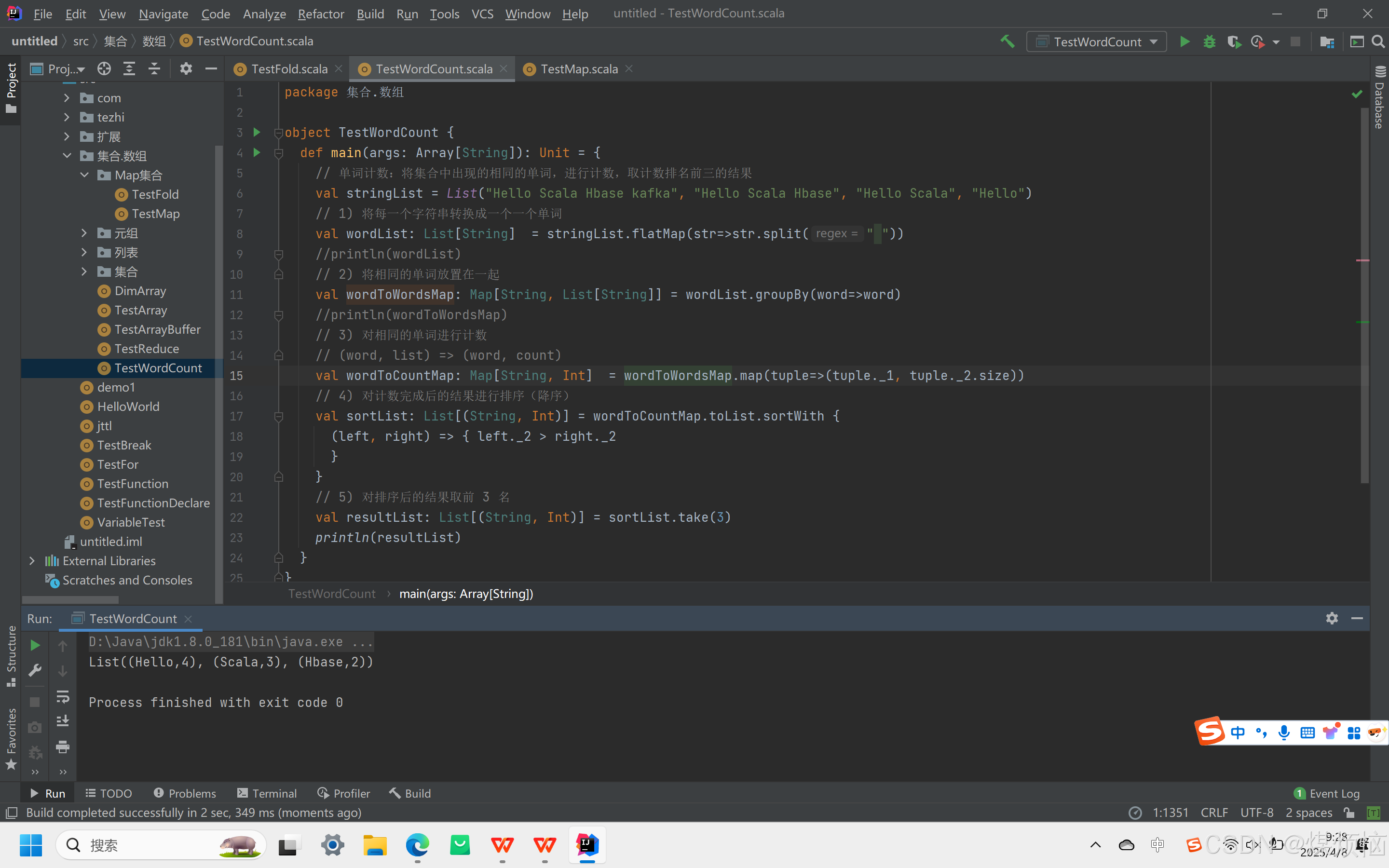
一、说明
1.过滤:遍历集合,获取满足指定条件的元素组成新集合
2.转化 / 映射(map):将集合中的每个元素映射到某一个函数
List(1, 2, 3, 4, 5, 6, 7, 8, 9)中每个元素加 1,得到List(2, 3, 4, 5, 6, 7, 8, 9, 10)。
3.扁平化:将嵌套集合展开成单一集合。nestedList.flatten把List(List(1, 2, 3), List(4, 5, 6), List(7, 8, 9))转化为List(1, 2, 3, 4, 5, 6, 7, 8, 9)
4.扁平化 + 映射(flatMap):先进行 map 操作,再进行 flatten 操作wordList.flatMap(x => x.split(" "))把List("hello world", "hello zpark", "hello scala")中的每个字符串按空格拆分后合并成List("hello", "world", "hello", "zpark", "hello", "scala")。
5.分组(group):按照指定规则对集合元素分组
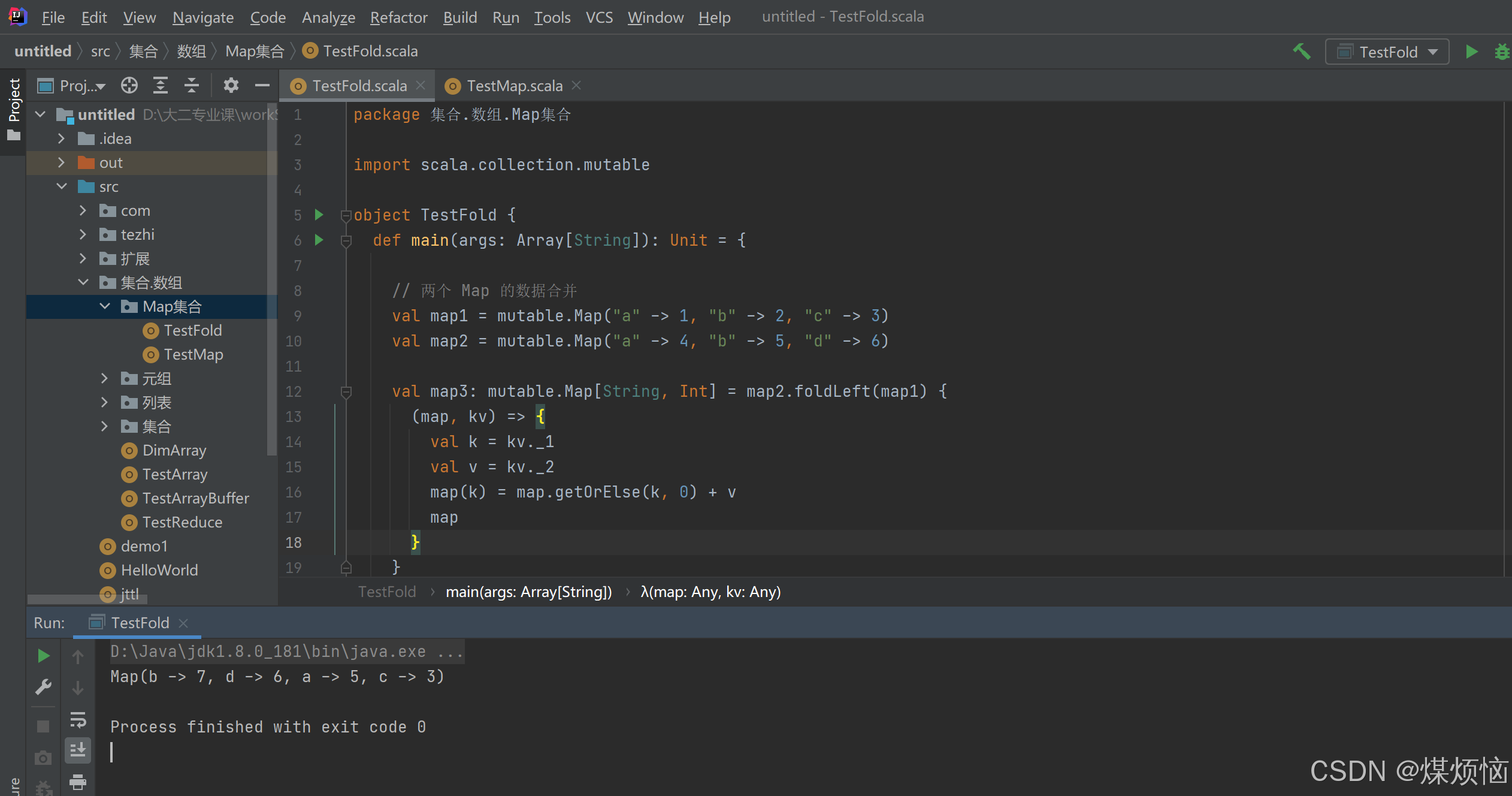
6.简化(归约):通过指定逻辑聚合集合数据。reduceLeft与reduce底层实现相似,reduceRight计算顺序相反
7.折叠(fold):化简的特殊情况
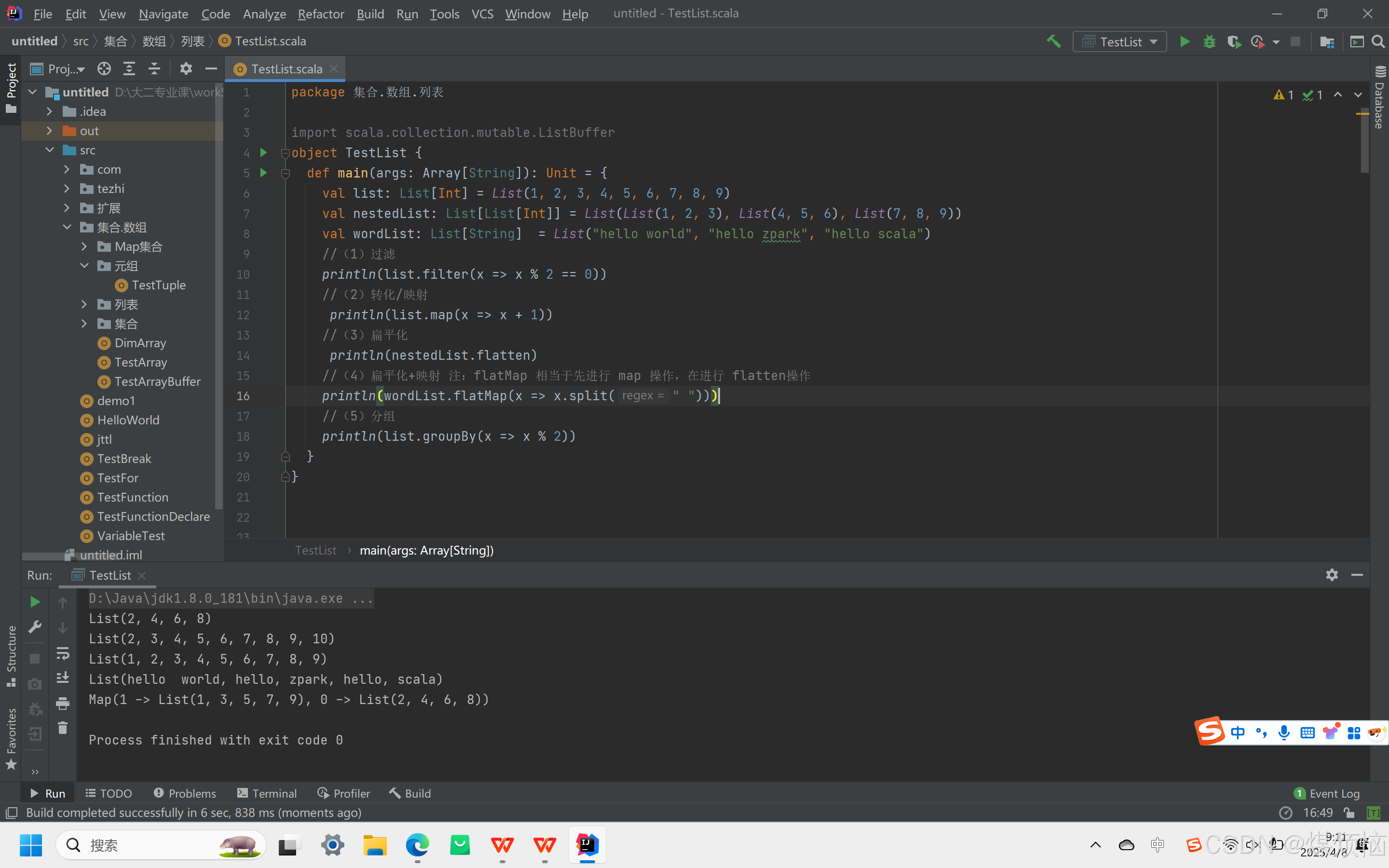
- reduce方法
Reduce 简化(归约) :通过指定的逻辑将集合中的数据进行聚合,从而减少数据,最终获取结果。
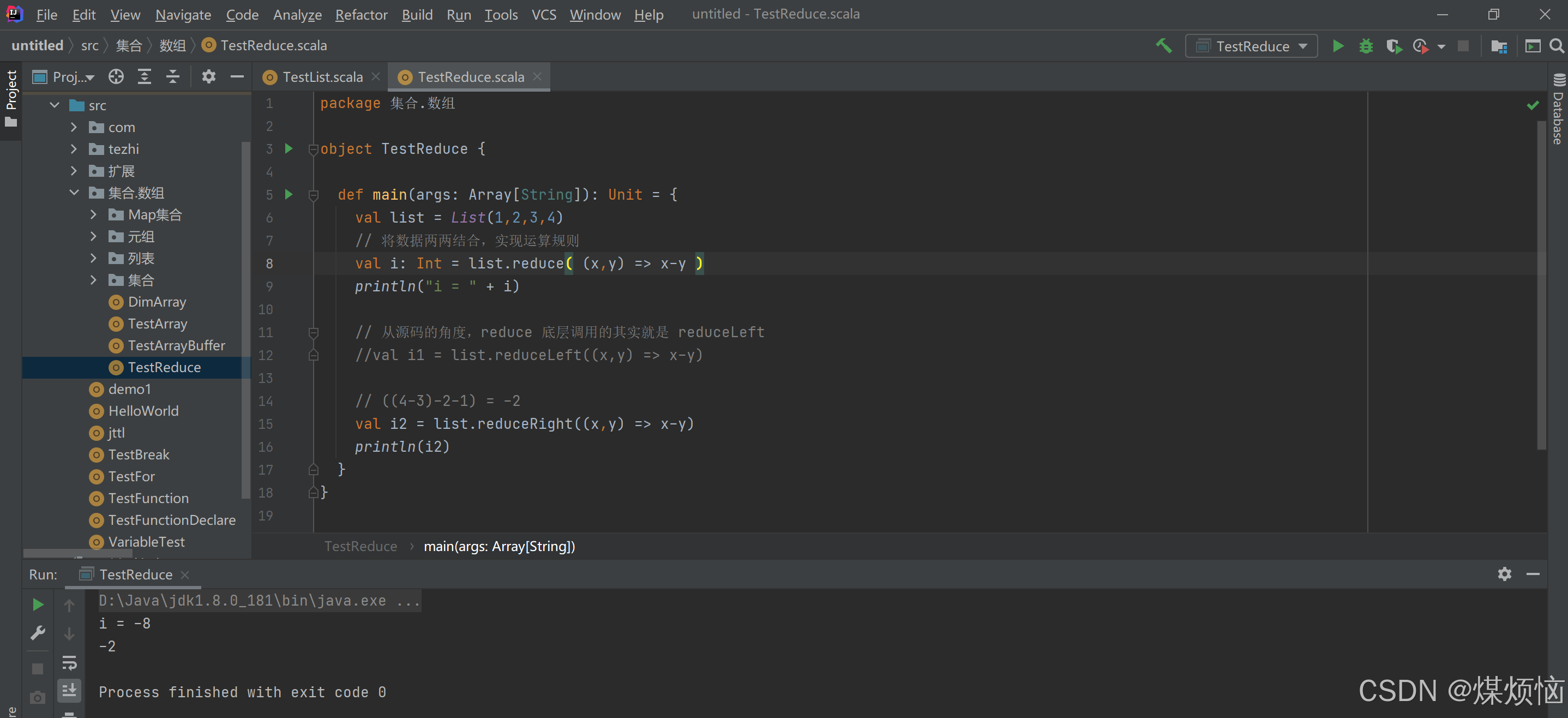
- Fold方法
Fold 折叠:化简的一种特殊情况。
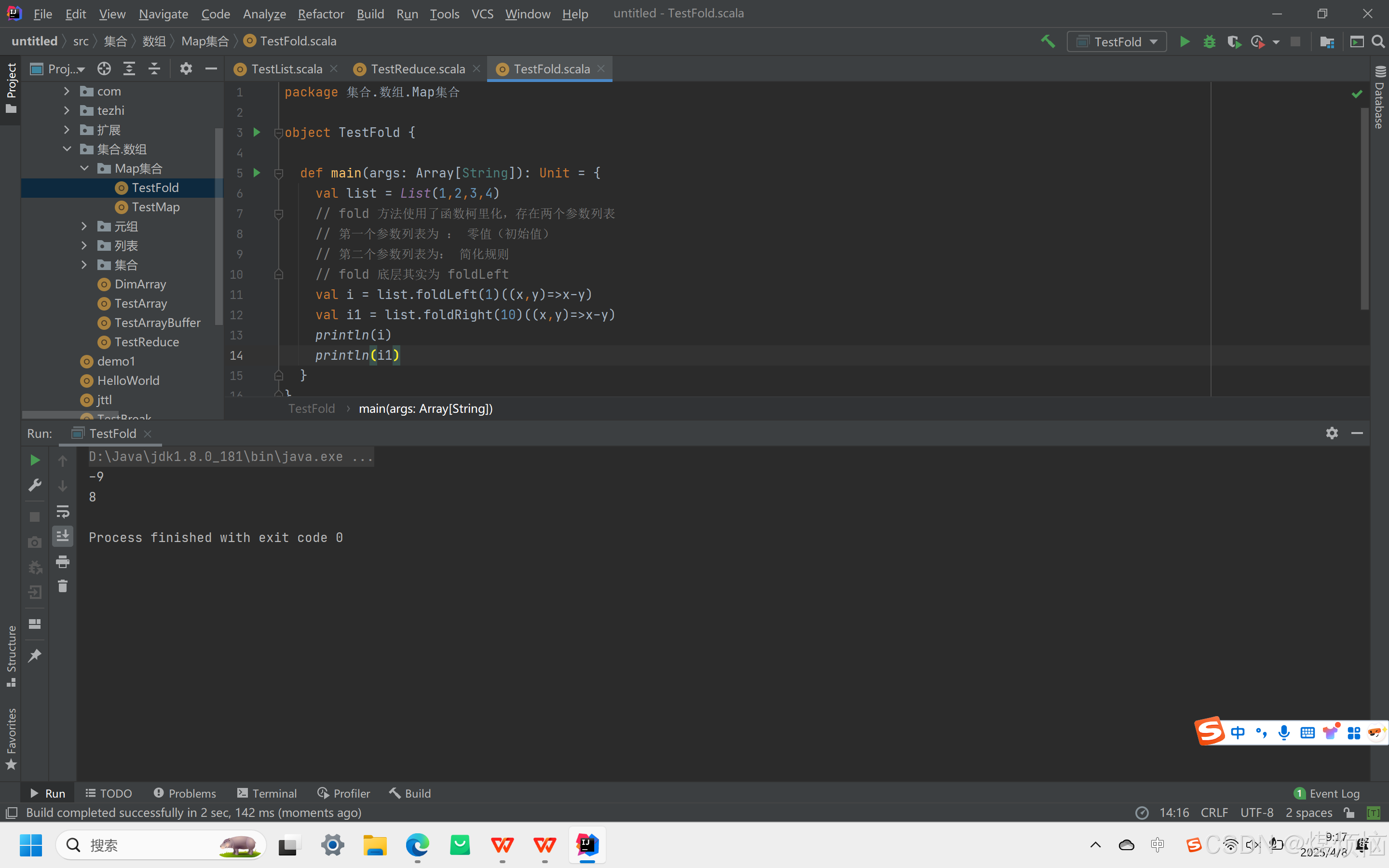
- 普通 WordCount 案例
实现对集合中单词计数并取排名前三结果。步骤为将字符串拆分成单词、相同单词分组、统计单词出现次数、按计数降序排序、取前三个结果。
对List("Hello Scala Hbase kafka", "Hello Scala Hbase", "Hello Scala", "Hello")操作后可得到出现次数前三的单词及次数。