前言:
在上章介绍了整形在内存的储存,了解了原码,反码,补码,知道了整数在内存的储存一般是补码,解决了负数相加的问题。
那么在本章为大家讲解一下大小端字节序。
一·那字节序是什么呢?
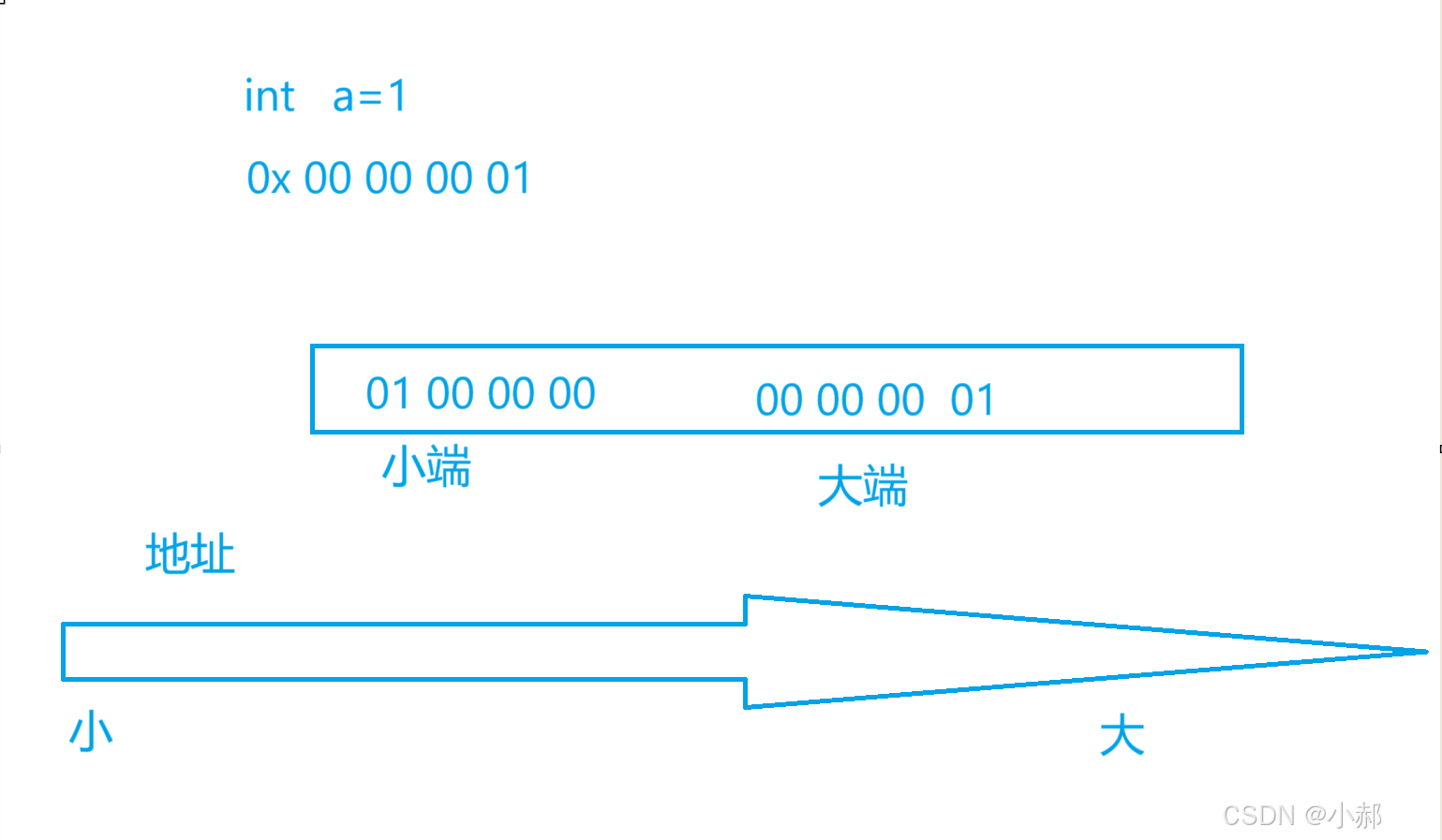
字节序(Endianness)决定了多字节数据在内存中的存放顺序。例如,一个32位整数 0x12345678 占4个字节,其存储方式因字节序而异:
在计算机系统中,多字节数据(如整数、浮点数)的存储方式有两种截然不同的策略:大端字节序(Big-Endian)和小端字节序(Little-Endian)。
二·大小端字节序又是什么?
-
高位字节是,低位字节可以,类比123(一百二十三),1就是高位字节,3就是低位字节
-
大端模式:高位字节在前(低地址),低位字节在后。
-
内存布局:
12 34 56 78(地址由低到高) -
类比:书写数字时从左到右(如“1234”直接存储为
12 34)。
-
-
小端模式:低位字节在前(低地址),高位字节在后。
-
内存布局:
78 56 34 12(地址由低到高) -
类比:倒序书写数字(如“1234”存储为
34 12)。
-
练习
1.
欧克,基本了解了大小端字节序,那么我们如何知道他是用哪种方法储存的呢?
大家思考一下!!
#include <stdio.h>
int main()
{int a = 1;if (*(char*)&a == 1){printf("小端");}return 0;
}这里为什么要转化成char的形式呢?
因为char单位是一个字节,而我们所需要的也是第一个字节,所以将它转化一下更好的计算。
这里还可以自定义一个函数,来实现判断,比较简单就过多叙述了。
2.
分析以下代码,计算一下输出的结果。
char a = -1;
signed char b = -1; unsigned char c = -1; printf("a = %d, b = %d, c = %d", a, b, c);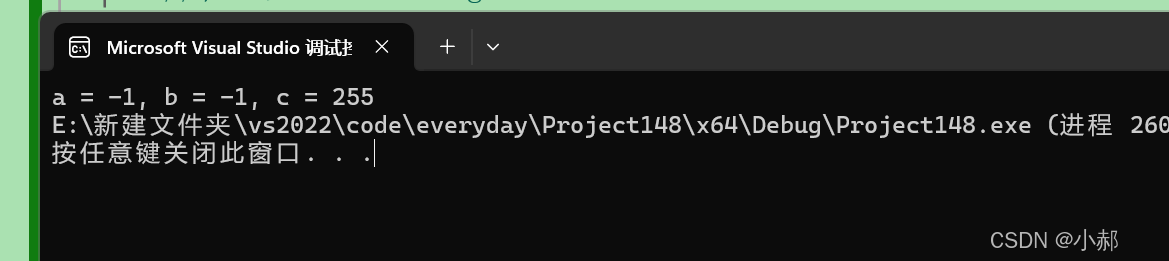
不知道结果是否和你们一样呢
为什么是这样的结果呢?
首先:注意变量的声明与初始化
- 大多数系统中,
char默认是有符号的(即signed char),但具体取决于编译器。大多数编译器(如VS2022)默认char == signed char。。
其次 了解输出的格式
-
printf 函数的格式说明符
%d用于打印有符号整数。%u用于打印无符号整数。
接着:根据所学,知道内存储存的是补码,将他们计算一下
10000000000000000000000000000001
11111111111111111111111111111110
11111111111111111111111111111111 -1的补码11111111 - a
11111111111111111111111111111111 -1的补码
1111111 - b
11111111111111111111111111111111 -1的补码
11111111 - c
欧克将补码写出后就要计算输出了%d形,现在是char,所以说要整形提升
发生整型提升
因为a,b都是有符号的所以说在前补1即可
11111111111111111111111111111111 - a
11111111111111111111111111111111 - b
这就是提升以后的补码,输出是原码即 10000000000000000000000000000001 所以a b输出是-1
那c呢,c是无符号型,无符号型提升的话,在前面补0即
00000000000000000000011111111 - c
这就是c提升后的补码,
注意现在开头是0,是正数,那么正数的原码 反码 补码都相同
所以输出是11111111 即255
2.1
在上面的题目上略加修改 %u
那么结果如何呢
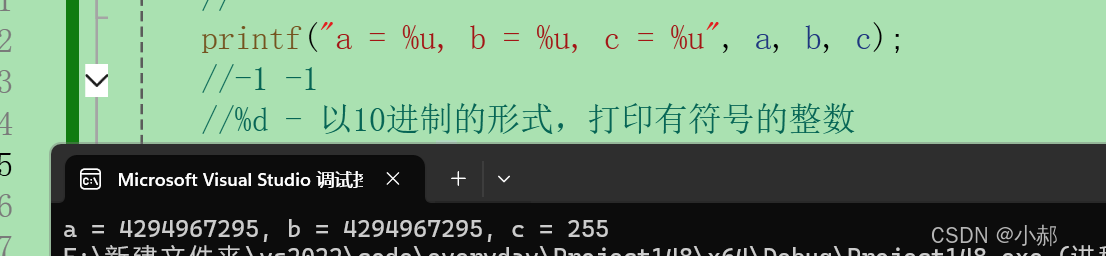
奥哦,why?
有了上题的基础,应该是简单了
1. %u 用于打印无符号整数。
2. 既然是打印无符号的值, 那么不管是什么类型的,它的原码,反码,补码相同的 。
11111111111111111111111111111111 - a
11111111111111111111111111111111 - b
00000000000000000000011111111 - c
总结:
本文了解了原码,反码,补码,以及大小端字节序。
我们更好的了解了数据在内存的储存。
整形提升的规则总结
- 有符号数:正数高位补0,负数高位补符号位。
- 无符号数:高位补0。
- 目标类型:通常为
int类型,但如果int类型无法表示该值,则会扩展为long类型