KMP算法的基本思路是:
当我们发现某一个字符不匹配的时候,由于已经知道之前遍历过的字符,因此可以利用这些信息来避免暴力算法中“回退”的步骤
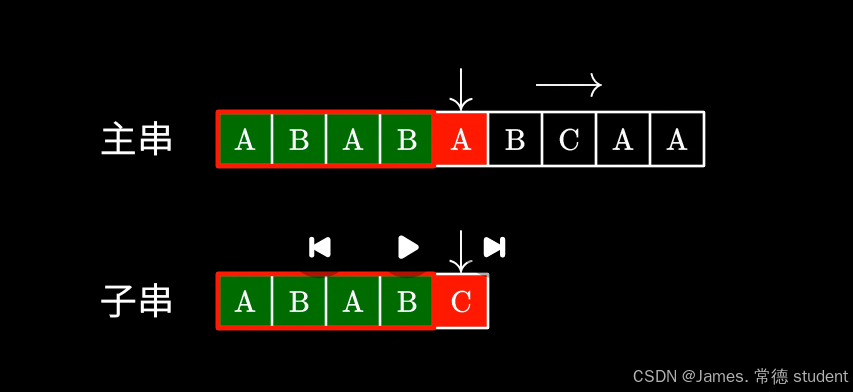
也就是希望主串中的指针永远向前方移动。
相关代码如下:
# kmp 算法的核心,主要是使用到next数组
def kmp_search(string, patt):next = build_next(patt)i = 0 # 主串中的指针j = 0 # 子串中的指针while i < len(string):if string[i] == patt[j]: # 字符匹配,指针后移i += 1j += 1elif j > 0: # 字符匹配失败,根据next跳过子串前面的一些字符j = next[j - 1]else: # 子串第一个字符就失配i += 1if j == len(patt): # 配置成功return i - jnext数组:KMP算法在匹配失败的时候,会去看最后一个匹配的字符它所对应的next数值。移动子串,直接跳过前面的相对应数量的字符
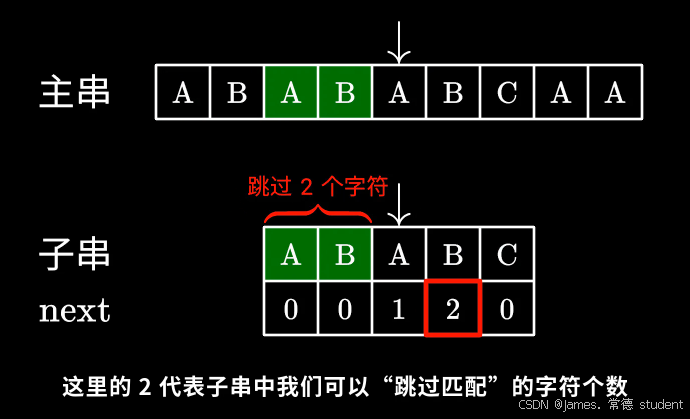
标准代码如下:
# next 数组的生成
def build_next(patt):"""计算next数组:param patt::return:"""next = [0] # next数组(初值元素第一个为 0 )prefix_len = 0 # 当前共同前后缀的长度i = 1while i < len(patt):if patt[prefix_len] == patt[i]:# 要是下一个字符依然相同的话,长度加一即可prefix_len += 1next.append(prefix_len)i += 1else:# 要是长度不同的话if prefix_len == 0:# 要是不存在的话,将next数组设为0即可next.append(0)i += 1else: # 直接查表看看其中有没有更短的前后缀prefix_len = next[prefix_len - 1]return next