Ollama详解,无网环境导入运行本地下载的大模型,无网环境pycharm插件大模型调用
- ollama
- 环境变量配置
- 更改模型存储位置:设置 OLLAMA_MODELS 环境变量
- 修改监听地址:设置 OLLAMA_HOST 环境变量
- Ollama 自定义在 GPU 中运行
- 前提条件
- 指定使用的 GPU
- 常用命令
- ollama serve
- 本地下载的gguf如何导入ollama
- 如何将Hugging Face的SafeTensors模型转换为GGUF格式,以便在ollama平台上运行
- 自定义 Prompt
- 无网环境Pycharm插件Proxy AI调用本地大模型
- 参考

ollama
Ollama 是一个开源的大型语言模型服务工具,旨在帮助用户快速在本地运行大模型。通过简单的安装指令,用户可以通过一条命令轻松启动和运行开源的大型语言模型。 它提供了一个简洁易用的命令行界面和服务器,专为构建大型语言模型应用而设计。用户可以轻松下载、运行和管理各种开源 LLM。与传统 LLM 需要复杂配置和强大硬件不同,Ollama 能够让用户在消费级的 PC 上体验 LLM 的强大功能。
Ollama 会自动监测本地计算资源,如有 GPU 的条件,会优先使用 GPU 的资源,同时模型的推理速度也更快。如果没有 GPU 条件,直接使用 CPU 资源。
Ollama 极大地简化了在 Docker 容器中部署和管理大型语言模型的过程,使用户能够迅速在本地启动和运行这些模型。
Ollama 支持的模型库列表 https://ollama.com/library
注意:运行 7B 模型至少需要 8GB 内存,运行 13B 模型至少需要 16GB 内存,运行 33B 模型至少需要 32GB 内存。
环境变量配置
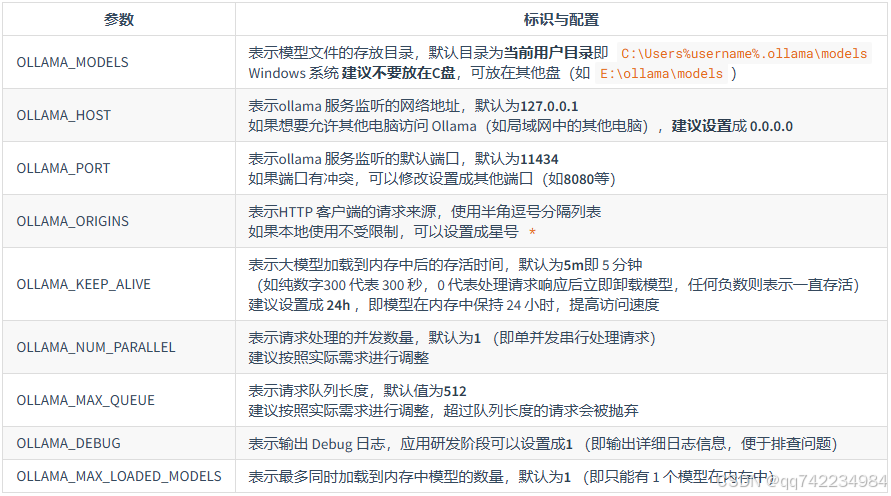
更改模型存储位置:设置 OLLAMA_MODELS 环境变量
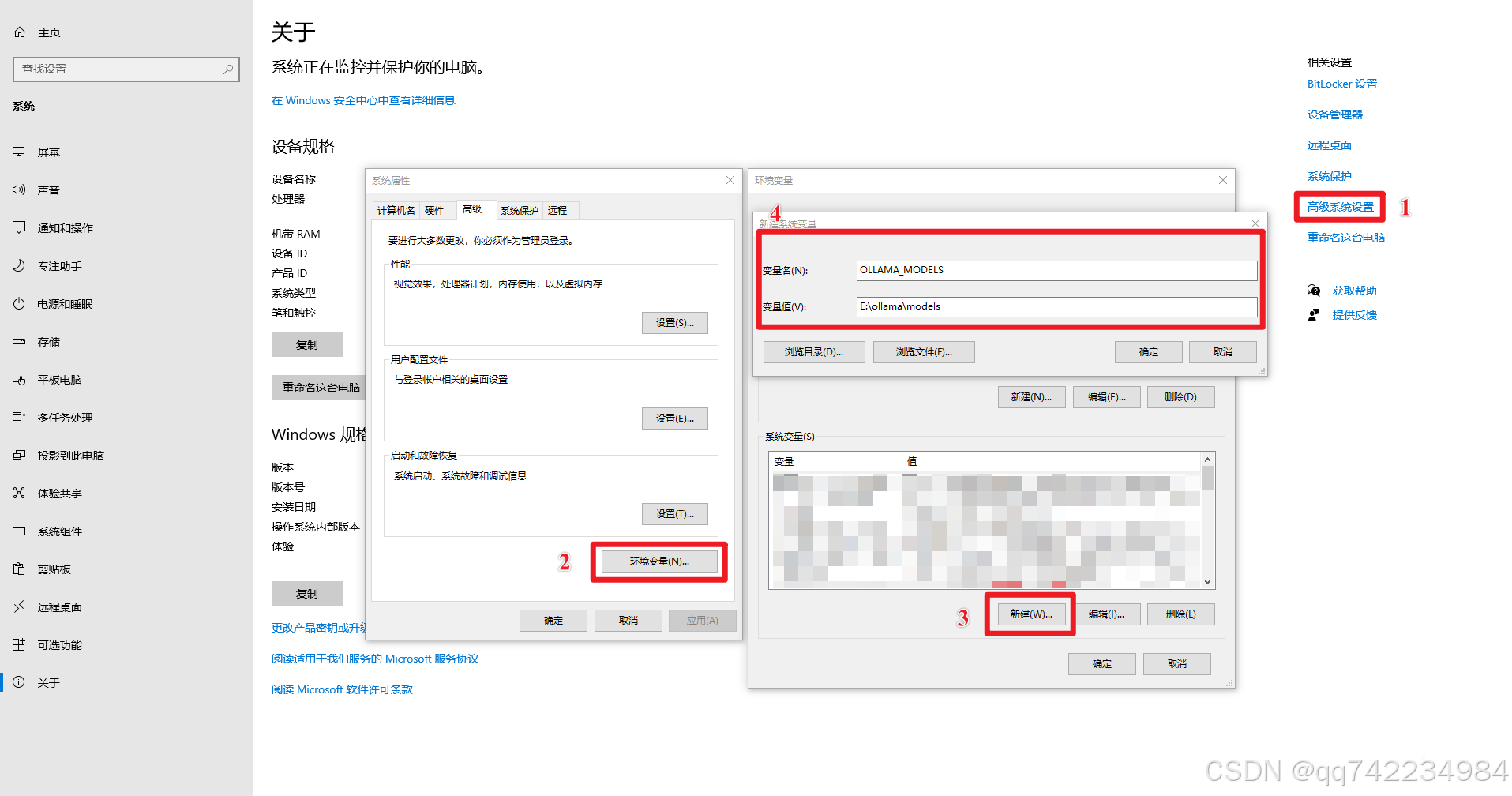
修改监听地址:设置 OLLAMA_HOST 环境变量
- 0.0.0.0 表示监听所有网络接口,允许局域网访问。
- 11434 是 Ollama 默认端口。
验证环境变量是否生效 echo %OLLAMA_MODELS%
Ollama 自定义在 GPU 中运行
Ollama 默认情况下使用 CPU 进行推理。为了获得更快的推理速度,可以配置 Ollama 使用的 GPU。
前提条件
- 电脑有 NVIDIA 显卡。
- 已安装 NVIDIA 显卡驱动程序,可以使用命令
nvidia-smi来检查驱动程序是否安装。 - 已安装 CUDA 工具包,可以使用命令
nvcc --version来检查 CUDA 是否安装。
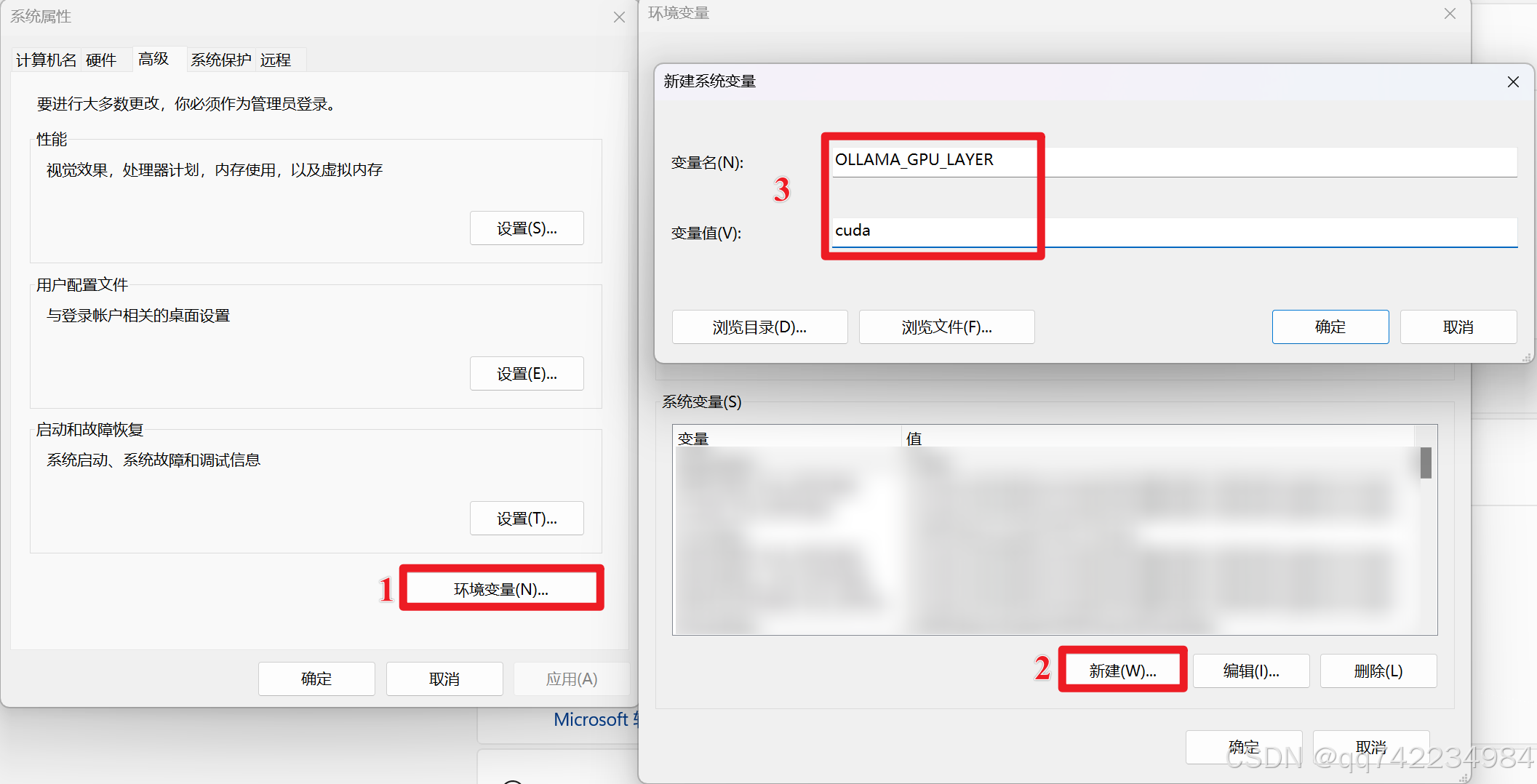
指定使用的 GPU
如果你的系统有多个 GPU,并且你想指定 Ollama 使用特定的 GPU,可以设置 CUDA_VISIBLE_DEVICES 环境变量。
-
查找 GPU 的 UUID: 强烈建议使用 UUID 而不是编号,因为编号可能会因为驱动更新或系统重启而发生变化。
-
打开命令提示符或 PowerShell。
- 运行命令:
nvidia-smi -L - 在输出中,找到想要使用的 GPU 的 “UUID” 值。
- 运行命令:

-
创建 CUDA_VISIBLE_DEVICES 变量:
- 变量名: CUDA_VISIBLE_DEVICES
- 变量值: 找到的 GPU 的 UUID。 例如:GPU-xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx
-
运行 Ollama。 新开一个命令提示符窗口,使用
ollama ps命令查看 Ollama 运行的进程。

常用命令

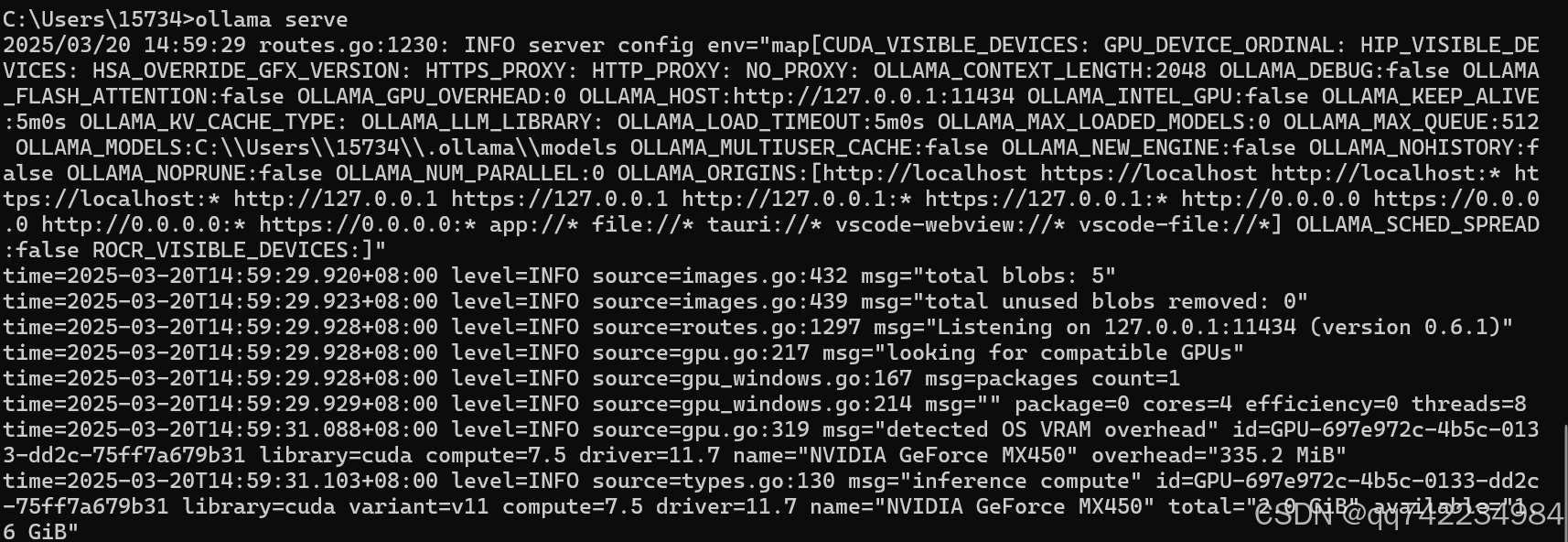
ollama serve
运行ollama,提示报错
Error: listen tcp 127.0.0.1:11434: bind: Only one usage of each socket address (protocol/network address/port) is normally permitted.
解决方法:禁用自启,结束进程,重启服务。
本地下载的gguf如何导入ollama
1.ollama安装是否成功
2.将model放在文件夹下,创建一个txt配置文件,如下所示:
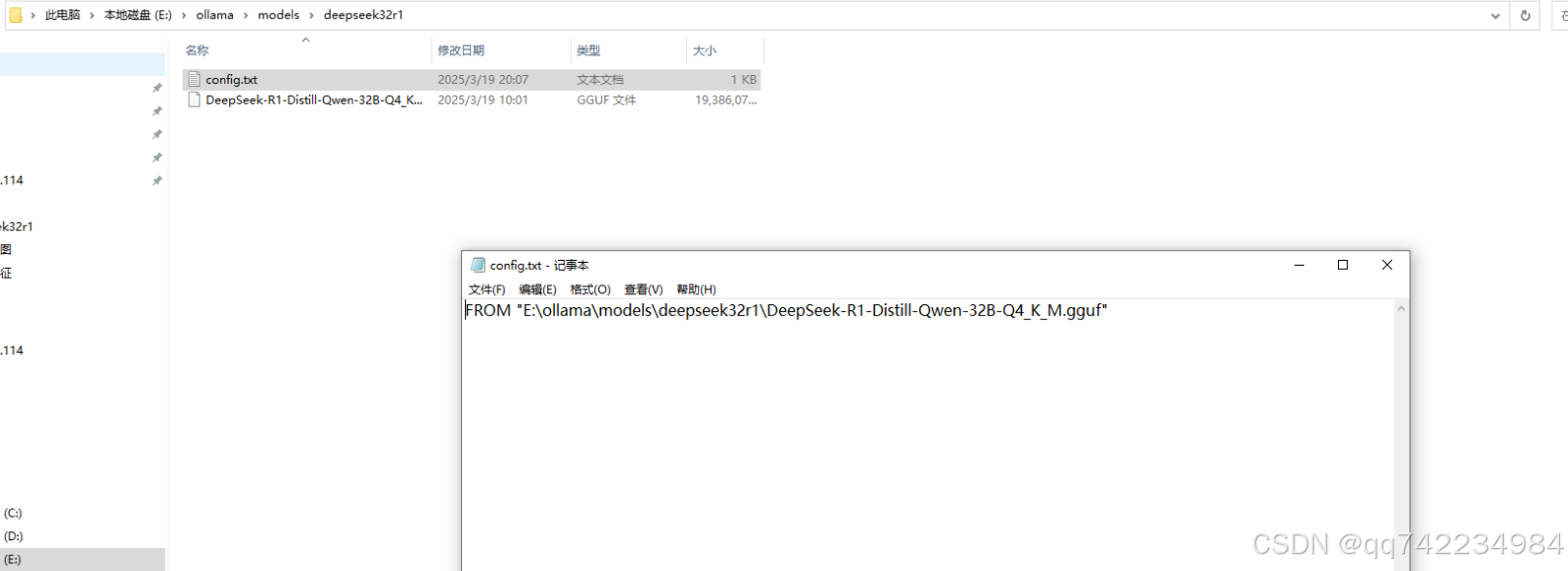
3. 打开cmd,导航到你的配置文件所在路径; 在cmd中输入以下命令:ollama create 模型的名字 -f config.txt。
4. 等待ollama完成模型的创建和部署;使用ollama list验证模型是否部署完成。

5. 使用ollama run qwen2:0.5b运行。
多行输入命令时,可以使用 “”" 进行换行;使用 “”" 结束换行。终止 Ollama 模型推理服务,可以使用 /bye。

注意:Ollama 进程会一直运行,如果需要终止 Ollama 所有相关进程,可以使用以下命令:
Get-Process | Where-Object {$_.ProcessName -like '*ollama*'} | Stop-Process
如何将Hugging Face的SafeTensors模型转换为GGUF格式,以便在ollama平台上运行
Safetensors 是一种用于存储深度学习模型权重的文件格式,它旨在解决安全性、效率和易用性方面的问题。
1.从https://opencsg.com/models下载模型。
2.使用 llama.cpp https://github.com/ggml-org/llama.cpp 进行转换。llama.cpp 是 GGML 主要作者基于最早的 llama 的 c/c++ 版本开发的,目的就是希望用 CPU 来推理各种 LLM。克隆 llama.cpp 库到本地,与下载的模型放在同一目录下。
git clone https://github.com/ggerganov/llama.cpp.git
3.使用 llama.cpp 转换模型的流程基于 python 开发,需要安装相关的库,推荐使用 conda 或 venv 新建一个环境。
cd llama.cpp
pip install -r requirements.txt
python convert_hf_to_gguf.py -h
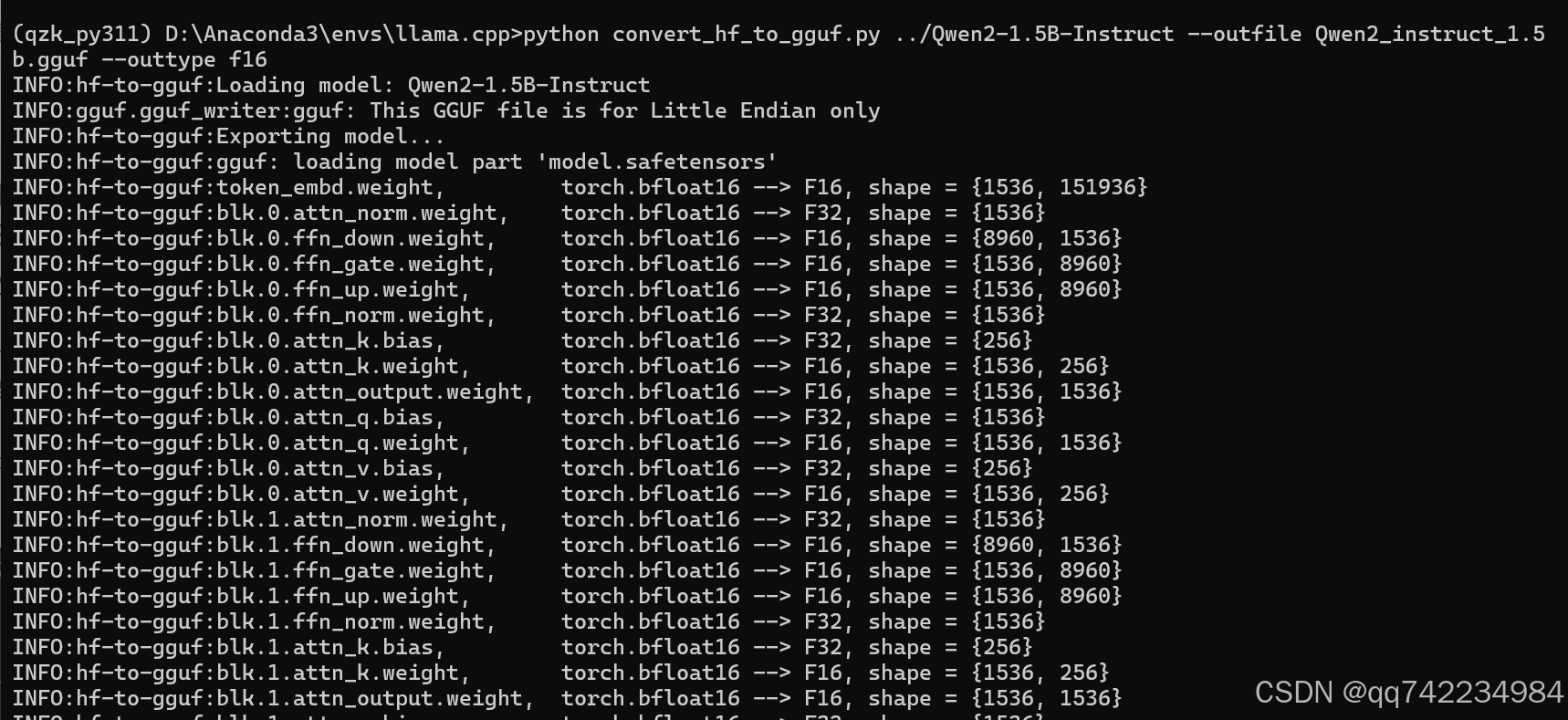
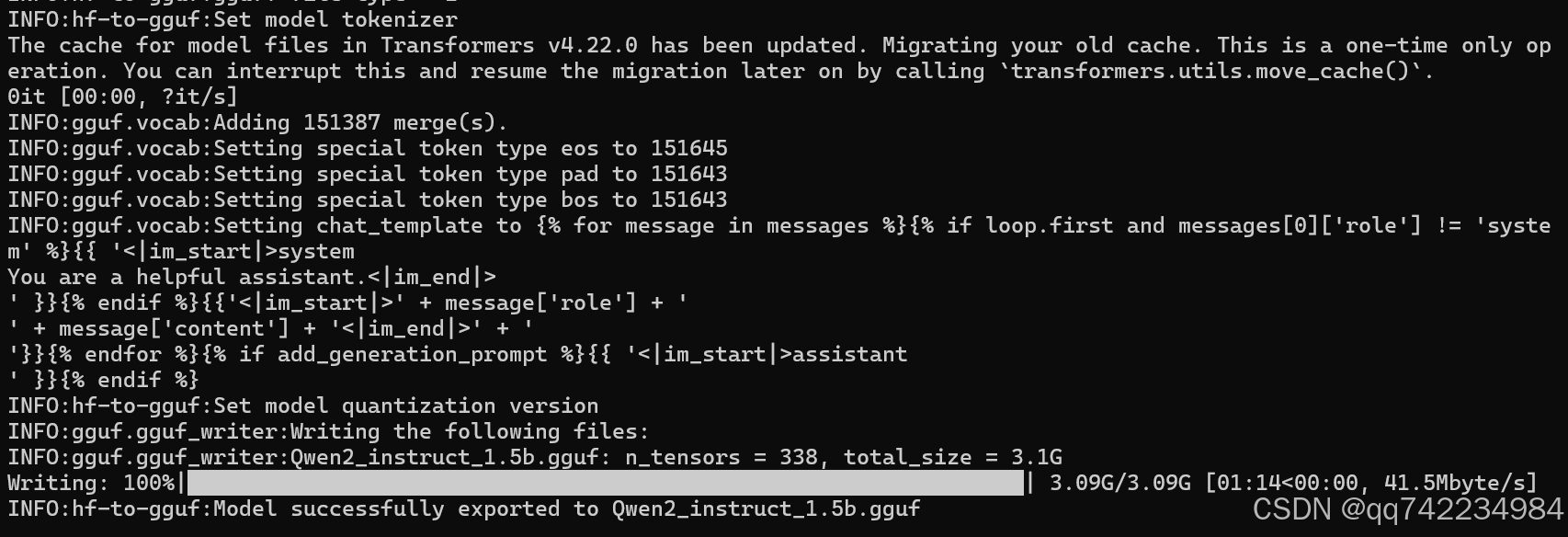
python convert_hf_to_gguf.py ../Qwen2-1.5B-Instruct --outfile Qwen2_instruct_1.5b.gguf --outtype f16
4.使用llama.cpp进行模型量化
模型量化是一种技术,将高精度的浮点数模型转换为低精度模型,模型量化的主要目的是减少模型的大小和计算成本,尽可能保持模型的准确性,其目标是使模型能够在资源有限的设备上运行,例如CPU或者移动设备。
-
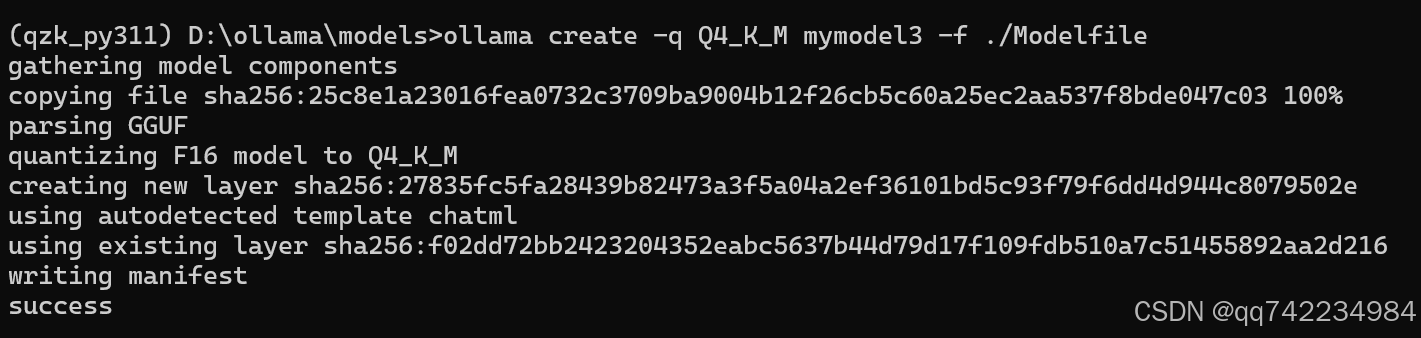
创建 Modelfile 文件,编写以下内容:
FROM ./Qwen2_instruct_1.5b.gguf -
ollama create -q Q4_K_M mymodel3 -f ./Modelfile(Q4_K_M 是一种 4 位(4-bit)量化格式。)
自定义 Prompt
Ollama 支持自定 义Prompt,可以让模型生成更符合用户需求的文本。
- 根目录下创建一个 Modelfile 文件
FROM llama3.1
# sets the temperature to 1 [higher is more creative, lower is more coherent]
# 设置温度为1[越高越有创意,越低越连贯]
PARAMETER temperature 1
# sets the context window size to 4096, this controls how many tokens the LLM can use as context to generate the next token
# 设置上下文窗口大小为4096,这控制了LLM可以使用多少令牌作为上下文来生成下一个令牌
PARAMETER num_ctx 4096# sets a custom system message to specify the behavior of the chat assistant
# 设置自定义系统消息来指定聊天助手的行为
# SYSTEM You are Mario from super mario bros, acting as an assistant.
SYSTEM 你是一位在数学竞赛、数学建模竞赛、大数据竞赛以及人工智能(涵盖深度学习、大模型和机器学习)领域拥有卓越成就的专家型 AI。擅长以生动、有趣且浅显易懂的方式,为用户深入阐释相关知识,同时还能根据要求生成图像并进行说明。
- 创建模型
ollama create mymodel -f ./Modelfile
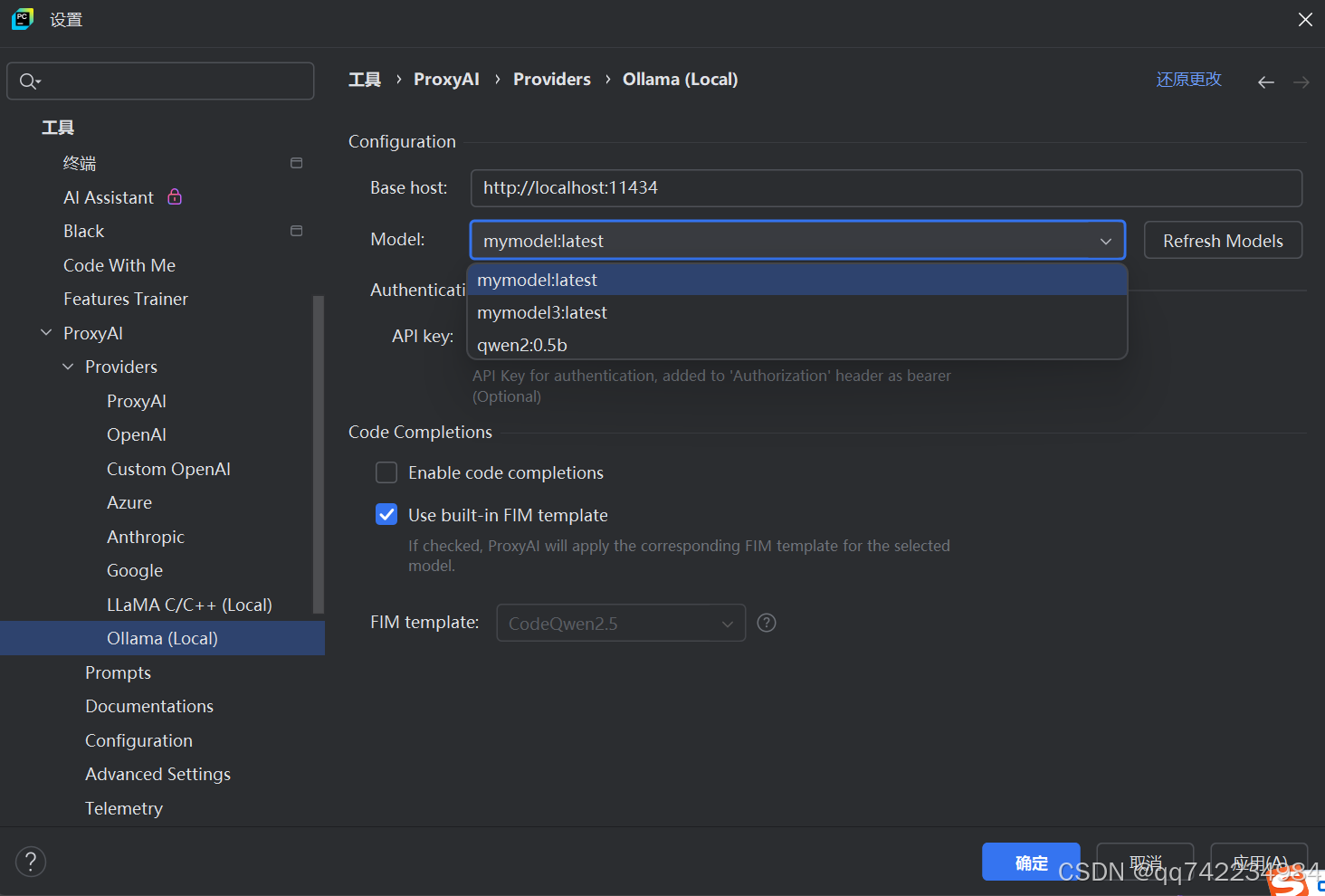
无网环境Pycharm插件Proxy AI调用本地大模型
https://plugins.jetbrains.com/plugin/21056-proxy-ai
Proxy AI 可以在无网环境下不需要登录即可使用
参考
1.https://ollama.com/
2.https://lmstudio.ai/
3.https://manus.im/
4.https://www.trae.com.cn/?utm_campaign=r1
5.https://datawhalechina.github.io/handy-ollama/#/