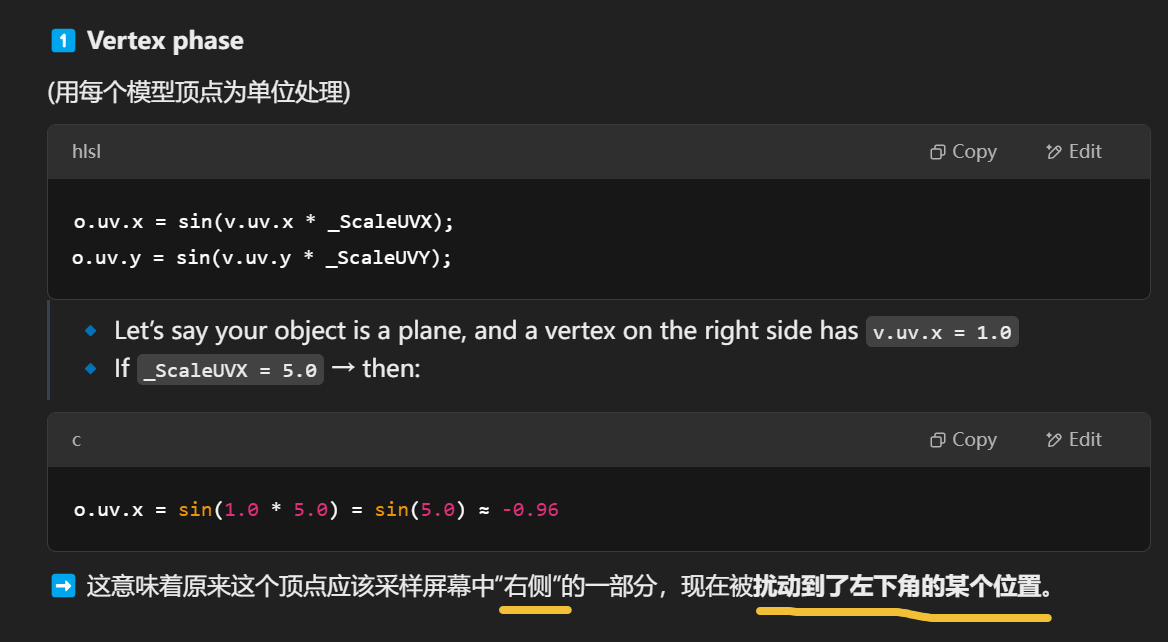
 GPU takes all the vertex
GPU takes all the vertex o.uv values, and for each pixel, it calculates an interpolated UV between nearby vertices.
The whole object looks like it’s warping or rippled,
because every pixel is sampling from a slightly offset place on the screen.
就像水波透过玻璃看到的背景一样:你动的不是模型,也不是贴图,而是“采样的位置”。
the texture won't tile or repeat automatically — even if the UV values change, because _GrabTexture uses clamped UV coordinates, not repeating ones.
-
_GrabTexture is not a regular texture.
It’s a special render texture created by Unity to hold the screen image.
This texture is by default set to Clamp mode, not Repeat. -
UVs outside [0,1] are clamped to edge pixels.
-
If your sine-distorted UV becomes
-0.5or1.2,
it won’t wrap — it will just get stuck at 0 or 1. -
So you’ll get edge stretching, not tiling.
-
Shader "Holistic/VFDiffuse"
{Properties{_MainTex ("Texture", 2D) = "white" {}}SubShader{Pass{Tags {"LightMode"="ForwardBase"}CGPROGRAM#pragma vertex vert#pragma fragment frag#include "UnityCG.cginc" #include "UnityLightingCommon.cginc" struct appdata {float4 vertex : POSITION;float3 normal : NORMAL;float4 texcoord : TEXCOORD0;};struct v2f{float2 uv : TEXCOORD0;fixed4 diff : COLOR0; float4 vertex : SV_POSITION;};v2f vert (appdata v){v2f o;o.vertex = UnityObjectToClipPos(v.vertex);o.uv = v.texcoord;half3 worldNormal = UnityObjectToWorldNormal(v.normal);half nl = max(0, dot(worldNormal, _WorldSpaceLightPos0.xyz));o.diff = nl * _LightColor0;return o;}sampler2D _MainTex;fixed4 frag (v2f i) : SV_Target{fixed4 col = tex2D(_MainTex, i.uv);col *= i.diff;return col;}ENDCG}}
}This Shader does real-time lighting calculation using a Lambert diffuse model,
while your previous shader (VFMat) simply samples and distorts the screen — no lighting involved.

在顶点阶段设置了光照颜色
_LightColor0,但片元阶段好像没有直接使用,那它有没有被真正用上?
答案是:有被使用,而且作用很关键。
只不过不是直接在 frag() 里面用,而是在 vert() 顶点阶段就用掉了,结果通过插值传给了 frag()。
SV_POSITION 是一个语义标记(semantic),它只是告诉 GPU:这个变量用于屏幕空间定位像素的位置。
但它不会自动赋值,也不会自动把顶点变换到裁剪空间。你仍然必须自己计算并赋值。
: POSITION 表示的是输入的“顶点位置”,但这个位置是“模型空间”(Object Space)下的坐标。
这个 vertex 的值,是从你模型的 mesh 数据中直接传入的 原始顶点坐标,尚未经过世界变换或投影矩阵变换。
语义本身不是双向“数据传输通道”,它只是告诉 GPU:这个变量的用途是什么。
“是否是输入输出”,取决于它出现在哪个结构体中,不是语义本身双向的。
语义 ≠ 自动计算器
它只是告诉系统:“这个变量我要用来干这个事”
你想要什么值,必须自己赋进去!
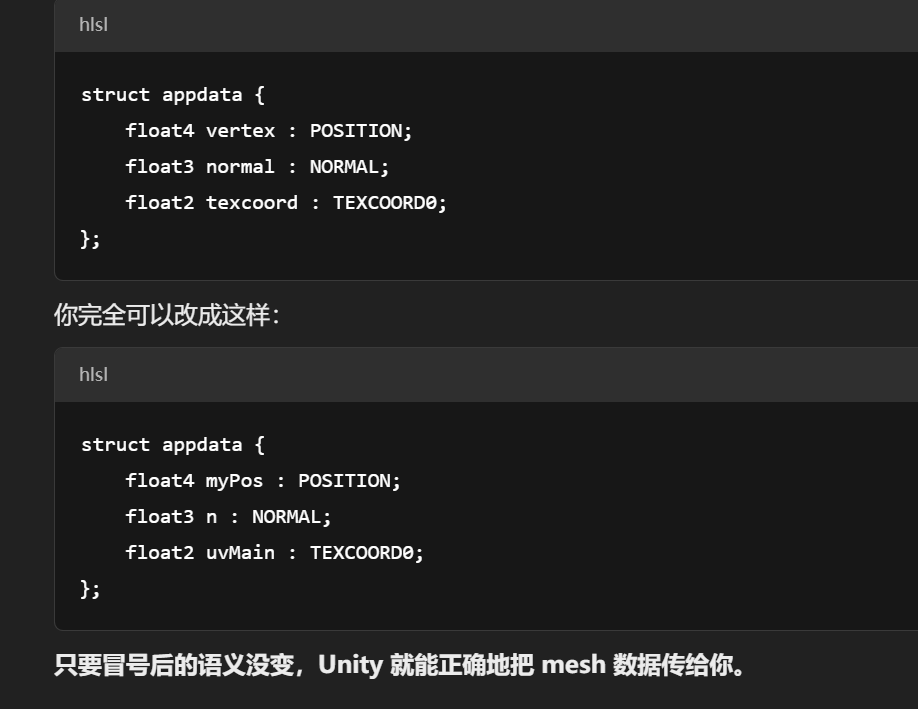
struct appdata {
float4 vertex : POSITION; // 这是输入,值是模型空间位置
};
struct v2f {
float4 vertex : SV_POSITION; // 这是输出,值是裁剪空间位置
};
v2f vert(appdata v) {
v2f o;
o.vertex = UnityObjectToClipPos(v.vertex); // 必须你来赋值
return o;
}
"LightMode" = "ForwardBase" 表示:
“我这个 Pass 会被 Unity 在主光照阶段使用,请把主光源的光照、环境光都交给我处理。”
Unity 会识别这个标签,并在 Forward 渲染流程中调用你这个 Pass,并注入这些变量:
-
_LightColor0→ 主光源颜色 -
_WorldSpaceLightPos0→ 主光源方向(方向光)或位置(点光源) -
_SHAr,_SHAg,_SHAb→ 球谐环境光(SH) -
unity_AmbientSky等 → 环境光分量
在 Unity 的 Forward Rendering(前向渲染)模式中,Unity 会这样处理光照:
| Pass 类型 | 作用 |
|---|---|
ForwardBase | 渲染主光源(主 Directional Light),并计算环境光、全局光照贴图(Lightmap)、SH 等 |
ForwardAdd | 渲染额外的点光源 / 聚光灯(Additive Blend),每个灯光一个 Pass |
ShadowCaster | 渲染阴影深度图(阴影投射者) |
Meta | 用于光照贴图烘焙、GI 等 |
Unity 模型中的每个顶点,都会包含若干附加信息:
| 数据类型 | 通常语义 |
|---|---|
| 顶点坐标 | POSITION |
| 法线 | NORMAL |
| 主 UV | TEXCOORD0 ✅ |
| 第二套 UV | TEXCOORD1 |
| 顶点颜色 | COLOR |
| 切线 | TANGENT |
float2 uv : TEXCOORD0;
意思就是:我要从模型里取出每个顶点的主纹理坐标(UV),并把它赋给这个变量。
vertex:vert 的意思是:
“在 Surface Shader 编译过程中,请调用我自定义的 vert() 函数来处理每个顶点的数据。”
也就是说:你可以自己写一个顶点函数 vert(),然后把它挂载到 Unity 的 Surface Shader 顶点阶段,这样你就可以:
-
修改顶点位置
-
修改自定义变量(比如 UV、法线、颜色等)
-
给
Input结构体赋值额外数据
inout 的意思是:这个变量既是输入也是输出。
你不仅可以读取它的值,还可以修改它的值并传回给后续管线使用。
inout 就是告诉 Unity Shader 编译器:
“我这个函数要修改传入的
appdata v,让顶点坐标/法线/UV 发生变化,并把它传回去继续用。”
v.vertex.xyz += v.normal * _Amount;
把顶点的位置,沿着该顶点的法线方向,移动 _Amount 的距离。
v.vertex.xyz 是什么?
-
这是当前顶点的位置
-
坐标是模型空间(Object Space)下的三维向量
v.normal是什么? -
当前顶点的法线向量
-
也是在模型空间下的方向,表示表面“朝外”的方向
_Amount 是 float 值,代表你想推出/拉进的距离
v.vertex.xyz += v.normal * _Amount 做了什么?
用法线方向 × 移动距离 = 偏移向量
然后加到原始顶点坐标上 → 得到新的顶点位置
逻辑发生在:顶点阶段,也就是每一个顶点刚被送进 GPU 时执行。
-
所有顶点都“鼓出来一点”
-
原本平滑的表面就变得更大/更鼓
你设置 _Amount = 0.01 → 膨胀 1cm
设置 _Amount = -0.02 → 收缩 2cm
surf() 是 Unity Surface Shader 中的材质响应函数,用于定义物体表面在光照下的表现:颜色、光泽、发光、自发光、透明度等。
参数 IN 是输入数据(比如 UV、世界坐标等),o 是输出结果(如漫反射颜色、法线、发光颜色等)。
| 部分 | 作用 |
|---|---|
Input IN | 输入参数结构体(你自定义的) |
inout | 意思是这个参数可读可写(你要赋值) |
SurfaceOutput o | Unity 内置的输出结构体,用于设置表面材质的属性 |
Input IN
这是你自己在 Shader 中定义的结构体,里面放着你需要的输入数据,比如:
struct Input {
float2 uv_MainTex;
float3 worldPos;
float3 viewDir; };
这些变量可以:
-
由 Unity 自动插值填充(比如 UV)
-
由你在
vertex:xxx函数中手动赋值(如 worldPos)
inout SurfaceOutput o
这是 Unity 内置的结构体,你在 surf() 里要对它赋值,它控制最终材质表现
o 有很多可赋值字段,主要包括:
| 字段 | 用途 |
|---|---|
Albedo | 漫反射颜色(贴图颜色) |
Normal | 法线(用于法线贴图) |
Emission | 自发光(发光颜色) |
Alpha | 透明度(配合透明队列使用) |
Specular | 高光反射(在 BlinnPhong 中用) |
o.Albedo = tex2D(_MainTex, IN.uv_MainTex).rgb;
用 _MainTex 这张贴图,根据当前像素的 UV 坐标 IN.uv_MainTex 采样出颜色,然后赋值给材质的漫反射颜色(o.Albedo)。
IN.uv_MainTex 是什么?
是 Unity 自动插值出来的 UV 坐标,表示当前像素在贴图上的位置。
比如一个值为(0.2, 0.4)表示贴图上从左向右 20%,从下向上 40% 的位置。
tex2D(_MainTex, IN.uv_MainTex)
表示:用这个 UV 坐标,从
_MainTex中采样一个颜色。
-
如果
_MainTex是一张人物贴图,那这个像素就会显示该贴图上对应位置的颜色。
IN.uv_MainTex 的值最终来自于模型的顶点 UV 坐标,也就是模型文件(如 FBX、OBJ)中每个顶点自带的贴图坐标信息。
这些 UV 值:
-
会在模型导入时作为 mesh attribute 保存下来
-
在 Shader 中通过语义
TEXCOORD0自动绑定进来
struct appdata {
float4 vertex : POSITION;
float2 uv : TEXCOORD0;
};
Surface Shader 中,Unity 会自动帮你把 UV 插值后传入 Input 结构体
struct Input {
float2 uv_MainTex;
}
知道你的贴图变量叫 _MainTex,就会自动提供 uv_MainTex,绑定的是主 UV(TEXCOORD0)通道。
值是在 GPU 渲染的“光栅化阶段”由顶点插值生成的:
-
每个顶点有自己的 UV(例如左下角 (0,0),右上角 (1,1))
-
顶点着色器输出这些 UV 值
-
光栅器(Rasterizer)会对三角形内部所有像素做插值,得到每个像素的 UV
-
最终在
surf(Input IN, ...)中,IN.uv_MainTex就是该像素插值得到的 UV 坐标
UV 的标准范围是 [0.0, 1.0],表示整张贴图从左下角到右上角。
但是也可以:
-
超过 1.0 或小于 0(比如
uv = 1.5,uv = -0.3) -
是否“重复”贴图、或“拉伸边缘”,取决于纹理的 Wrap Mode 设置:
-
Repeat:超出范围会重复 -
Clamp:超出后贴图边缘像素拉伸 -
Mirror:镜像反射重复
-
这些设置是在 Texture 导入器或代码中设置的:
myTexture.wrapMode = TextureWrapMode.Repeat;
struct appdata不是固定的,可以自定义。
appdata 只是 Unity 教程中惯用的命名,你完全可以叫它别的
关键是里面的语义标签(: POSITION, : NORMAL 等)对了,Unity 就能识别对应的顶点属性。
名字不重要,语义才是关键。
每一个顶点在模型中,都有一套对应的“顶点属性”数据,包括:
-
位置(vertex)
-
法线(normal)
-
UV 坐标(uv)
-
顶点颜色(color)
-
切线(tangent)
属性是从 3D 模型导入时就存在的,GPU 渲染时:
-
顶点着色器(
vert())会逐顶点执行一次 -
每个
appdata结构体实例就是一个顶点的数据打包
vert() —— 只对“顶点”执行,而且只对每一个顶点执行一次。
所谓“不是顶点”的部分,比如:
-
三角形的中间像素(就是像素着色器
frag()处理的) -
线条、片段、模型整体、屏幕坐标等
这些都不会执行 vert(),它们处理的是“已经过顶点阶段插值之后的结果”。
ZWrite Off 表示:本物体的像素不会写入深度缓冲(Z-Buffer)中
不写入 ZBuffer 会导致什么?
-
❗ 这个物体之后画的像素会“无视”它的存在
-
如果其他物体是 ZTest On 的,它可能穿透你这个物体
ZWrite On | ✅ 写入深度缓冲,默认行为,遮挡后面物体 |
ZWrite Off | ❌ 不写入深度缓冲,用于透明、特效、描边等 |
CGPROGRAM 可以写多个,每个对应一个 不同的渲染 Pass(阶段)或用途,中间的 ZWrite 切换其实是在控制两个渲染 Pass 的不同行为。
ZWrite Off
CGPROGRAM
#pragma surface surf Lambert vertex:vert
// 顶点外扩 + 只发光,不受光
v.vertex.xyz += v.normal * _Outline;
o.Emission = _OutlineColor.rgb;
ENDCG
ZWrite Off:✅ 不写入 Z 缓冲,避免挡住正常模型
vertex:vert:✅ 每个顶点沿法线外扩(实现描边)
o.Emission:✅ 发光颜色,不受光照影响
这是描边 Pass
ZWrite On
CGPROGRAM
#pragma surface surf Lambert
// 普通纹理渲染
o.Albedo = tex2D(_MainTex, IN.uv_MainTex).rgb;
ENDCG
ZWrite On:✅ 写入深度,遮挡后面的像素
不写顶点函数:直接正常绘制
Albedo:使用贴图颜色
这是主模型 Pass
Surface Shader 的语法中,每个 #pragma surface 块隐式等价于一个 Pass。
-
轮廓永远不会挡住模型本体
-
也不会让后续物体错误地被遮住
-
视觉上形成清晰描边 ✅
Unity 的 Surface Shader 并不像手写 Shader 那样显式使用 Pass {},它是通过每个 #pragma surface 编译生成一个渲染 Pass。
ZWrite 是一个光栅化阶段(Rasterization)设置项,它控制的是当前 Pass 输出的像素是否写入 Z 缓冲区。
并不是作用在顶点函数或 fragment 函数内部,而是:
作用在 GPU 固定管线阶段:
Pixel 被光栅化后 → 先执行深度测试 → 如果通过 → 判断是否写入 Z 值 → 然后执行片元着色
Cull Front 表示:剔除(不渲染)面向摄像机的“正面”三角形,只渲染背面(反面)。
描边和模型主体用了同一个 Shader,但 Queue 相同,ZWrite 又不同
-
✅
ZWrite Off:不写入深度,不能遮挡后面 -
✅
Queue="Transparent"→ 实际是 Render Queue 2000
Unity 在 同一个 Render Queue 值下,无法保证两个 Pass 的顺序一定正确!
➤ 它可能先渲染本体,然后再渲染描边(这会被本体 Z 覆盖掉)
-
Scene 视图不会严格执行渲染排序
-
Game 视图会按照渲染队列 + 摄像机裁剪 + batching 排序,非常严格
方法二:拆分 Shader 为两个材质
更专业的写法是将“描边”和“本体”写成两个独立材质 + Shader,挂在两个渲染对象上(同一 Mesh):
| 组件 | Shader 特征 | Queue |
|---|---|---|
| 描边对象 | ZWrite Off + Cull Front | 2500~3000 ✅ |
| 本体对象 | ZWrite On + 默认 | 2000 |
Bonus:你可以在 Shader 中手动设置不同 Pass 的渲染队列吗?
⚠️ 不行,Unity 的 Tags { "Queue"=... } 是作用在整个 SubShader 上的,无法对每个 Pass 单独设置 Queue 值。
所以如果你要手动控制描边先画、本体后画,就要用不同的材质或修改材质的 queue 值。
✅ 如果一个物体 ZWrite 关闭但 Queue 仍然低(比如 2000),它在 Game 视图中可能被其它物体盖住;
✅ 而 Scene 视图不会有这个问题,是因为 Scene 视图不执行真正的深度测试渲染流程。
Shader "Holistic/AdvOutline" {Properties {_MainTex ("Texture", 2D) = "white" {}_OutlineColor ("Outline Color", Color) = (0,0,0,1)_Outline ("Outline Width", Range (.002, 0.1)) = .005}SubShader {CGPROGRAM#pragma surface surf Lambertstruct Input {float2 uv_MainTex;};sampler2D _MainTex;void surf (Input IN, inout SurfaceOutput o) {o.Albedo = tex2D (_MainTex, IN.uv_MainTex).rgb;}ENDCGPass {Cull FrontCGPROGRAM#pragma vertex vert#pragma fragment frag#include "UnityCG.cginc"struct appdata {float4 vertex : POSITION;float3 normal : NORMAL;};struct v2f {float4 pos : SV_POSITION;fixed4 color : COLOR;};float _Outline;float4 _OutlineColor;v2f vert(appdata v) {v2f o;o.pos = UnityObjectToClipPos(v.vertex);float3 norm = normalize(mul ((float3x3)UNITY_MATRIX_IT_MV, v.normal));float2 offset = TransformViewToProjection(norm.xy);o.pos.xy += offset * o.pos.z * _Outline;o.color = _OutlineColor;return o;}fixed4 frag(v2f i) : SV_Target{return i.color;}ENDCG}} Fallback "Diffuse"
}UnityObjectToClipPos(v.vertex) 作用是:
把模型空间(Object Space)的顶点坐标 v.vertex 转换为 裁剪空间(Clip Space) 坐标 o.pos,供后续光栅化和屏幕渲染使用。
它的转换过程实际上包含了 3 个阶段:
Object Space → World Space → View Space → Clip Space
而 UnityObjectToClipPos() 是 Unity 提供的内置宏,它封装了:
UNITY_MATRIX_MVP * v.vertex
即:
ClipPos = ProjectionMatrix * ViewMatrix * ModelMatrix * vertex
你可以理解为:
把模型坐标转换到「摄像机视角下能被投影裁剪」的屏幕三维空间中。
(float3x3) 强制转换
-
UNITY_MATRIX_IT_MV是 4x4 矩阵 -
法线是方向向量,不参与平移,因此我们只用 3x3 的旋转缩放部分
-
所以这里把它强制转成
float3x3只保留旋转缩放影响
mul(...)
-
将矩阵与
v.normal相乘 -
把模型空间中的法线方向,变换到摄像机空间(View Space)
normalize(...)
-
最后归一化成单位向量
-
这是非常重要的步骤,保持描边时方向的统一性和稳定性
-
如果不 normalize,后面描边的偏移可能不均匀或变形
在 HLSL 中,矩阵是行主序(row-major),而 vector * matrix 和 matrix * vector 在数学意义上顺序不同。
所以 HLSL 里建议 统一使用 mul() 函数来明确“矩阵乘向量”或“向量乘矩阵”的顺序,避免歧义。
-
✅ 语法允许
matrix * vector -
❌ 但乘法规则依赖矩阵定义方式(row-major vs column-major)
-
❗ 在跨平台(比如 DX 和 Metal / Vulkan)会出现不一致行为
-
💣 你可能在 Windows 正常,在 Mac 或 WebGL 上显示错位
所以 Unity 推荐:
| 用法 | 是否推荐 | 原因 |
|---|---|---|
matrix * vector | ❌ 不推荐 | 行列顺序在不同平台容易出错 |
mul(matrix, vector) | ✅ 强烈推荐 | 显式明确乘法方向,跨平台稳定 |
为什么法线要用 逆转置矩阵(inverse transpose) 来变换?
为什么不能像顶点一样,直接用 M * v 变换?
顶点 vs 法线,它们本质不一样!
| 顶点(position) | 法线(normal) |
|---|
| 表示“点”的位置 | 表示“面”的方向 |
| 会被平移、旋转、缩放影响 | 只应被旋转、缩放影响,不能被平移影响 |
可以直接乘 ModelMatrix | ❌ 不能直接乘 ModelMatrix |
法线向量不能直接用模型变换矩阵(M)去变换,而应该用它的「逆转置矩阵」来变换
| 项目 | 顶点 | 法线 |
|---|---|---|
| 表示意义 | 空间中的一个“点” | 一个“方向”向量(垂直表面) |
| 使用矩阵 | ModelMatrix * pos | (ModelMatrix⁻¹)ᵀ * normal |
| Unity 写法 | UnityObjectToClipPos() | mul(UNITY_MATRIX_IT_MV, n) |
| 是否受平移影响 | ✅ 会 | ❌ 不应受平移 |
把一个立方体在 Y 方向压扁:
-
顶点会变 → 正常
-
但如果法线也按相同方式变 → 法线就不再垂直于表面了 ❌
这就会导致光照错乱,反光方向不对、表面变亮或发黑。
你用模型变换矩阵 M 把它从局部坐标(模型空间)变成世界坐标:
“那经过变换之后的 法线,还会满足 n ⋅ surface_vector == 0 吗?”
换句话说:是否仍然垂直于新的表面?
是的,只要你对法线使用了正确的逆转置变换,它就会继续满足这个垂直关系:
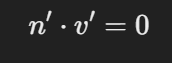

| Full line | Meaning |
|---|---|
float3 norm = normalize(mul((float3x3)UNITY_MATRIX_IT_MV, v.normal)); | Take the object-space normal, transform it correctly into view space using the inverse transpose of the model-view matrix, and normalize it so it's ready for use (e.g., screen-space extrusion, lighting, etc.) |
UNITY_MATRIX_IT_MV transforms normals into View Space, not Clip Space.
Here's what the matrix name tells us:
| Matrix Name | Meaning |
|---|---|
M | Model matrix (Object → World) |
V | View matrix (World → Camera) |
MV = V * M | Model-View matrix (Object → View) |
UNITY_MATRIX_IT_MV | Inverse Transpose of Model-View matrix |
那为什么不是 Clip Space?
-
Clip Space 是做完了
Projection(投影矩阵)后的结果 -
而 Normals 是方向向量,不参与投影!
-
投影矩阵会压缩 Z 分量、进行视锥体剪裁,这对方向是完全错误的
TransformViewToProjection() 是 Unity 内置的一个宏函数,它将观察空间中的方向向量(View Space),转换为裁剪空间/投影空间中的偏移方向,
你有一个方向,比如向右偏一点上,你想用这个方向来“推”顶点向外偏一丢丢。
但这时候你顶点的坐标在 Clip Space,而你的方向在 View Space → 它们不在一个空间里,直接相加是错的。
观察空间方向 → Clip Space 方向 → 可以安全加到 o.pos.xy 上
TransformViewToProjection(norm.xy);
TransformViewToProjection 做了什么?
UNITY_MATRIX_P:投影矩阵(把 View Space 转成 Clip Space)
它会把一个二维方向 (x, y) 变成:
Clip Space 的 xy 偏移量
所以你可以安全地对 o.pos.xy 做偏移,制造「轮廓膨胀」效果。
| 步骤 | 数据 | 空间 | 说明 |
|---|---|---|---|
| 法线 | v.normal | Object Space | 原始 |
| 转换 | mul(UNITY_MATRIX_IT_MV, ...) | View Space | 法线方向转观察空间 |
| 变换 | TransformViewToProjection(norm.xy) | Clip Space | 得到可以直接加到 o.pos.xy 的偏移方向 |
| 膨胀 | o.pos.xy += ... | Clip Space | 实际屏幕上的轮廓扩张 |
“在 View Space(观察空间)中,是否只有 x 和 y?为什么我们在代码里只用 norm.xy?”
❌ View Space 是三维的!有 x, y, z
✅ 但在「描边膨胀」这个场景中,我们只取用了 norm.xy,因为只在屏幕平面(x/y 方向)上偏移!
View Space 是什么?
View Space 是相机所看到的空间:
-
X:水平轴(相机左 → 右)
-
Y:垂直轴(相机下 → 上)
-
Z:前后轴(相机前 → 深处)
所以 View Space 是完整的三维空间 (x, y, z) ✅
那我们为什么只拿 norm.xy?
因为你在做的是:
✅ 把物体“在屏幕上往外推一点点”
这个膨胀是在屏幕的平面上进行的:
-
你希望轮廓沿着屏幕中的方向膨胀
-
而屏幕就是:x 和 y
屏幕没有 z 深度位移的意义,你不能把描边推到屏幕后面或前面。
所以这一行:
float2 offset = TransformViewToProjection(norm.xy);
本质是:
📌 从观察空间中拿出法线的横向和纵向分量(也就是
norm.x和norm.y)
🔄 然后把它转换成投影空间里的屏幕偏移方向,用于:
o.pos.xy += offset * o.pos.z * _Outline;
如果我们也用了 norm.z 会怎样?
其实不是错,只是:
-
z 分量代表的是“深度方向”
-
但裁剪空间中你只能控制
xy偏移 -
你用
norm.z也没地方加它,Unity 不允许你去随意调o.pos.z(会出事)
所以:
我们只处理法线方向的横向(x)和纵向(y)偏移,让轮廓在线上扩张。
“The z in View Space isn’t the main part, because Unity will do Z-buffer processing — so I can’t really modify it.”
✅ Answer: Exactly. That's why we don’t modify z during the outline offset.
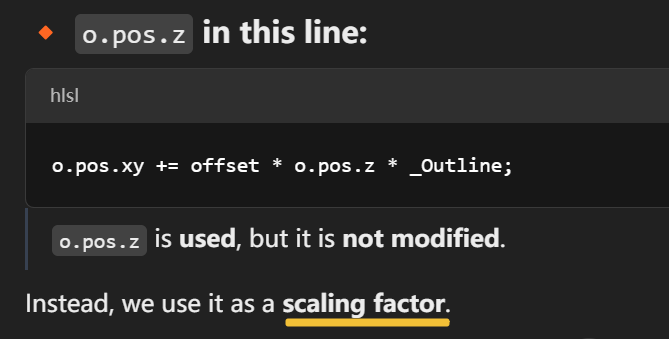
🤔 Why is o.pos.z involved at all then?
Because:
As geometry moves farther from the camera, its screen-space size becomes smaller (perspective).
So if we want the outline to look consistent regardless of distance, we do