
CVPR 2021
为了捕捉点云视频中的动态,通常采用点跟踪的方法。但是表示同一位置的点在不同帧中时有时无,使得计算精确的点轨迹非常困难,并且跟踪通常还依赖于点的颜色,因此在缺乏颜色信息的点云中容易失效。
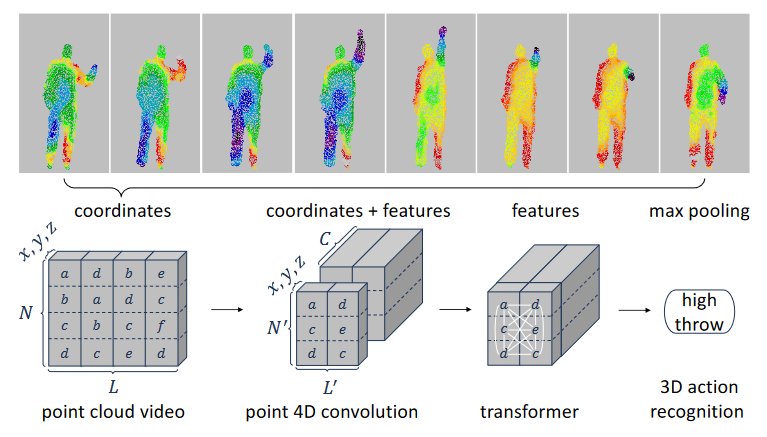
贡献:
1.提出P4Transformer,在时空上建模原始点云视频。
2.为了嵌入时空局部结构,减少Transformer需要处理的数据,我们提出了点4D卷积。
下游任务:3D动作识别和4D语义分割。
Pipeline
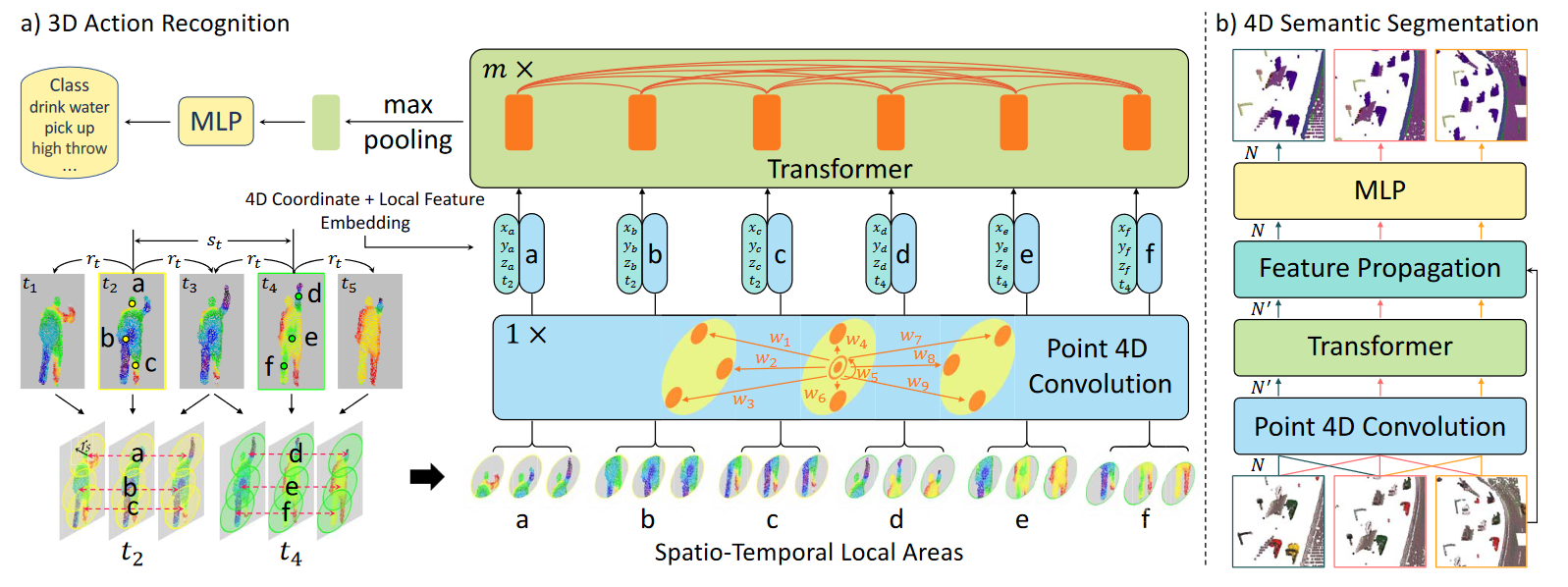
Point 4D Convolution
用卷积捕获局部结构。
先对时空进行解耦。
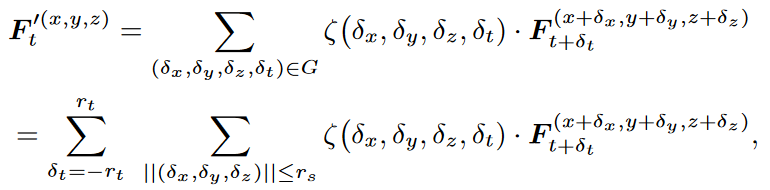
卷积核的权重是位移相关的,不是共享的,由函数ζ生成。
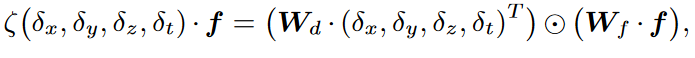
⚪为元素级操作,如加法或乘积。
当Ft不可用时,函数实现为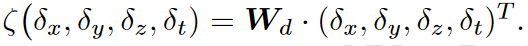
时空卷积区域的确定用的pstnet的方式,构建point tube。
Transformer
旨在根据输入的相似性合并相关的局部区域,使每个点具有更大的感受野。
将锚点坐标(x,y,z,t)和得到的局部特征输入到Transformer中。
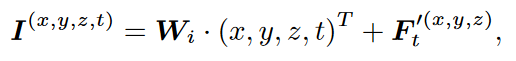 类似于一个embedding的过程。
类似于一个embedding的过程。
对I进行自注意。
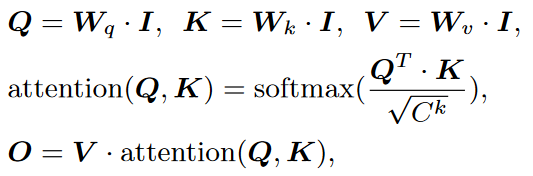
在整个点云视频上运行以捕获整个视频上的注意力信息,且使用了多头等机制进行增强。
下游应用
三维动作识别
先用4D卷积来编码时空局部区域。其次堆叠m个Transformer,以捕获所有编码局部特征的外观和运动信息。然后最大池化将变换后的局部特征合并为单一的全局特征。最后MLP层将全局特征转换为动作预测。
四维语义分割
可以看成point-wise的分类任务。由于用于分割的点云帧通常是高分辨率的,因此堆叠多个4D卷积,以指数级减少Transformer需要处理的点数。由于4D卷积减少了点数,增加特征传播层进行插值。使用基于k近邻的反距离加权平均(这里应该也是保存了原始点坐标)。
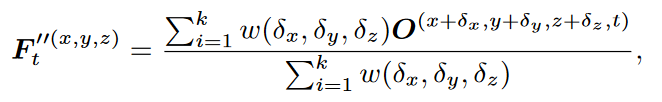
实验
三维动作识别
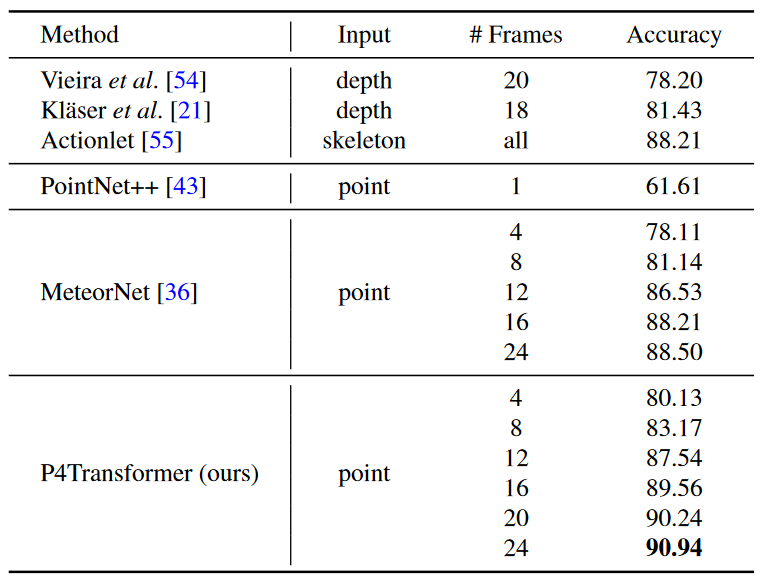
在MSR-Action3D上动作识别的准确率。
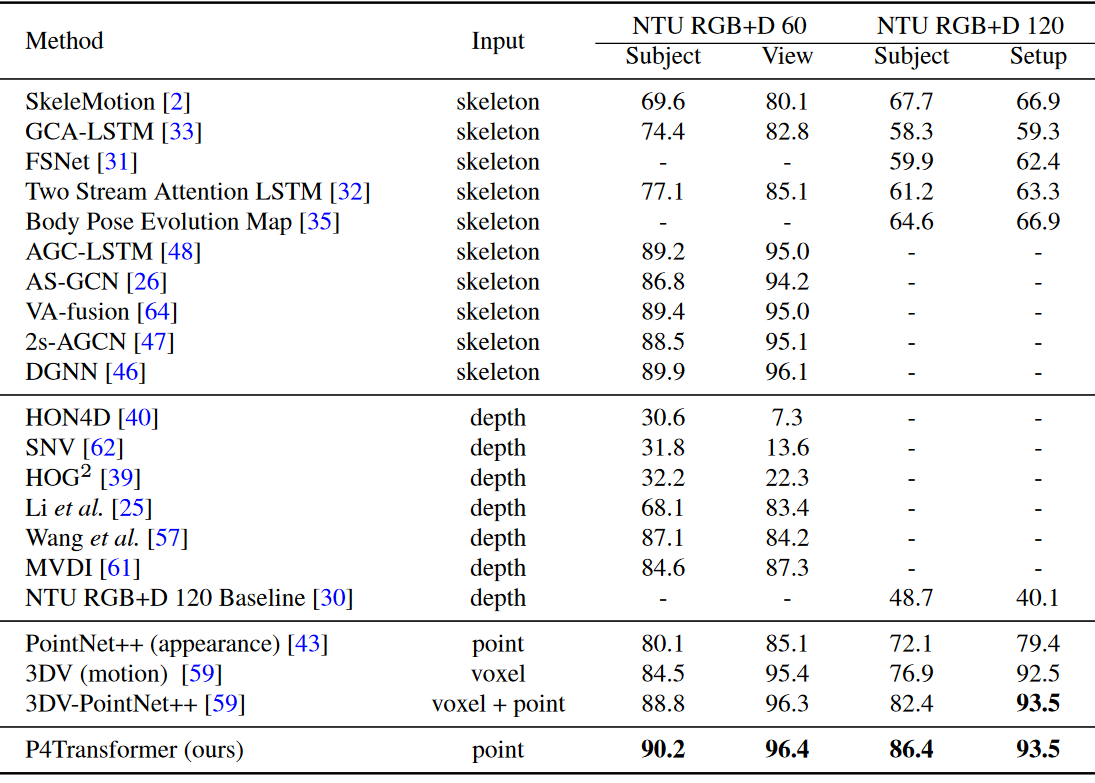
在NTU上动作识别的准确率对比。

在NTU上动作识别的运行时间对比。
四维语义分割
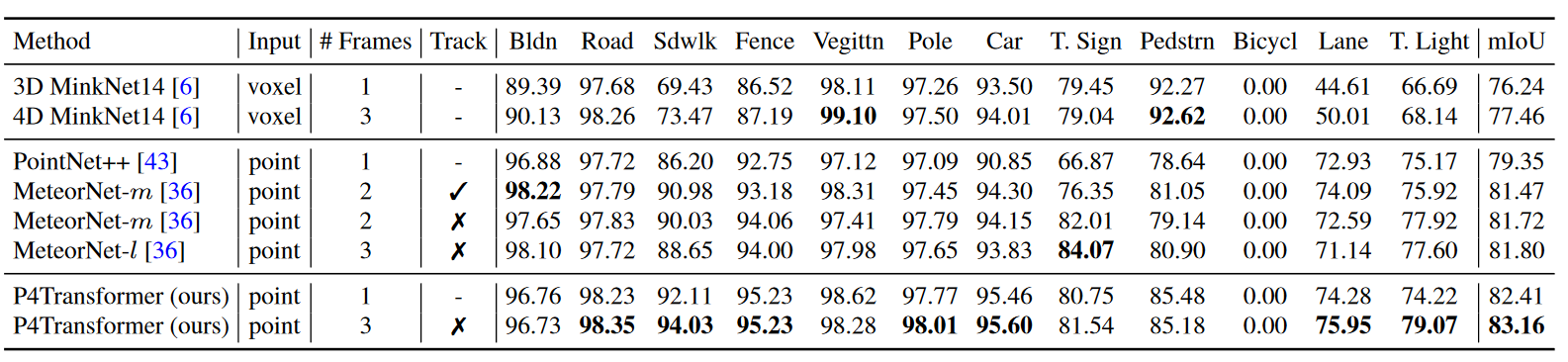
在Synthia上四维语义分割的mIoU对比。
消融实验
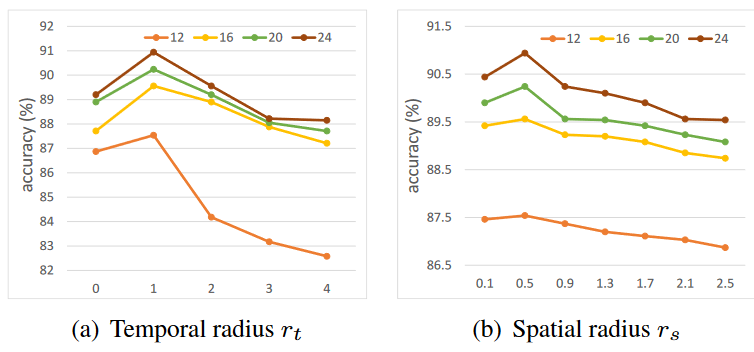
时间卷积步长和空间邻域范围的消融实验。
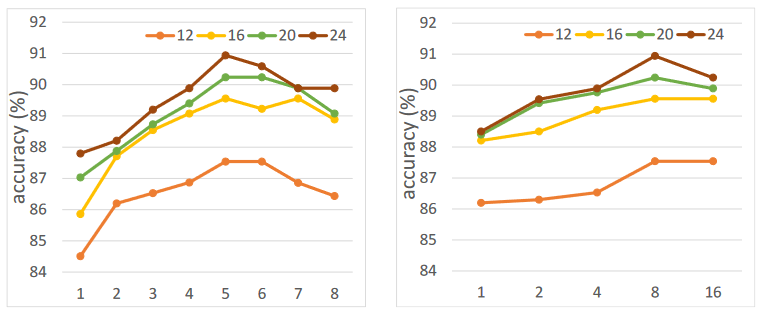
Transformer层数和多头注意力头数的消融实验。
随着Transformer层数的增加,P4Transformer可以达到更好的精度。然而,过多的层数会降低性能。这是因为,当网络变得更深时,梯度可能会消失或爆炸,使得网络难以训练。

帧级和视频级自注意力的消融实验。