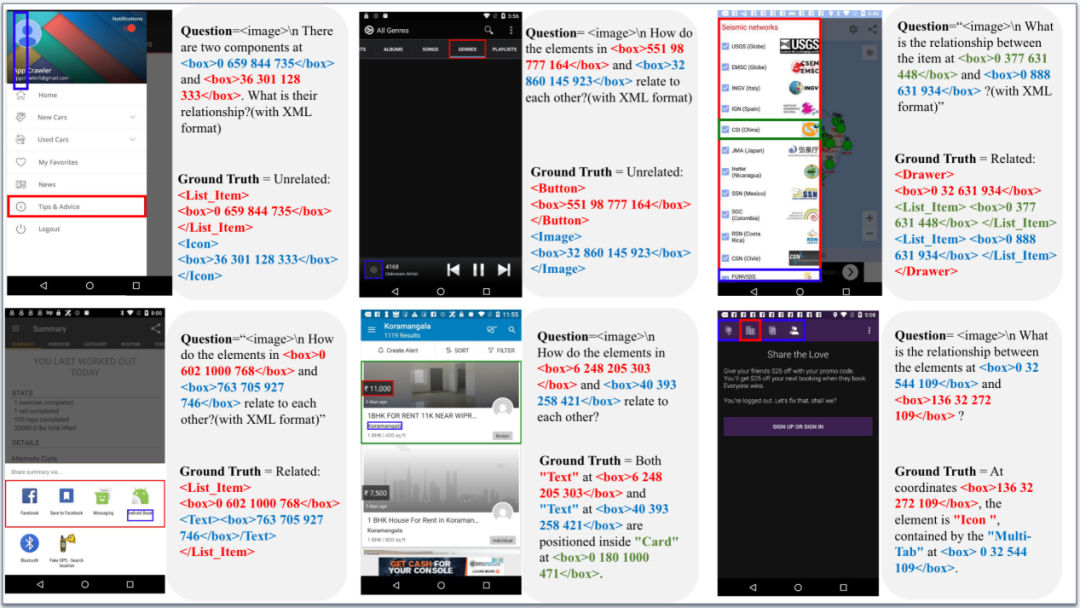
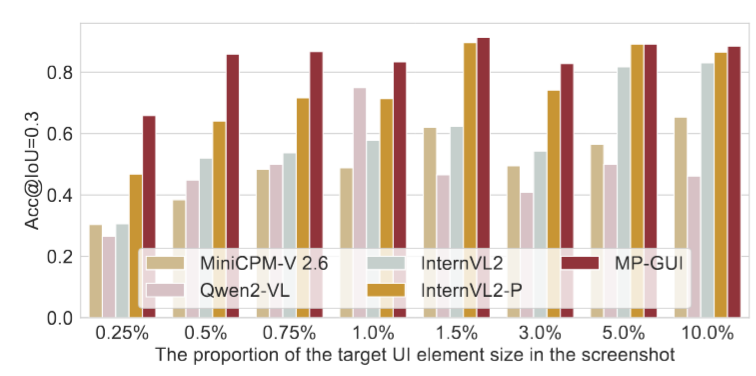
该图展示了MP-GUI在小尺寸控件定位上的出色性能:
部分定性分析示例:
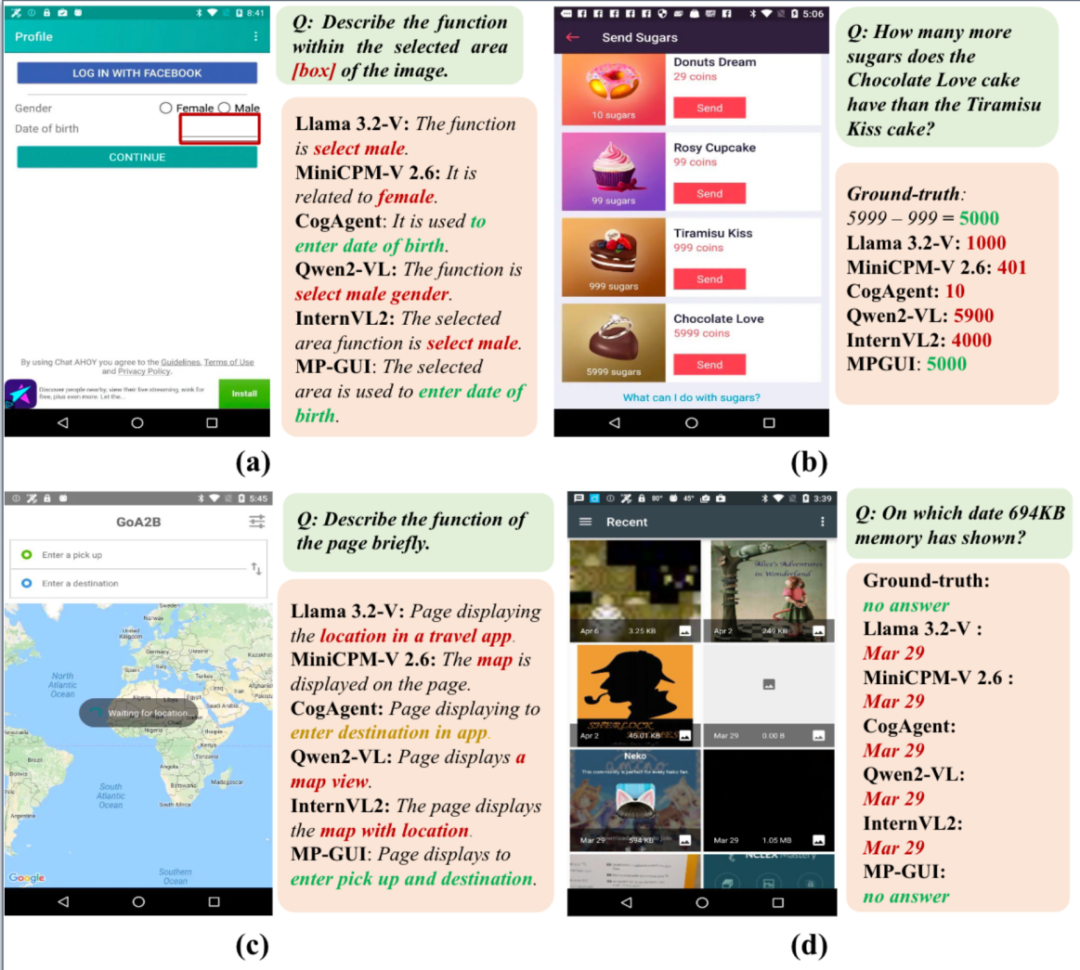
MP-GUI是一个基于MLLM的纯视觉GUI理解模型,在视觉定位方面,能够有效识别页面中的多粒度元素并具有目标元素的空间上下文感知能力;同时,MP-GUI继承了底座MLLM的通用能力。因此,在工业落地方面具有广阔前景——例如,在软件测试领域,能助力自动化测试系统的开发,快速模拟用户对各类手机应用进行全面测试,大幅缩短测试周期,提高测试效率和准确性,降低人工成本;在办公场景中,可搭建GUI Agent,员工通过自然语言下达指令,即可自动操作手机完成任务,提升办公的便捷性与智能化水平,助力企业实现高效移动办公。