0、引言
相信大家对Map这个数据结构都不陌生,像C++的map、Java的HashMap。各个语言的底层实现各有不同,在本篇博客中,我将分享个人对Go的map实现的理解,以及深入源码进行分析,相信耐心看完一定会收获不少。
1、宏观结构
相信大家对于map的基本使用都不陌生,Golang中的map是不允许并发写操作的,这里的写指代的是宏观意义上的“写”,包括了更新、插入、删除操作。当发生了并发写时,程序会抛出fatal,这是一个非常严重的错误,会直接中断程序的进行,因此对于同一个map,它不应该被共享到多个协程中。
我们可以通过以下代码来验证:
func main() {hm := map[int]int{1: 1, 2: 2, 3: 3}for i := 4; i <= 9999; i++ {go func(num int) {hm[i] = i}(i)}
}程序很快就会报错,因为我们有多个协程同时对map进行写入操作。
那么map是怎么保存键值对的呢?
首先,我们得知道map的宏观结构,Go对map的设计采用了桶的思想,有一组组桶来装KV对,并且规定一个桶只能装8个KV对。
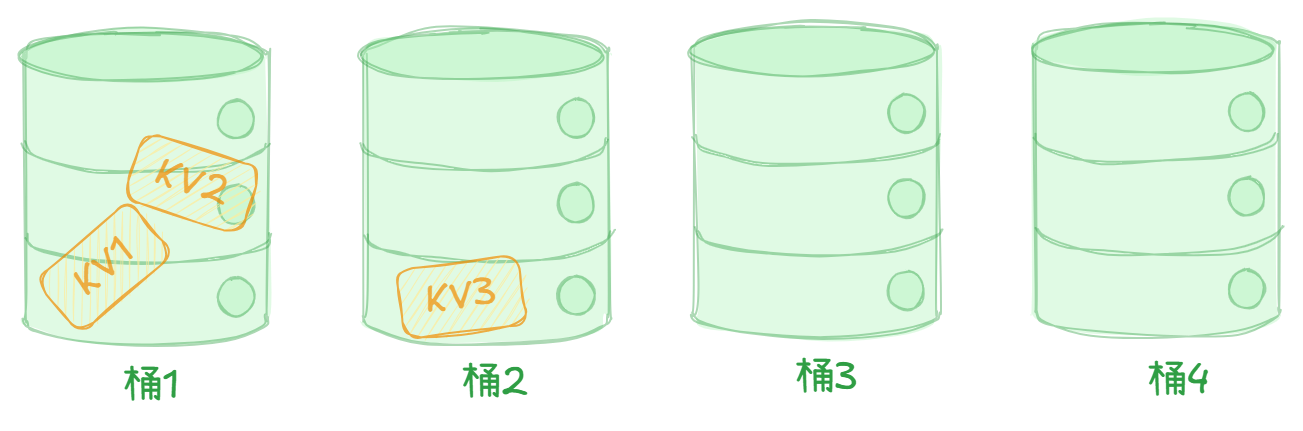
例如我们把KV1和KV2放在桶1中,KV3放在桶2中。假如我们有很多个KV对,只要桶够多,把它们分散在各个桶中,那么就能将O(N)的时间复杂度缩小到O(N/bucketsNum)了,只要给定合适的桶数,时间复杂度就≈O(1)。
于是,我们要解决两个问题:
-
如何找到一个KV对对应的桶?
-
如何保证桶平均下来的KV对数目都是合理的呢?
1.1、如何找到桶?
1、对于第一个问题,采取的措施是使用哈希映射来解决。
假如我们有这样一个函数,它可以使得对于任意长度的输入,都压缩到一个固定长度的输出,并且对于相同的输入,输出必定是一样的。这样子的函数叫做哈希函数,即hash func。具体的可以去网上了解。那么在Go中,它会先求出每个KV的hash值,例如对于一个键值对「“Hello”:“World”」,求出它的hash值为100111101,那么只要对桶数取模即可找到对应的桶了。
对此,我们对hash函数的选取需要有一定的要求,它必须满足以下的性质:
-
hash的可重入性:相同的key,必定产生相同的hash值
-
hash的离散性:只要两个key不相同,不论相似度的高低,产生的hash值都会在整个输出域内均匀地离散化
-
hash的单向性:不可通过hash值反向寻找key
但是,根据hash的性质,因为输入是无限的,但是输出的长度却是固定有限的,所以必然会存在两个不同的key通过映射到了同一个hash值的情况上,这种情况称之为hash冲突。对于Go对hash冲突采取的策略,将会在下文提及。
1.2、如何保证桶平均的KV对数目是合理的?
对于这个问题,我们必须采取一个措施来量化目前的存储状况是否合理。在Go中,引入了负载因子(Load Factor)的概念,对于一个map,假如存在count个键值对,2^B个桶,那么它必须满足以下方程:「count <=LoadFactor*(2^B)」,当count的值超过这个界限,就会引发map的扩容机制。LoadFactor在Go中,一般取值为6.5。
1.3、桶结构
一个map会维护一个桶数组,桶数组中含有多个桶,每个桶可以存放八个键值对,以及一个指向其溢出桶的指针。用图表示如下:
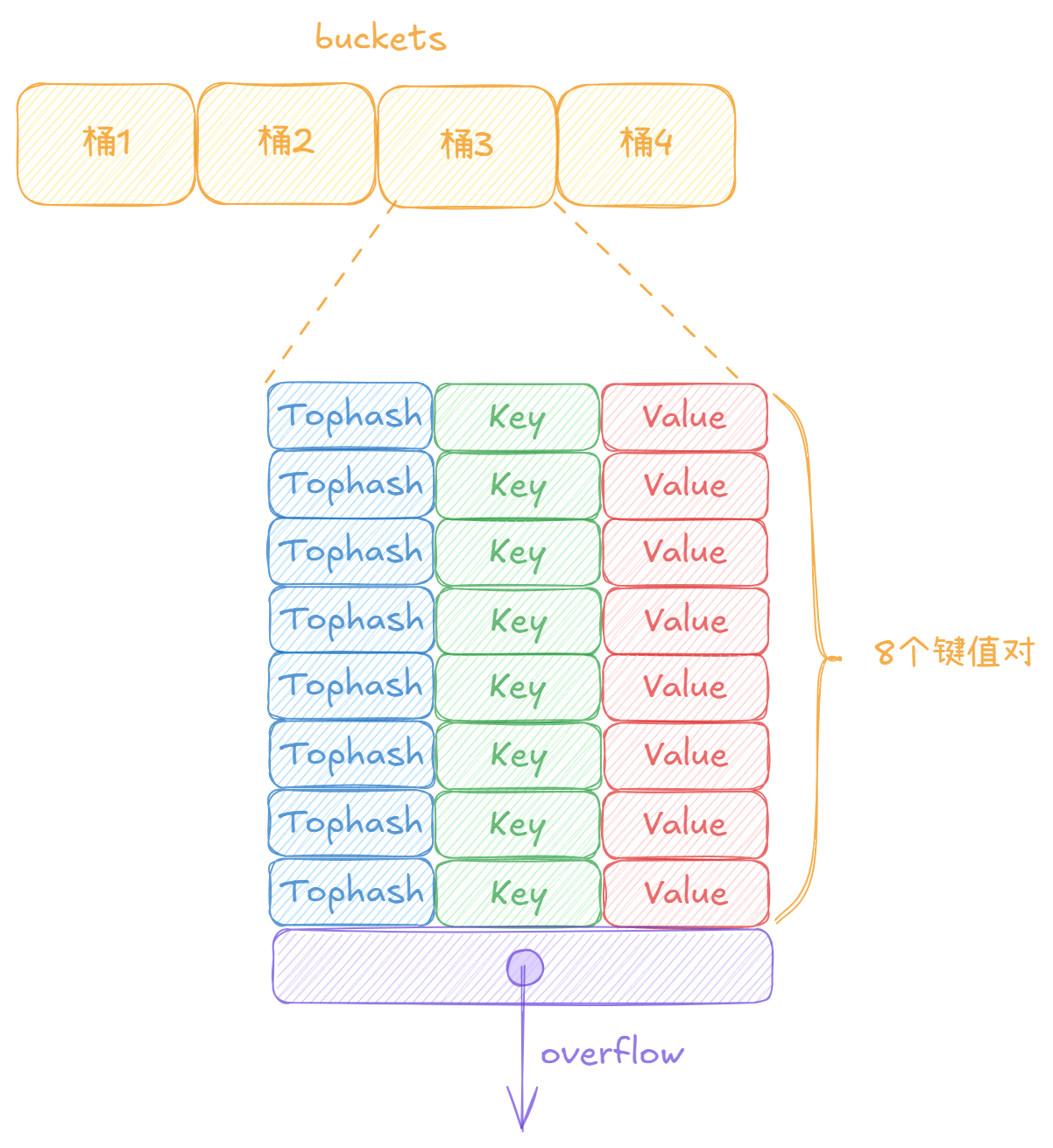
对于一个桶,含有八个槽位(slot),一个槽位可以放置一对键值对以及它的hash值。在桶的末尾含有一个overflow指针,指向它的溢出桶。
针对哈希冲突,采取的措施主要有两种:
-
拉链法:将多个命中到同一个桶的键值对,按照插入顺序依次存放在桶中。
-
开放寻址法:对于命中到同一个桶的多个键值对,采取向后寻找,知道找到空的桶再将值放入其中
我们来对比两种策略的优点:
显然,Go采取的是拉链法,桶数组中的每一个桶,严格来说应该是一个链表结构的桶数组,它通过overflow指针链接上了下一个溢出桶,使得多个键值对能存放在同一个桶中。若当前桶八个槽位都满了,就开辟一个新的溢出桶,放置在溢出桶里面。
1.4、数据结构定义
结构定义如下:
type hmap struct {count int // # live cells == size of map. Must be first (used by len() builtin)flags uint8B uint8 // log_2 of # of buckets (can hold up to loadFactor * 2^B items)noverflow uint16 // approximate number of overflow buckets; see incrnoverflow for detailshash0 uint32 // hash seedbuckets unsafe.Pointer // array of 2^B Buckets. may be nil if count==0.oldbuckets unsafe.Pointer // previous bucket array of half the size, non-nil only when growingnevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated)extra *mapextra // optional fields
}-
count:标识当前map的键值对数量 -
flags:标识当前map的状态 -
B:2^B为map目前的总桶数 -
noverflow:溢出桶数量 -
hash0:哈希因子 -
buckets:指向桶数组 -
oldbuckets:扩容时存储旧的桶数组 -
nevacuate:待完成数据迁移的桶下标 -
extra:存储预分配的溢出桶
mapextra的定义如下:
type mapextra struct {overflow *[]*bmapoldoverflow *[]*bmapnextOverflow *bmap
}-
overflow:指向新的预分配溢出桶数组 -
oldoverflow:指向旧的预分配溢出桶数组 -
nextoverflow:指向下一个可被使用的溢出桶
而bmap是一个桶的具体实现,源码如下:
type bmap struct {tophash [bucketCnt]uint8
}虽然在数据定义上,只含有一个tophash,但是在内存上,可以通过直接计算得出下一个槽的位置,以及overflow指针的位置。所以为了便于理解,它的实际结构如下:
type bmap struct {tophash [bucketCnt]uint8keys [bucketCnt]Tvalues [bucketCnt]Toverflow unsafe.Pointer
}接下来,让我们步入map的主干流程,了解它的机制实现。
2、主干流程
2.1、map的创建与初始化
//makemap为make(map[k]v,hint)实现Go映射创建
func makemap(t *maptype, hint int, h *hmap) *hmap {mem, overflow := math.MulUintptr(uintptr(hint), t.Bucket.Size_)if overflow || mem > maxAlloc {hint = 0}// initialize Hmapif h == nil {h = new(hmap)}h.hash0 = uint32(rand())// Find the size parameter B which will hold the requested # of elements.// For hint < 0 overLoadFactor returns false since hint < bucketCnt.B := uint8(0)for overLoadFactor(hint, B) {B++}h.B = B//若B==0,那么buckets将会采取懒创建的策略,会在未来要写map的方法mapassign中创建。if h.B != 0 {var nextOverflow *bmaph.buckets, nextOverflow = makeBucketArray(t, h.B, nil)if nextOverflow != nil {h.extra = new(mapextra)h.extra.nextOverflow = nextOverflow}}return h
}(1)makemap首先根据预分配的容量大小hint进行分配容量,若容量过大,则会置hint为0;
mem, overflow := math.MulUintptr(uintptr(hint), t.Bucket.Size_)if overflow || mem > maxAlloc {hint = 0}math.MulUintptr实现如下:
func MulUintptr(a, b uintptr) (uintptr, bool) {if a|b < 1<<(4*goarch.PtrSize) || a == 0 {return a * b, false}overflow := b > MaxUintptr/areturn a * b, overflow
}返回的两个值为:
-
计算二值的乘积
a*b -
乘积是否溢出
如果a|b的二进制表示,没有超过1<<(4*goarch.PtrSize),那么它们的乘积也不会溢出。在64位操作系统中,goarch.PtrSize的大小为8。否则,则通过a*b>MaxUintptr来判断,MaxUintptr为2^64-1.
(2)通过new方法,初始化hmap
// initialize Hmapif h == nil {h = new(hmap)}(3)通过rand()生成一个哈希因子
h.hash0 = uint32(rand())(4)获取哈希表的桶数量的对数B。(注意这里并不是直接计算log_2_hint,是要根据负载因子衡量桶的数量)
B := uint8(0)for overLoadFactor(hint, B) {B++}h.B = BGo中存在一个特别的参数即“负载因子”,它用于衡量哈希表的填充程度,负载因子越高,哈希表的空间利用率越高,但冲突的概率也会变大,性能可能下降。在Go中,该因子值为6.5。
func overLoadFactor(count int, B uint8) bool {return count > bucketCnt && uintptr(count) > loadFactorNum*(bucketShift(B)/loadFactorDen)
}在这里,bucketCnt为8。若count<=8,则直接返回false,只需要将键值对放在一个桶中即可。否则,计算当前的哈希表的容量*负载因子,若count的数量>这个值,将会扩容哈希表,即增大B。
假如count为60,那么B最终为4。
(5)若B!=0,初始化哈希表,使用makeBucketArray方法构造桶数组。
if h.B != 0 {var nextOverflow *bmaph.buckets, nextOverflow = makeBucketArray(t, h.B, nil)if nextOverflow != nil {h.extra = new(mapextra)h.extra.nextOverflow = nextOverflow}}如果map的容量过大,会提前申请一批溢出桶。
2.1.1、makeBucketArray方法
func makeBucketArray(t *maptype, b uint8, dirtyalloc unsafe.Pointer) (buckets unsafe.Pointer, nextOverflow *bmap) {//初始桶数量base := bucketShift(b)//最终桶数量,初始和base相同nbuckets := base//溢出桶预分配if b >= 4 {nbuckets += bucketShift(b - 4)//计算分配的总内存大小sz := t.Bucket.Size_ * nbuckets//将内存大小向上对齐到合适的大小,是内存分配的一个优化。up := roundupsize(sz, t.Bucket.PtrBytes == 0)if up != sz {//调整桶数量,使得内存被充分利用nbuckets = up / t.Bucket.Size_}}if dirtyalloc == nil {//分配nbuckets个桶buckets = newarray(t.Bucket, int(nbuckets))} else {//复用旧的内存buckets = dirtyallocsize := t.Bucket.Size_ * nbucketsif t.Bucket.PtrBytes != 0 {memclrHasPointers(buckets, size)} else {memclrNoHeapPointers(buckets, size)}}if base != nbuckets {//如果base和nbuckets的数量不同,说明预分配了溢出桶,需要设置溢出桶链表//指向第一个可用的预分配溢出桶,计算出溢出桶的起始位置nextOverflow = (*bmap)(add(buckets, base*uintptr(t.BucketSize)))//最后一个预分配的溢出桶的位置last := (*bmap)(add(buckets, (nbuckets-1)*uintptr(t.BucketSize)))//将最后一个溢出桶的指针设置为buckets,形成一个环形链表,用于后面的分配判断last.setoverflow(t, (*bmap)(buckets))}return buckets, nextOverflow
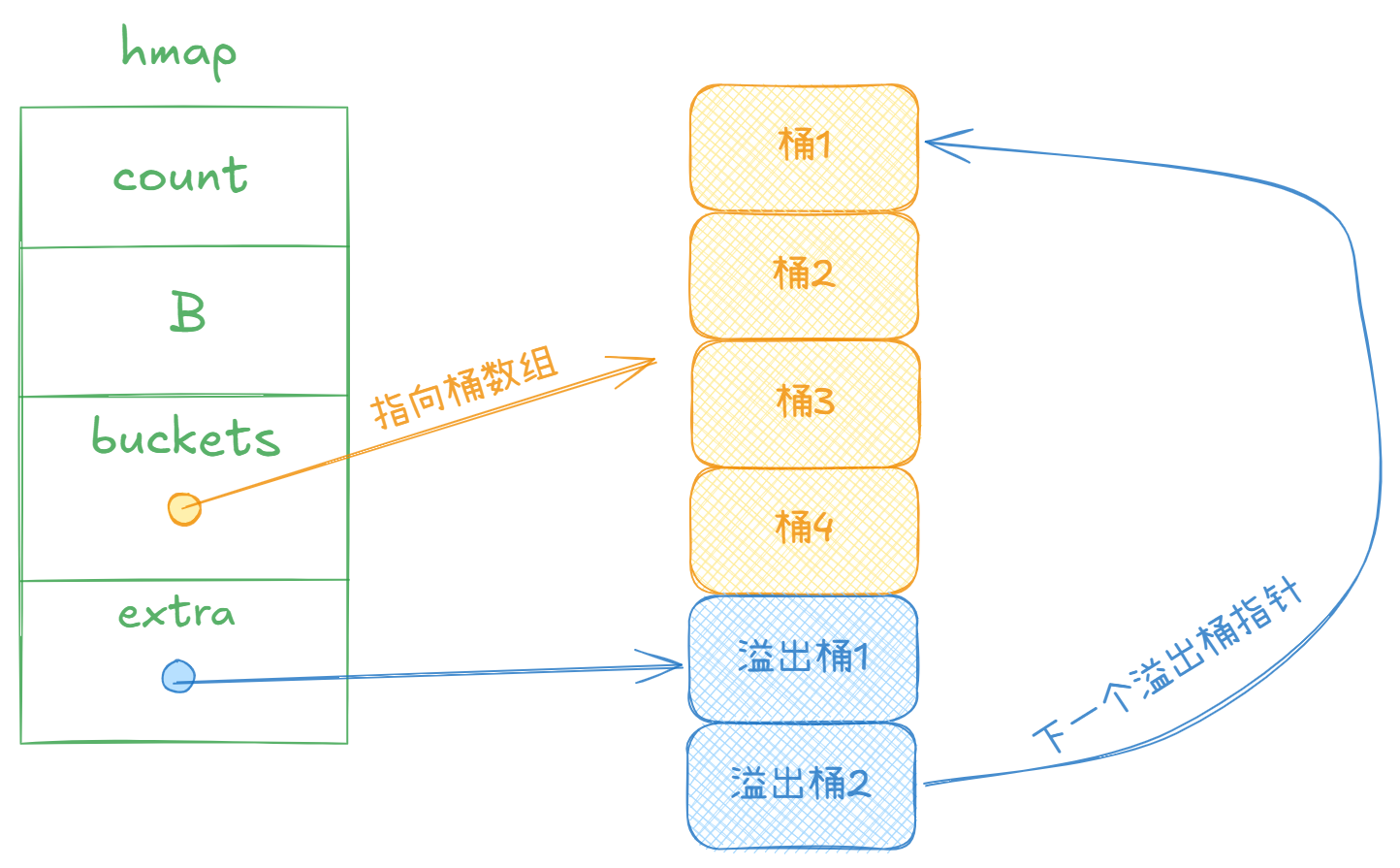
}makeBucketArray方法会根据初始的对数B来判断是否需要分配溢出桶。若B>=4,则需要预分配的溢出桶数量为2^(B-4)。确定好桶的总数后,会根据dirtyalloc是否为nil来判断是否需要新开辟空间。最后会返回指向桶数组的指针以及指向首个溢出桶位置的指针。
当最后返回到上层的makemap方法中,最终创造出的map结构如图:
2.2、map的读流程
2.2.1、读流程步骤总览
大致流程如下:
1、检查表是否为nil,或者表是否没有元素,若是则直接返回零值。
2、若处在并发写状态,则会导致程序崩溃(fatal)。
3、计算key对应的hash值,并且定位到对应的桶上。
4、若数据在旧桶,且数据没有迁移到新桶中,就在旧桶查找,否则在新桶中查找。
5、外层遍历桶数组的每个桶,内层遍历桶的每个kv对,找到了就返回value,否则返回零值
2.2.2、源码跟进mapaccess1
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {//...if h == nil || h.count == 0 {if err := mapKeyError(t, key); err != nil {panic(err) // see issue 23734}return unsafe.Pointer(&zeroVal[0])}if h.flags&hashWriting != 0 {fatal("concurrent map read and map write")}hash := t.Hasher(key, uintptr(h.hash0))m := bucketMask(h.B)b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.BucketSize)))if c := h.oldbuckets; c != nil {if !h.sameSizeGrow() {// There used to be half as many buckets; mask down one more power of two.m >>= 1}oldb := (*bmap)(add(c, (hash&m)*uintptr(t.BucketSize)))if !evacuated(oldb) {b = oldb}}top := tophash(hash)
bucketloop:for ; b != nil; b = b.overflow(t) {for i := uintptr(0); i < bucketCnt; i++ {if b.tophash[i] != top {if b.tophash[i] == emptyRest {break bucketloop}continue}k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))if t.IndirectKey() {k = *((*unsafe.Pointer)(k))}if t.Key.Equal(key, k) {e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))if t.IndirectElem() {e = *((*unsafe.Pointer)(e))}return e}}}return unsafe.Pointer(&zeroVal[0])
}(1)若哈希表为空,或不存在键值对,则会返回零值。在此之前,会检查key是否合法,非法会触发panic。
if h == nil || h.count == 0 {if err := mapKeyError(t, key); err != nil {panic(err) // see issue 23734}return unsafe.Pointer(&zeroVal[0])}(2)若存在并发写map,会立刻报错,使得程序停止运行。flags的第3个bit位标识map是否处于并发写状态。
hashWriting = 4 // a goroutine is writing to the map 4->100
if h.flags&hashWriting != 0 {fatal("concurrent map read and map write")}(3)计算key的hash值,并且对桶数量取模,定位到具体的桶。取模运算为x & (mod-1),只有mod为2的幂时可以加速。
hash := t.Hasher(key, uintptr(h.hash0))m := bucketMask(h.B)b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.BucketSize)))(4)检查是否存在旧桶,存在旧桶且数据未搬迁完成则去旧桶中找key,否则在新桶找。
if c := h.oldbuckets; c != nil { //c!=nil,说明旧桶未完成迁移(rehash)if !h.sameSizeGrow() { //是否是等量扩容//如果不是等量扩容,调整 hash 掩码(mask)m >>= 1}oldb := (*bmap)(add(c, (hash&m)*uintptr(t.BucketSize)))//计算旧桶地址if !evacuated(oldb) { //检查旧桶是否已搬迁b = oldb //未搬迁则数据有效}}在取旧桶的时候,会根据evacuated判断数据是否已经迁移到新的桶:判断方法是取桶首个元素的tophash值,若值为2,3,4中的一个,代表数据已经迁移完成。
const emptyOne = 1
const evacuatedX = 2
const evacuatedY = 3
const evacuatedEmpty = 4
const minTopHash = 5
func evacuated(b *bmap) bool {h := b.tophash[0]return h > emptyOne && h < minTopHash
}(5)取key的hash值的高8位值top,若值<5则累加5,避开0~4,这些值会用于枚举,存在一些特殊的含义。
top := tophash(hash)func tophash(hash uintptr) uint8 {top := uint8(hash >> (goarch.PtrSize*8 - 8))if top < minTopHash {top += minTopHash}return top
}(6)外层b遍历每一个桶,内层遍历b中的每一个kv对,对比每一个kv对的tophash值是否和要查询的key的top值是否相同进行查找。
for ; b != nil; b = b.overflow(t) {for i := uintptr(0); i < bucketCnt; i++ {//...}}若两个hash值不同,并且桶中的当前键值对的tophash为0,表示后续没有元素,直接退出循环返回零值。否则检查下一个kv。
if b.tophash[i] != top {if b.tophash[i] == emptyRest {break bucketloop}continue}若找到了,就根据内存偏移找到对应的value并且返回。注意:会调用key.Equal方法具体检查要读的key和当前key是否一样,避免因为哈希冲突导致读取了错误的value。
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))if t.IndirectKey() {k = *((*unsafe.Pointer)(k))}if t.Key.Equal(key, k) {e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))if t.IndirectElem() {e = *((*unsafe.Pointer)(e))}return e}否则最终返回0值。
return unsafe.Pointer(&zeroVal[0])2.3、map的写流程
2.3.1、写流程步骤总览
大致流程如下:
-
1、若表为nil,则panic,若处在并发写,则fatal
-
2、获取key的hash值,用于校验是否已经存在,需要覆盖
-
3、设置处于写状态
-
4、懒创建buckets,若B==0,则buckets会在第一次写的时候创建
-
5、根据hash定位到具体的bucket中,若表处在扩容阶段则调用
growWork辅助扩容;创建三个拟插入位置指针,分别存储要插入的tophash、key、value的位置。(作用是若遇见空位置,就存储,然后要继续看是否存在相同的key要覆盖。) -
6、遍历该桶的每一个kv,会遇到两种情况:
若当前槽位的tophash和要插入的键值对的tophash不相同,那么检查是否是空槽,是则更新拟存储指针;若当前槽位是空槽,会继续检查对后面是否存在kv的标识,若后面全是空槽了,就可以直接退出了不必继续遍历。
若相同,那就直接进行覆盖操作,更新完成直接到第10步进行收尾。
-
7、如果我们没有找到要插入的位置,或者要插入的位置是当前桶的最后一个槽位,检查以下条件决定是否进行扩容:
Count+1 > loadfactor * 2^h.B,即总键值对 > 负载因子*总桶数h.noverflow > threshold:如果 溢出桶过多,说明冲突严重,也要扩容。发生扩容后,刚刚的记录就无效了,重新到第5步。
-
8、若不扩容,且没有插入的位置(没有空槽,也没有覆盖),就新创建一个新桶,连接到当前桶的后面作为溢出桶,插入到新桶的第一个位置上。这个新桶可以是新分配的,也可以是一开始创建表就预分配的(优先)。
-
9、对拟插入的位置进行实际的插入
-
10、收尾,再次检查是否处在并发写状态,是则fatal,否则重置写状态标识,然后退出。
2.3.2、源码跟进mapassign
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {if h == nil {panic(plainError("assignment to entry in nil map"))}//...if h.flags&hashWriting != 0 {fatal("concurrent map writes")}hash := t.Hasher(key, uintptr(h.hash0))// Set hashWriting after calling t.hasher, since t.hasher may panic,// in which case we have not actually done a write.h.flags ^= hashWritingif h.buckets == nil {h.buckets = newobject(t.Bucket) // newarray(t.Bucket, 1)}again:bucket := hash & bucketMask(h.B)if h.growing() {growWork(t, h, bucket)}b := (*bmap)(add(h.buckets, bucket*uintptr(t.BucketSize)))top := tophash(hash)var inserti *uint8var insertk unsafe.Pointervar elem unsafe.Pointer
bucketloop:for {for i := uintptr(0); i < bucketCnt; i++ {if b.tophash[i] != top {if isEmpty(b.tophash[i]) && inserti == nil {inserti = &b.tophash[i]insertk = add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))}if b.tophash[i] == emptyRest {break bucketloop}continue}k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))if t.IndirectKey() {k = *((*unsafe.Pointer)(k))}if !t.Key.Equal(key, k) {continue}// already have a mapping for key. Update it.if t.NeedKeyUpdate() {typedmemmove(t.Key, k, key)}elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))goto done}ovf := b.overflow(t)if ovf == nil {break}b = ovf}// Did not find mapping for key. Allocate new cell & add entry.// If we hit the max load factor or we have too many overflow buckets,// and we're not already in the middle of growing, start growing.if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {hashGrow(t, h)goto again // Growing the table invalidates everything, so try again}if inserti == nil {// The current bucket and all the overflow buckets connected to it are full, allocate a new one.newb := h.newoverflow(t, b)inserti = &newb.tophash[0]insertk = add(unsafe.Pointer(newb), dataOffset)elem = add(insertk, bucketCnt*uintptr(t.KeySize))}// store new key/elem at insert positionif t.IndirectKey() {kmem := newobject(t.Key)*(*unsafe.Pointer)(insertk) = kmeminsertk = kmem}if t.IndirectElem() {vmem := newobject(t.Elem)*(*unsafe.Pointer)(elem) = vmem}typedmemmove(t.Key, insertk, key)*inserti = toph.count++done:if h.flags&hashWriting == 0 {fatal("concurrent map writes")}h.flags &^= hashWritingif t.IndirectElem() {elem = *((*unsafe.Pointer)(elem))}return elem
}(1)错误处理:map为空则panic,并发写则出发fatal。
if h == nil {panic(plainError("assignment to entry in nil map"))}//...if h.flags&hashWriting != 0 {fatal("concurrent map writes")}hash := t.Hasher(key, uintptr(h.hash0))(2)标识map处在写的状态,并且懒创建桶。
h.flags ^= hashWritingif h.buckets == nil {h.buckets = newobject(t.Bucket) // newarray(t.Bucket, 1)}(3)获取当前key对应的桶的桶索引
bucket := hash & bucketMask(h.B)(4)若发现当前map处在扩容状态,则帮助其渐进扩容。具体在下文中提及。
if h.growing() {growWork(t, h, bucket)}(5)进行地址偏移,定位到具体的桶b
b := (*bmap)(add(h.buckets, bucket*uintptr(t.BucketSize)))(6)计算tophash
top := tophash(hash)(7)提前声明三个指针,用于指向存放kv对槽位
var inserti *uint8 //tophash拟插入位置
var insertk unsafe.Pointer //key拟插入位置
var elem unsafe.Pointer //value拟插入位置(8)开启循环,和读流程类似,外层遍历桶,内层遍历桶的每个位置。
for {for i := uintptr(0); i < bucketCnt; i++ {//...}b = ovf}(9)若key的tophash和当前槽位的tophash不相同,则进行以下的检查:
-
若该槽位是空的,那么就将kv拟插入在这个位置(先记录),因为可能存在相同的key在后面的桶中。
-
若槽位当前位置
tophash标识为emptyRest(0),则标识从当前槽位开始往后的槽位都是空的,就不用继续遍历了,直接退出bucketloop。(说明可以插入在此位置了)
if b.tophash[i] != top {if isEmpty(b.tophash[i]) && inserti == nil {inserti = &b.tophash[i]insertk = add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))}if b.tophash[i] == emptyRest {break bucketloop}continue}(10)否则说明找到了相同的key,需要进行覆盖操作。更新完成后跳到done,执行收尾流程。注意:会调用key.Equal方法具体检查要写的key和当前key是否一样,避免因为哈希冲突导致原来不同的kv对被错误的覆盖。
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))if t.IndirectKey() {k = *((*unsafe.Pointer)(k))}if !t.Key.Equal(key, k) {continue}// already have a mapping for key. Update it.if t.NeedKeyUpdate() {typedmemmove(t.Key, k, key)}elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))goto done(11)倘若没有相同的key,也没有剩余的空间了,则会考虑执行扩容模式,完成后再回到agian的位置重新桶定位以及遍历流程。
// 如果达到负载因子上限,或者溢出桶过多,则扩容
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {hashGrow(t, h)goto again // Growing the table invalidates everything, so try again}触发扩容的条件:
-
h.count+1 > loadFactor * 2^h.B:如果当前map达到负载因子上限,需要扩容。 -
h.noverflow > threshold:如果 溢出桶过多,说明冲突严重,也要扩容。 -
h.growing():检查是否 已经在扩容,如果已经在扩容,就不会触发新的扩容。
(12)若不执行扩容操作,也没有找到插入的位置,则新创建一个溢出桶,将kv拟插入在溢出桶的第一个位置。
if inserti == nil {// The current bucket and all the overflow buckets connected to it are full, allocate a new one.newb := h.newoverflow(t, b)inserti = &newb.tophash[0]insertk = add(unsafe.Pointer(newb), dataOffset)elem = add(insertk, bucketCnt*uintptr(t.KeySize))}创建新桶操作如下:
func (h *hmap) newoverflow(t *maptype, b *bmap) *bmap {var ovf *bmap//若表存在预分配溢出桶,则直接使用预分配的溢出桶。if h.extra != nil && h.extra.nextOverflow != nil {if ovf.overflow(t) == nil {// 不是最后一个预分配的溢出桶,直接移动 `nextOverflow` 指针h.extra.nextOverflow = (*bmap)(add(unsafe.Pointer(ovf), uintptr(t.BucketSize)))} else {// 这是最后一个预分配的溢出桶,重置 overflow 指针ovf.setoverflow(t, nil)h.extra.nextOverflow = nil}} else {//创建一个新的溢出桶ovf = (*bmap)(newobject(t.Bucket))}//更新 h.noverflow 计数,跟踪 map 目前有多少个溢出桶。h.incrnoverflow()if t.Bucket.PtrBytes == 0 { //如果map只存储基本数据类型h.createOverflow() //创建overflow记录表*h.extra.overflow = append(*h.extra.overflow, ovf) //记录新的溢出桶}b.setoverflow(t, ovf) //把ovf连接到b这个桶的overflow指针return ovf
}这里存在一个十分容易混淆的点:请注意,在最开始的makeBucketArray方法中,我们提及到了只有最后一个溢出桶它才设置了overflow指针,对于前面的溢出桶,overflow指针是nil,所以可以根据这个特性来判断当前的溢出桶是不是最后一个溢出桶。
用图来表示,每个桶经过了多次溢出桶扩展后的表状态,如下:
(13)在拟插入位置实际插入kv
// store new key/elem at insert position
if t.IndirectKey() {kmem := newobject(t.Key)*(*unsafe.Pointer)(insertk) = kmeminsertk = kmem
}
if t.IndirectElem() {vmem := newobject(t.Elem)*(*unsafe.Pointer)(elem) = vmem
}
typedmemmove(t.Key, insertk, key)
*inserti = top
h.count++(14)收尾流程,再次校验是否处在并发写,有则抛出fatal,否则将标记重置,然后退出。
done:if h.flags&hashWriting == 0 {fatal("concurrent map writes")}h.flags &^= hashWritingif t.IndirectElem() {elem = *((*unsafe.Pointer)(elem))}return elem2.4、map的删流程
2.4.1、删流程步骤总览
删流程步骤大致如下:
-
1、若表为nil或者不存在元素,则直接返回;若处在并发写则fatal
-
2、获取key的哈希因子,根据哈希值找到对应的桶
-
3、若表处在扩容阶段,则利用
growWork辅助扩容 -
4、开始遍历查找要删除的元素,若没找到则直接退出查找流程,找到了则将值清为0值
-
5、若表的结构如:「值1——空——空——空——删除值——后全空——后全空」的结构,则需要向前回溯,将值1后的所有
slot都置为emptyRest状态。 -
6、若删除后,表的count为0,则更新hash因子,避免哈希碰撞攻击。
-
7、再次校验是否处在并发写,处在将fatal,否则重置写标识
2.4.2、源码跟进mapdelete
func mapdelete(t *maptype, h *hmap, key unsafe.Pointer) {//...if h == nil || h.count == 0 {if err := mapKeyError(t, key); err != nil {panic(err) // see issue 23734}return}if h.flags&hashWriting != 0 {fatal("concurrent map writes")}hash := t.Hasher(key, uintptr(h.hash0))// Set hashWriting after calling t.hasher, since t.hasher may panic,// in which case we have not actually done a write (delete).h.flags ^= hashWritingbucket := hash & bucketMask(h.B)if h.growing() {growWork(t, h, bucket)}b := (*bmap)(add(h.buckets, bucket*uintptr(t.BucketSize)))bOrig := btop := tophash(hash)
search:for ; b != nil; b = b.overflow(t) {for i := uintptr(0); i < bucketCnt; i++ {if b.tophash[i] != top {if b.tophash[i] == emptyRest {break search}continue}k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))k2 := kif t.IndirectKey() {k2 = *((*unsafe.Pointer)(k2))}if !t.Key.Equal(key, k2) {continue}// Only clear key if there are pointers in it.if t.IndirectKey() {*(*unsafe.Pointer)(k) = nil} else if t.Key.PtrBytes != 0 {memclrHasPointers(k, t.Key.Size_)}e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))if t.IndirectElem() {*(*unsafe.Pointer)(e) = nil} else if t.Elem.PtrBytes != 0 {memclrHasPointers(e, t.Elem.Size_)} else {memclrNoHeapPointers(e, t.Elem.Size_)}b.tophash[i] = emptyOne// If the bucket now ends in a bunch of emptyOne states,// change those to emptyRest states.// It would be nice to make this a separate function, but// for loops are not currently inlineable.if i == bucketCnt-1 {if b.overflow(t) != nil && b.overflow(t).tophash[0] != emptyRest {goto notLast}} else {if b.tophash[i+1] != emptyRest {goto notLast}}for {b.tophash[i] = emptyRestif i == 0 {if b == bOrig {break // beginning of initial bucket, we're done.}// Find previous bucket, continue at its last entry.c := bfor b = bOrig; b.overflow(t) != c; b = b.overflow(t) {}i = bucketCnt - 1} else {i--}if b.tophash[i] != emptyOne {break}}notLast:h.count--// Reset the hash seed to make it more difficult for attackers to// repeatedly trigger hash collisions. See issue 25237.if h.count == 0 {h.hash0 = uint32(rand())}break search}}if h.flags&hashWriting == 0 {fatal("concurrent map writes")}h.flags &^= hashWriting
}(1)错误处理:当表为nil或者不存在元素,则直接返回;若处在并发写状态则fatal
if h == nil || h.count == 0 {if err := mapKeyError(t, key); err != nil {panic(err) // see issue 23734}return}if h.flags&hashWriting != 0 {fatal("concurrent map writes")}(2)获取key的hash,并且标识表为写状态
hash := t.Hasher(key, uintptr(h.hash0))// Set hashWriting after calling t.hasher, since t.hasher may panic,// in which case we have not actually done a write (delete).h.flags ^= hashWriting(3)若表正在扩容,则调用growWork辅助扩容。通过hash值映射到对应的桶b。
bucket := hash & bucketMask(h.B)if h.growing() {growWork(t, h, bucket)}b := (*bmap)(add(h.buckets, bucket*uintptr(t.BucketSize)))bOrig := btop := tophash(hash)(4)进入桶的遍历,外层遍历桶,内层遍历每个kv对
for ; b != nil; b = b.overflow(t) {for i := uintptr(0); i < bucketCnt; i++ {//...}}(5)若当前槽位的tophash和需要查找的不相同,则检查后面是否还有元素;有元素就继续进行查找,没有就直接退出,表示想删除的元素不存在。
if b.tophash[i] != top {if b.tophash[i] == emptyRest {break search}continue}(6)否则,说明找到了对应的key,进行删除操作,具体包括了:
-
查找
key并找到存储位置 -
清除
key和value(包括直接清零或nil指针)。 -
更新
tophash,标记该槽位为空(EmptyOne)。
注意:会调用key.Equal方法具体检查要删除的key和当前key是否一样,避免因为哈希冲突导致原来不同的kv对被错误的删除。
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))k2 := kif t.IndirectKey() {k2 = *((*unsafe.Pointer)(k2))}if !t.Key.Equal(key, k2) {continue}// Only clear key if there are pointers in it.if t.IndirectKey() {*(*unsafe.Pointer)(k) = nil} else if t.Key.PtrBytes != 0 {memclrHasPointers(k, t.Key.Size_)}e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))if t.IndirectElem() {*(*unsafe.Pointer)(e) = nil} else if t.Elem.PtrBytes != 0 {memclrHasPointers(e, t.Elem.Size_)} else {memclrNoHeapPointers(e, t.Elem.Size_)}b.tophash[i] = emptyOne(7)检查当前删除的桶的元素是否是桶的最后一个元素:
-
若是,若该桶的后面还存在溢出桶,并且溢出桶非空则跳过清理环节,进入收尾阶段
-
若不是,检查后面是否还有元素,有元素也跳过清理环节。(通过检查下一个
slot的标识是否为emptyRest)
if i == bucketCnt-1 {if b.overflow(t) != nil && b.overflow(t).tophash[0] != emptyRest {goto notLast}
} else {if b.tophash[i+1] != emptyRest {goto notLast}
}否则,说明后面没有更多的元素了,需要向前回溯,将最后一个元素的槽位后面的所有槽位都设置为emptyRest状态,优化未来的流程。
回溯流程:
-
先将当前桶从当前的删除元素一个个往前走,遇到是
emptyOne的就修改为emptyRest -
当到达第一个元素并且也为空时,回溯到上一个桶的末尾,重复流程
-
遇到非空元素,完成所有回溯并且退出。
for {b.tophash[i] = emptyRestif i == 0 {if b == bOrig {break // beginning of initial bucket, we're done.}// Find previous bucket, continue at its last entry.c := bfor b = bOrig; b.overflow(t) != c; b = b.overflow(t) {}i = bucketCnt - 1} else {i--}if b.tophash[i] != emptyOne {break}}(8)收尾流程,将map的元素计数器count-1,若count为0,则更新哈希因子。
notLast:h.count--// Reset the hash seed to make it more difficult for attackers to// repeatedly trigger hash collisions. See issue 25237.if h.count == 0 {h.hash0 = uint32(rand())}break search}为什么要更新哈希因子?
让攻击者无法利用相同的哈希因子
h.hash0构造出一组导致严重哈希碰撞的key,从而保护map免受拒绝服务(DoS)攻击。
(9)最后的校验是否处在并发写状态,是则fatal,然后再更新状态标识
if h.flags&hashWriting == 0 {fatal("concurrent map writes")}h.flags &^= hashWriting3、扩容机制
3.1、扩容类型
Gomap的扩容方式分为两种:
-
等量扩容(Same-Size-Grow):如果
map的溢出桶过多,导致查找性能下降,说明KV分布不均匀,此时就会触发等量扩容,哈希表的桶数不会改变,但会重新分配K-V对的位置,目的是减少溢出桶的数量,增加KV的密度,让数据能平均分布。 -
增量扩容(Double-Size-Grow):如果负载因子超标「count/2^B > loadFactor」,即KV对的数目超过了一定上限,就会触发增量扩容,使得Buckets数量翻倍,让所有的KV对重新分配在新的桶数组中,目的是减少K-V对的密度,降低每个桶的KV数量,优化查询时间。
为什么说等量扩容是增加密度呢?
我们想,既然count是合理的,但是当前map导致了溢出桶过多,那么只可能是经过了多次删除操作,导致出现了很多空位,例如「A——空——空——空——B」,这样子每次查找就很耗时了,于是等量扩容需要重新分配KV对的位置变为「A——B」,让数据更加紧凑。
3.2、扩容触发
在之前的写流程中,提及到以下代码会触发map的扩容:
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {hashGrow(t, h)goto again // Growing the table invalidates everything, so try again
}只有当map不处在扩容中,并且满足以下两个条件之一,触发扩容:
-
负载因子超标:当KV对的数目超过桶的数目,并且「KV对数目/桶数 > 负载因子」时,发生扩容
overLoadFactor(h.count+1, h.B)
func overLoadFactor(count int, B uint8) bool {return count > bucketCnt && uintptr(count) > loadFactorNum*(bucketShift(B)/loadFactorDen)
}-
溢出桶过多:当溢出桶数量>桶数组的数量(B最大取15),则发生扩容
func tooManyOverflowBuckets(noverflow uint16, B uint8) bool {if B > 15 {B = 15}return noverflow >= uint16(1)<<(B&15)
}3.3、扩容流程前置
进入hashGrow方法,观察扩容流程
func hashGrow(t *maptype, h *hmap) {bigger := uint8(1)if !overLoadFactor(h.count+1, h.B) {bigger = 0h.flags |= sameSizeGrow}oldbuckets := h.bucketsnewbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)flags := h.flags &^ (iterator | oldIterator)if h.flags&iterator != 0 {flags |= oldIterator}// commit the grow (atomic wrt gc)h.B += biggerh.flags = flagsh.oldbuckets = oldbucketsh.buckets = newbucketsh.nevacuate = 0h.noverflow = 0if h.extra != nil && h.extra.overflow != nil {// Promote current overflow buckets to the old generation.if h.extra.oldoverflow != nil {throw("oldoverflow is not nil")}h.extra.oldoverflow = h.extra.overflowh.extra.overflow = nil}if nextOverflow != nil {if h.extra == nil {h.extra = new(mapextra)}h.extra.nextOverflow = nextOverflow}(1)标识是否为等量扩容,若是等量扩容bigger置0,否则将map的flag的二进制第4位置1标识处在等量扩容阶段。
bigger := uint8(1)if !overLoadFactor(h.count+1, h.B) {bigger = 0h.flags |= sameSizeGrow}(2)不论如何,发生扩容,那么当前的桶数组就会变成旧的桶数组了,于是将map的oldbuckets指针指向它,然后创建一个新的桶数组。
oldbuckets := h.bucketsnewbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)(3)更新一些map的标识,包括:
-
处于
range的iterator标识,若处在遍历中,则需要标识olditerator -
新map的桶数、完成数据迁移的桶数、溢出桶的桶数等
flags := h.flags &^ (iterator | oldIterator)if h.flags&iterator != 0 {flags |= oldIterator}// commit the grow (atomic wrt gc)h.B += biggerh.flags = flagsh.oldbuckets = oldbucketsh.buckets = newbucketsh.nevacuate = 0h.noverflow = 0(4)将原本的可用预分配溢出桶赋值给h.extra.oldoverflow,将新分配的桶数组的新预分配溢出桶赋值给h.extra.nextOverflow
if h.extra != nil && h.extra.overflow != nil {// Promote current overflow buckets to the old generation.if h.extra.oldoverflow != nil {throw("oldoverflow is not nil")}h.extra.oldoverflow = h.extra.overflowh.extra.overflow = nil}if nextOverflow != nil {if h.extra == nil {h.extra = new(mapextra)}h.extra.nextOverflow = nextOverflow}最后根据注释,我们知道Go的map扩容实际流程会通过growWork和evacuate方法渐进式地完成。
// the actual copying of the hash table data is done incrementally
// by growWork() and evacuate().3.4、渐进式扩容、源码实现
Go对map的扩容策略采取的是渐进式扩容(Incrementally Grow),避免一次将所有旧数据迁移至新map引发性能抖动。
迁移规则如下:
-
若是等量扩容,那么新桶数组的长度与旧桶数组长度一致,让数据更加紧凑,从而减少溢出链长度
-
若是等量扩容,旧桶的数据迁移到的新桶中,它们桶的下标在桶数组中是一致的。例如旧桶0—迁移至—>新桶0
-
若是增量扩容,会根据旧数据KV对的hash值,来判断是否要进行桶的偏移。
-
因为一个KV对,要通过hash值来映射到对应的桶中,当桶的数量翻倍之后,对应的对数指标B也会加一,因此取模映射会发生改变。例如,一个KV对的hash值原本是111,原本桶的数量为4,那么B=2,取模运算为:「111 & (1<<2 - 1) = 111 & 11 = 11 = 3」,所以这个KV对会被存放在桶3中。当发生了增量扩容后,B增一为3,此时对于同一个hash值,它的取模变成了:「111 & (1<<3 - 1) = 111 & 111 = 111 = 7」,偏移了4个桶。对于增量扩容的转移,就是通过这个方式来判断旧的KV对应该被放在新的哪一个桶中,假如它原本在第i个桶,原本含有j个桶,那么迁移后它只可能在第i个桶或者第i+j个桶中。
当每次触发写、删操作的时候,会为处于map的两组桶的数据完成迁移:
-
一组是当前写、删操作所命中的桶
-
一组是未迁移的桶中,索引最小的那个桶
func growWork(t *maptype, h *hmap, bucket uintptr) {//迁移当前正在使用的桶evacuate(t, h, bucket&h.oldbucketmask())//迁移未迁移的桶中,索引最小的桶if h.growing() {evacuate(t, h, h.nevacuate)}
}步入evacuate函数:
func evacuate(t *maptype, h *hmap, oldbucket uintptr) {//oldbcuket为要迁移的旧桶在旧桶数组中的索引//获取这一个旧桶bb := (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.BucketSize)))//获取旧桶数组的桶数,根据2^oldB计算newbit := h.noldbuckets()//判断此桶b是否已经完成了数据的迁移,未完成则步入函数内部if !evacuated(b) {//xy[2]数组用于存储迁移目标bucket//xy[0],记录的是等量扩容迁移的目标桶,代表新桶数组中索引和旧桶一致的那个桶//xy[1],记录的是增量扩容迁移的目标桶,索引为原索引加上旧桶容量的桶var xy [2]evacDstx := &xy[0]x.b = (*bmap)(add(h.buckets, oldbucket*uintptr(t.BucketSize)))x.k = add(unsafe.Pointer(x.b), dataOffset)x.e = add(x.k, bucketCnt*uintptr(t.KeySize))if !h.sameSizeGrow() {//若是增量扩容,则记录xy[1]y := &xy[1]//例如旧桶数组有4个桶,那么旧桶i映射到新桶i+4y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.BucketSize)))y.k = add(unsafe.Pointer(y.b), dataOffset)y.e = add(y.k, bucketCnt*uintptr(t.KeySize))}//开始遍历旧桶b的所有键值对for ; b != nil; b = b.overflow(t) {k := add(unsafe.Pointer(b), dataOffset)e := add(k, bucketCnt*uintptr(t.KeySize))//遍历每一个键值对for i := 0; i < bucketCnt; i, k, e = i+1, add(k, uintptr(t.KeySize)), add(e, uintptr(t.ValueSize)) {//获取当前slot的tophashtop := b.tophash[i]if isEmpty(top) {//若槽位为空,标识以完成迁移b.tophash[i] = evacuatedEmptycontinue}if top < minTopHash {throw("bad map state")}k2 := k//处理键为指针的情况if t.IndirectKey() {k2 = *((*unsafe.Pointer)(k2))}var useY uint8if !h.sameSizeGrow() {//对于增量扩容的迁移策略//计算key的hash值hash := t.Hasher(k2, uintptr(h.hash0))//若map处于迭代过程需要特殊处理if h.flags&iterator != 0 && !t.ReflexiveKey() && !t.Key.Equal(k2, k2) {//useY决定是否要迁移到新桶中useY = top & 1top = tophash(hash)} else {//普通key的迁移判断if hash&newbit != 0 {//说明hash的B位是1,key要被迁移到新桶中下标为Y的桶。//这里举个例子,假如旧桶有4个,那么B是2,那么newbit就是1<<B=100,若hash的第B位也是1,那就决定要用y的坐标,所以会迁移到桶8useY = 1}}}b.tophash[i] = evacuatedX + useY // evacuatedX + 1 == evacuatedYdst := &xy[useY] // evacuation destination//若到了桶的最后一个slot,完成后跳转到溢出桶if dst.i == bucketCnt {dst.b = h.newoverflow(t, dst.b)dst.i = 0dst.k = add(unsafe.Pointer(dst.b), dataOffset)dst.e = add(dst.k, bucketCnt*uintptr(t.KeySize))}//完成K-V对的迁移,更新几个目标指针dst.b.tophash[dst.i&(bucketCnt-1)] = top // mask dst.i as an optimization, to avoid a bounds checkif t.IndirectKey() {*(*unsafe.Pointer)(dst.k) = k2 // copy pointer} else {typedmemmove(t.Key, dst.k, k) // copy elem}if t.IndirectElem() {*(*unsafe.Pointer)(dst.e) = *(*unsafe.Pointer)(e)} else {typedmemmove(t.Elem, dst.e, e)}dst.i++dst.k = add(dst.k, uintptr(t.KeySize))dst.e = add(dst.e, uintptr(t.ValueSize))}}//若旧桶完成了迁移,并且没有处于迭代中并且含有指针类型的值,需要手动帮助GC清理掉旧桶。if h.flags&oldIterator == 0 && t.Bucket.PtrBytes != 0 {b := add(h.oldbuckets, oldbucket*uintptr(t.BucketSize))// Preserve b.tophash because the evacuation// state is maintained there.ptr := add(b, dataOffset)n := uintptr(t.BucketSize) - dataOffsetmemclrHasPointers(ptr, n)}}//若当前迁移的旧桶是未迁移的旧桶中索引最小的,那么将h.nevacuate累加1.若旧桶全部被迁移完毕,会将等量扩容标识置为0if oldbucket == h.nevacuate {advanceEvacuationMark(h, t, newbit)}
}
func advanceEvacuationMark(h *hmap, t *maptype, newbit uintptr) {h.nevacuate++//...if h.nevacuate == newbit { //完成所有迁移,工作结束h.oldbuckets = nilif h.extra != nil {h.extra.oldoverflow = nil}h.flags &^= sameSizeGrow}
}可以阅读上述代码注释来学习它的迁移过程。
4、map的遍历流程
4.1、主要数据结构
我们知道,可以通过for range的方式来遍历map的每一个kv对,它主要是通过底层的hiter——Hash Iterator数据结构实现的。
在runtime/map.go中,可以找到对迭代器结构的定义:
type hiter struct {key unsafe.Pointer // 当前遍历的 key 指针elem unsafe.Pointer // 当前遍历的 value 指针t *maptype // 关联的 map 类型信息h *hmap // 指向被遍历的 map 结构buckets unsafe.Pointer // 迭代开始时的 buckets 数组指针(用于保证遍历稳定)bptr *bmap // 当前遍历的 bucket 指针overflow *[]*bmap // 存储当前 hmap.buckets 可能存在的溢出桶,防止 GC 误清理oldoverflow *[]*bmap // 存储旧 hmap.oldbuckets 可能存在的溢出桶,防止 GC 误清理startBucket uintptr // 迭代开始的 bucket 位置(用于随机化遍历起点)offset uint8 // 在 bucket 内的随机偏移量(防止总是从 slot 0 开始,增强安全性)wrapped bool // 是否已经遍历完所有 bucket 并回绕到起始位置B uint8 // 当前 map 的 B 值(`2^B` 代表 bucket 数量)i uint8 // 当前 bucket 内的 key-value 索引(用于迭代 bucket 内部的槽位)bucket uintptr // 当前遍历到的 bucket 索引(相对 `buckets` 起始位置)checkBucket uintptr // 用于 double-checking bucket 迭代的一致性,避免 map 变化影响遍历
}字段详细说明:

4.2、遍历主流程
Go对map的遍历起点是随机的,它防止每次遍历都从slot 0开始,增强了一定的安全性,这也是为什么你使用for range去遍历map的时候,不能保证每次一次遍历都结果都是相同的。
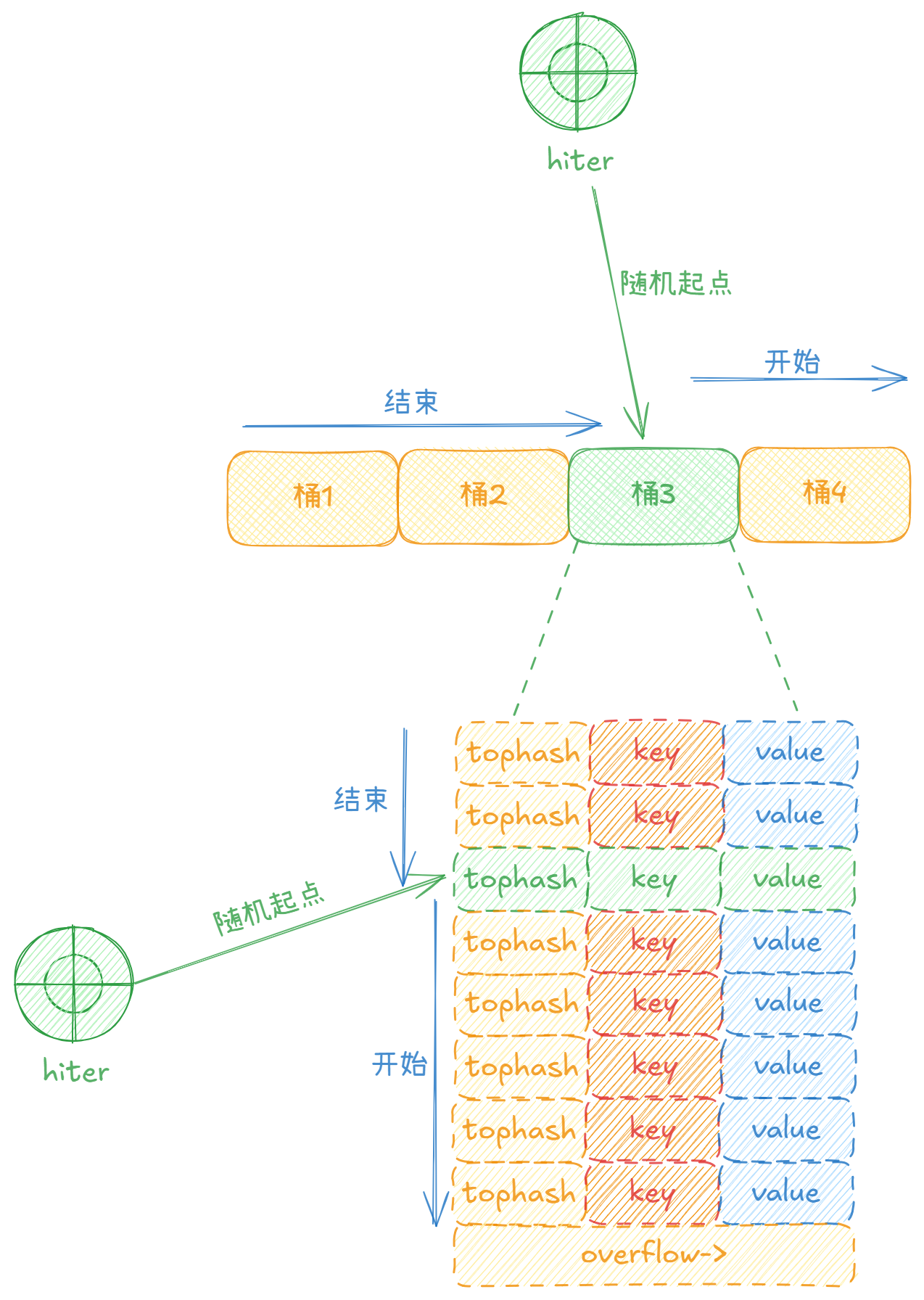
4.3、mapiterinit初始化迭代器
让我们进入mapiterinit流程,观察它的具体实现。
func mapiterinit(t *maptype, h *hmap, it *hiter) {//...it.t = tif h == nil || h.count == 0 {return}if unsafe.Sizeof(hiter{})/goarch.PtrSize != 12 {throw("hash_iter size incorrect") // see cmd/compile/internal/reflectdata/reflect.go}it.h = h// grab snapshot of bucket stateit.B = h.Bit.buckets = h.bucketsif t.Bucket.PtrBytes == 0 {h.createOverflow()it.overflow = h.extra.overflowit.oldoverflow = h.extra.oldoverflow}// decide where to startr := uintptr(rand())it.startBucket = r & bucketMask(h.B)it.offset = uint8(r >> h.B & (bucketCnt - 1))// iterator stateit.bucket = it.startBucket// Remember we have an iterator.// Can run concurrently with another mapiterinit().if old := h.flags; old&(iterator|oldIterator) != iterator|oldIterator {atomic.Or8(&h.flags, iterator|oldIterator)}mapiternext(it)
}(1)若表为nil或者没有元素,则直接返回;记录一些初始参数
it.t = tif h == nil || h.count == 0 {return}if unsafe.Sizeof(hiter{})/goarch.PtrSize != 12 {throw("hash_iter size incorrect") // see cmd/compile/internal/reflectdata/reflect.go}it.h = h// grab snapshot of bucket stateit.B = h.Bit.buckets = h.buckets(2)若表的桶不含有指针类型,那么它们可能会在遍历的过程中,若表发生了结构的变化,可能会取消对旧桶的引用,此时溢出桶就可能会被GC清理掉,所以当迭代器开始工作的时候,就需要将当前的溢出桶和旧的溢出桶保留在迭代器的结构中,保持对它们的引用。
if t.Bucket.PtrBytes == 0 {// Allocate the current slice and remember pointers to both current and old.// This preserves all relevant overflow buckets alive even if// the table grows and/or overflow buckets are added to the table// while we are iterating.h.createOverflow()it.overflow = h.extra.overflowit.oldoverflow = h.extra.oldoverflow}(3)通过取随机数的方式,决定遍历的起始桶,以及桶的遍历的起始kv对的位置
// decide where to startr := uintptr(rand())it.startBucket = r & bucketMask(h.B)it.offset = uint8(r >> h.B & (bucketCnt - 1))// iterator stateit.bucket = it.startBucket(4)进入遍历流程
mapiternext(it)4.4、mapiternext
func mapiternext(it *hiter) {h := it.h//...if h.flags&hashWriting != 0 {fatal("concurrent map iteration and map write")}t := it.tbucket := it.bucketb := it.bptri := it.icheckBucket := it.checkBucketnext:if b == nil {if bucket == it.startBucket && it.wrapped {// end of iterationit.key = nilit.elem = nilreturn}if h.growing() && it.B == h.B {// Iterator was started in the middle of a grow, and the grow isn't done yet.// If the bucket we're looking at hasn't been filled in yet (i.e. the old// bucket hasn't been evacuated) then we need to iterate through the old// bucket and only return the ones that will be migrated to this bucket.oldbucket := bucket & it.h.oldbucketmask()b = (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.BucketSize)))if !evacuated(b) {checkBucket = bucket} else {b = (*bmap)(add(it.buckets, bucket*uintptr(t.BucketSize)))checkBucket = noCheck}} else {b = (*bmap)(add(it.buckets, bucket*uintptr(t.BucketSize)))checkBucket = noCheck}bucket++if bucket == bucketShift(it.B) {bucket = 0it.wrapped = true}i = 0}for ; i < bucketCnt; i++ {offi := (i + it.offset) & (bucketCnt - 1)if isEmpty(b.tophash[offi]) || b.tophash[offi] == evacuatedEmpty {// TODO: emptyRest is hard to use here, as we start iterating// in the middle of a bucket. It's feasible, just tricky.continue}k := add(unsafe.Pointer(b), dataOffset+uintptr(offi)*uintptr(t.KeySize))if t.IndirectKey() {k = *((*unsafe.Pointer)(k))}e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+uintptr(offi)*uintptr(t.ValueSize))if checkBucket != noCheck && !h.sameSizeGrow() {// Special case: iterator was started during a grow to a larger size// and the grow is not done yet. We're working on a bucket whose// oldbucket has not been evacuated yet. Or at least, it wasn't// evacuated when we started the bucket. So we're iterating// through the oldbucket, skipping any keys that will go// to the other new bucket (each oldbucket expands to two// buckets during a grow).if t.ReflexiveKey() || t.Key.Equal(k, k) {// If the item in the oldbucket is not destined for// the current new bucket in the iteration, skip it.hash := t.Hasher(k, uintptr(h.hash0))if hash&bucketMask(it.B) != checkBucket {continue}} else {// Hash isn't repeatable if k != k (NaNs). We need a// repeatable and randomish choice of which direction// to send NaNs during evacuation. We'll use the low// bit of tophash to decide which way NaNs go.// NOTE: this case is why we need two evacuate tophash// values, evacuatedX and evacuatedY, that differ in// their low bit.if checkBucket>>(it.B-1) != uintptr(b.tophash[offi]&1) {continue}}}if (b.tophash[offi] != evacuatedX && b.tophash[offi] != evacuatedY) ||!(t.ReflexiveKey() || t.Key.Equal(k, k)) {// This is the golden data, we can return it.// OR// key!=key, so the entry can't be deleted or updated, so we can just return it.// That's lucky for us because when key!=key we can't look it up successfully.it.key = kif t.IndirectElem() {e = *((*unsafe.Pointer)(e))}it.elem = e} else {// The hash table has grown since the iterator was started.// The golden data for this key is now somewhere else.// Check the current hash table for the data.// This code handles the case where the key// has been deleted, updated, or deleted and reinserted.// NOTE: we need to regrab the key as it has potentially been// updated to an equal() but not identical key (e.g. +0.0 vs -0.0).rk, re := mapaccessK(t, h, k)if rk == nil {continue // key has been deleted}it.key = rkit.elem = re}it.bucket = bucketif it.bptr != b { // avoid unnecessary write barrier; see issue 14921it.bptr = b}it.i = i + 1it.checkBucket = checkBucketreturn}b = b.overflow(t)i = 0goto next
}(1)若处在并发写状态则fatal;初始化各项参数
if h.flags&hashWriting != 0 {fatal("concurrent map iteration and map write")}t := it.tbucket := it.bucketb := it.bptri := it.icheckBucket := it.checkBucket(2)外层主循环,遍历每一个bucket,当达到buckets的末尾的时候,标识wrapped为true,回到头部。
next:
if b == nil {//...b = (*bmap)(add(it.buckets, bucket*uintptr(t.BucketSize)))//...}bucket++if bucket == bucketShift(it.B) {bucket = 0it.wrapped = true}b = b.overflow(t)i = 0goto next(3)若遍历完所有的桶了,则退出函数
if bucket == it.startBucket && it.wrapped {// end of iterationit.key = nilit.elem = nilreturn}(4)map可能正在处于扩容阶段,若处在扩容阶段,并且当前range的B和map的B任然相同(仍然是同一级数),那么说明便利的顺序没有发生改变。若桶处于旧桶数组,且数据没有迁移完成,那么需要将checkBucket置为当前桶号,需要对其便利防止漏掉数据。
if h.growing() && it.B == h.B {oldbucket := bucket & it.h.oldbucketmask()//获取oldbucket在oldbuckets中的位置b = (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.BucketSize)))//若数据还没有完成迁移,那么还需要遍历这个桶的K-V对if !evacuated(b) {checkBucket = bucket} else {//否则,直接读取newbucketsb = (*bmap)(add(it.buckets, bucket*uintptr(t.BucketSize)))//表示bucket都迁移完了,不需要额外检查oldbucketscheckBucket = noCheck}
} else {//没有扩容,直接从buckets读取b = (*bmap)(add(it.buckets, bucket*uintptr(t.BucketSize)))checkBucket = noCheck}(5)开始遍历该bucket下的所有KV对,对于一个空的槽位,因为可能处在迁移过程,所以会存在evacuatedEmpty的标识,所以不能判断是不是后面都是空的,必须全部遍历一次。
for ; i < bucketCnt; i++ {offi := (i + it.offset) & (bucketCnt - 1)if isEmpty(b.tophash[offi]) || b.tophash[offi] == evacuatedEmpty {// TODO: emptyRest is hard to use here, as we start iterating// in the middle of a bucket. It's feasible, just tricky.continue}(6)获取槽位的KV
k := add(unsafe.Pointer(b), dataOffset+uintptr(offi)*uintptr(t.KeySize))if t.IndirectKey() {k = *((*unsafe.Pointer)(k))}e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+uintptr(offi)*uintptr(t.ValueSize))(7)对于map正在实施等量扩容的情况下,如果当前的key经过重新到hash映射,会被映射到另一个桶中,那这时候我们也应该严格按照新桶的顺序来遍历,所以跳过这个key。例如,我们现在正在遍历桶3的一个KV对,但是这个KV对将会被迁移至桶7,那我们也该在遍历桶7的时候再获取它,而不是现在获取。
if checkBucket != noCheck && !h.sameSizeGrow() {if t.ReflexiveKey() || t.Key.Equal(k, k) {hash := t.Hasher(k, uintptr(h.hash0))if hash&bucketMask(it.B) != checkBucket {continue}} else {if checkBucket>>(it.B-1) != uintptr(b.tophash[offi]&1) {continue}}}(8)通过读流程的mapaccessK方法来读取这个K-V对,通过迭代器hiter的key、value指针进行接收,用于对用户的遍历操作进行响应。
rk, re := mapaccessK(t, h, k)if rk == nil {continue // key has been deleted}it.key = rkit.elem = re文章转载自:MelonTe
原文链接:万字解析Golang的map实现原理 - MelonTe - 博客园
体验地址:引迈 - JNPF快速开发平台_低代码开发平台_零代码开发平台_流程设计器_表单引擎_工作流引擎_软件架构