一 BIO
缺点
- 单线程,每次只处理一个请求,服务端一直阻塞直到与客户端建立连接
- 服务端每次连接都会申请一个新的acceptor线程来监听客户端连接,频繁的申请与销毁会消耗很多的资源
- 优化-BIO的多线程模式:优化后的阻塞io,防止**频繁的申请与销毁线程**我们改为使用多线程模式来代替单线程的模式
优点
简单
代码例子
服务端
try {System.out.println("ServerSocket开始");ServerSocket serverSocket = new ServerSocket(8888);while (true) {Socket clientSocket = serverSocket.accept();// 处理客户端连接,可开启新线程进行数据交互//获取输入输出流:InputStream inputStream = clientSocket.getInputStream();OutputStream outputStream = clientSocket.getOutputStream();//数据读写byte[] buffer = new byte[1024];int length = inputStream.read(buffer);String receivedData = new String(buffer, 0, length);outputStream.write("Response".getBytes());//关闭资源inputStream.close();outputStream.close();clientSocket.close();serverSocket.close();}} catch (Exception e) {e.printStackTrace();}客户端
public static void main(String[] args) {try {Socket socket = new Socket("127.0.0.1", 8888);// 连接成功后可进行数据读写操作InputStream inputStream = socket.getInputStream();OutputStream outputStream = socket.getOutputStream();outputStream.write("Message".getBytes());byte[] buffer = new byte[1024];int length = inputStream.read(buffer);String receivedData = new String(buffer, 0, length);System.out.println("服务端返回");inputStream.close();outputStream.close();socket.close();} catch (Exception e) {e.printStackTrace();}}二 NIO详解
参考:Java NIO 详解-CSDN博客
多路复用io模型,同步非阻塞IO。
同步:一个线程负责管理Selector,处理Channel上的事件时还是同步操作,一次只能处理一个事件。
非阻塞:线程在等待数据完全传输过来之前不会被阻塞,可以继续处理其他任务;当数据完全传输完成之后,就可以去处理这个任务了。
服务器实现模式为 一个线程处理多个连接。服务端只会创建一个线程负责管理Selector(多路复用器),Selector(多路复用器)不断的轮询注册其上的Channel(通道)中的 I/O 事件,并将监听到的事件进行相应的处理。每个客户端与服务端建立连接时会创建一个 SocketChannel 通道,通过 SocketChannel 进行数据交互。
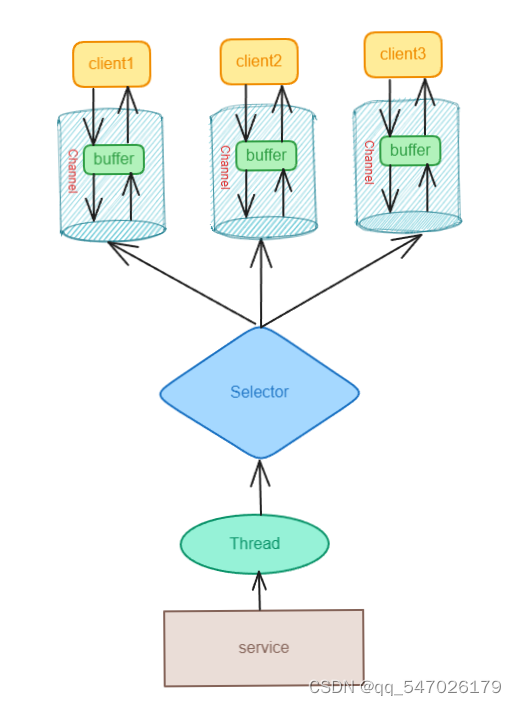
BIO与NIO两者主要区别如下
-
数据处理方式:
-
NIO:以块(缓冲区)的方式处理数据,是同步非阻塞的。NIO模型中,数据读取到一个缓冲区中,需要时可在缓冲区内前后移动,增加了处理过程中的灵活性。线程在等待数据完全传输过来之前不会被阻塞,可以继续处理其他任务。
-
BIO:以流的方式处理数据,是同步阻塞的。在BIO模型中,数据的读取和写入必须阻塞在一个线程内等待其完成。当进行数据读写时,如果数据没有准备好,线程会被阻塞,直到操作完成。
-
-
线程模型:
-
NIO:使用选择器(Selector)来监听多个通道的事件(如连接请求、数据到达等),因此使用单个线程就可以监听多个客户端通道。这种模型降低了线程数量和资源消耗,提高了系统的并发性和资源利用率。
-
BIO:采用一个连接一个线程的模式。当客户端有连接请求时,服务器端需要启动一个线程进行处理。如果连接不做任何事情,会造成不必要的线程开销,对服务器资源要求较高,且并发性较差。
-
-
内存消耗:
-
NIO 中使用的缓冲区(Buffer)可以重复利用,减少了频繁的内存分配和回收,从而减少了内存的消耗。
-
BIO:每个客户端连接都需要单独分配一个缓冲区,容易造成内存的浪费。
-
三 多路复用io :DMA控制器
参考:https://zhuanlan.zhihu.com/p/11661880208
描述:是一种并发处理多个I/O操作的机制。它允许一个进程或线程同时监听多个文件描述符
(如套接字 socket、管道channel、标准输入input/output等)的I/O事件,并在有事件发生时进行处理。
文件描述符:linux系统中一切都是以文件的形式存在的:每一个网络连接在内核中都是以文件描述符file descriptor,简称fd
I/O 多路复用方式
select:select是最早的一种 I/O 多路复用方式,可以同时监听多个文件描述符的可读、可写和异常事件。通过在调用select时传递关注的文件描述符集合,及时返回有事件发生的文件描述符,然后应用程序可以对这些文件描述符进行读写操作。poll:poll是select的一种改进版,也能够同时监听多个文件描述符的可读、可写和异常事件。通过调用poll时传递关注的文件描述符数组,返回有事件发生的文件描述符,应用程序执行对应的读写操作。epoll:epoll 是 Linux 特有的一种 I/O 多路复用机制,相较于 select 和 poll 具有更高的性能,适用于高并发环境。epoll 使用了回调机制来通知应用程序文件描述符上的事件发生,并且支持水平触发(LT,level triggered)和边缘触发(ET,edge triggered)两种模式。
select方式
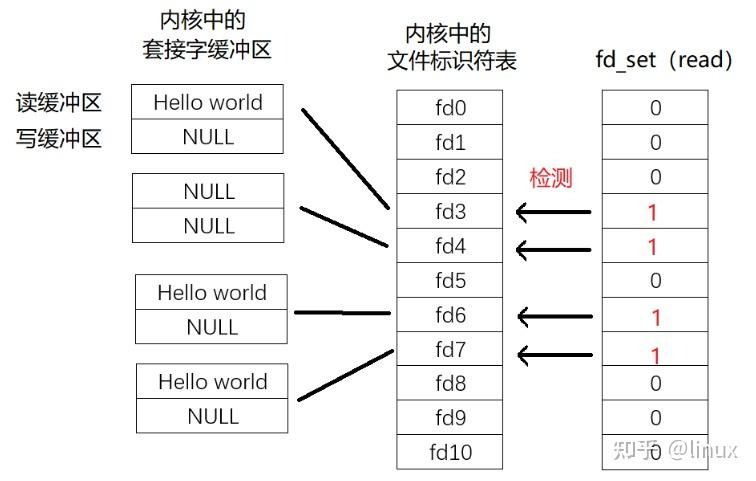
select 函数在阻塞过程中,主要依赖于一个名为 fd_set 的数据结构来表示文件描述符集合。通过向 select 函数传递待检测的 fd_set 集合,可以指定需要检测哪些文件描述符。
select函数原型
将rset从用户态拷贝到内核态去判断,到底哪个fd是有可读事件发生
int select(int nfds, fd_set *readfds, fd_set *writefds,fd_set *exceptfds, struct timeval *timeout);-
nfds:需要监视的最大文件描述符加1,即待监视的文件描述符的最大值加1。-
max+1 传入的原因:fds=1,2,3,5,9 那么 max+1 = 10,内核中就会在rset的 前十个元素中遍历判断哪些fd是有事件发生了
-
-
readfds:可读性检查的文件描述符集合。 -
writefds:可写性检查的文件描述符集合。 -
exceptfds:异常条件的文件描述符集合。 -
timeout:最长等待时间,也可以设置为 NULL,表示一直阻塞直到有事件发生。
操作fd_set的API
void FD_CLR(int fd, fd_set *set);int FD_ISSET(int fd, fd_set *set);void FD_SET(int fd, fd_set *set);void FD_ZERO(fd_set *set);1. FD_ZERO(fd_set *set):清空指定的文件描述符集合 set,将其所有位都置为0。
2. FD_SET(int fd, fd_set *set):将指定的文件描述符 fd 添加到文件描述符集合 set 中,相应的位将被置为1。
3. FD_CLR(int fd, fd_set *set):将指定的文件描述符 fd 从文件描述符集合 set 中移除,相应的位将被清零(置为0)。
4. FD_ISSET(int fd, fd_set *set):检查指定的文件描述符 fd 是否在文件描述符集合 set 中,如果存在,则返回非零值(true);否则,返回零值(false)。
select的缺点
1、每次都需要重新初始化fd_set,重新判断fds[]数组中哪些有数据准备好了,也就是说rset bitmap不可以重用。 因为你下次在判断的时候你也不知道之前的fb上到底有没有数据,所以需要重新判断。
2、文件描述符是有上限的,由fd_set大小决定,1024个为上限。
3、每次都需要将fd_set从用户态切换到内核态去处理,有较大的开销。
4、for循环遍历两遍fbs[],来判断到底是哪几个fb有数据可以处理
poll方式
poll 函数是一种 I/O 多路复用机制,类似于 select 函数,但相比 select 更加高效和灵活。poll 通过轮询方式,在用户空间和内核空间之间进行交互。
与 select 不同的是,poll 可以支持更大的文件描述符集合,且不会有文件描述符数量限制的问题。同时poll与select不同,select有跨平台的特点,而poll只能在Linux上使用。
epoll方式
类似于NIO的处理方式:epoll模型使用一个文件描述符(epoll fd)来管理多个其他文件描述符(event fd)。在epoll fd上注册了感兴趣的事件,当有感兴趣的事件发生时,epoll会通知应用程序。
也就是使用的是事件监听模型,并不是阻塞等待的模型。
epoll fd:也就相当于管理selector的线程
event fd:io事件,channel。
使用场景:Redis, ngnix, java nio linux操作系统下
红黑树模型是重点:快速查找fd对应的事件信息,而且有序,适合高并发连接下的io。
在epoll模型中,当应用程序调用epoll_ctl函数注册事件时,epoll将会将文件描述符和其对应的事件信息存储到红黑树中,这样可以方便地查询和管理事件。
红黑树的高效查询特性可以快速找到特定文件描述符对应的事件信息,并且可以保持事件信息的有序性。
当有事件发生时,epoll调用epoll_wait函数去查询红黑树上已注册的事件,如果有匹配的事件发生,就会通知应用程序进行处理。
红黑树是epoll实现高效I/O多路复用的关键技术之一。通过使用红黑树,epoll可以将事件的查询、插入和删除等操作的时间复杂度降低到O(log n),使得在大规模并发连接的场景下也能够高效地处理事件。