一、Transformer介绍
Transformer 是一种基于 自注意力机制(Self-Attention)的深度学习架构,由 Google 在 2017 年的论文[《Attention Is All You Need》](https://arxiv.org/abs/1706.03762)中提出。它彻底改变了自然语言处理(NLP)领域,并成为现代大语言模型(如 GPT、BERT)的核心架构。
1、 Transformer 的核心思想
传统序列模型(如 RNN、LSTM)在处理长序列时存在 梯度消失和计算效率低的问题。Transformer 通过自注意力机制和并行计算解决了这些问题,与前面介绍的加入注意力的seq2seq不同,Transformer使用注意力机制完全代替了rnn。模型直接计算输入序列中任意两个词之间的关系,而不受距离限制。不同于 RNN 的逐词计算,Transformer 可以同时处理整个序列,大幅提升训练速度。
2、Transformer 的架构
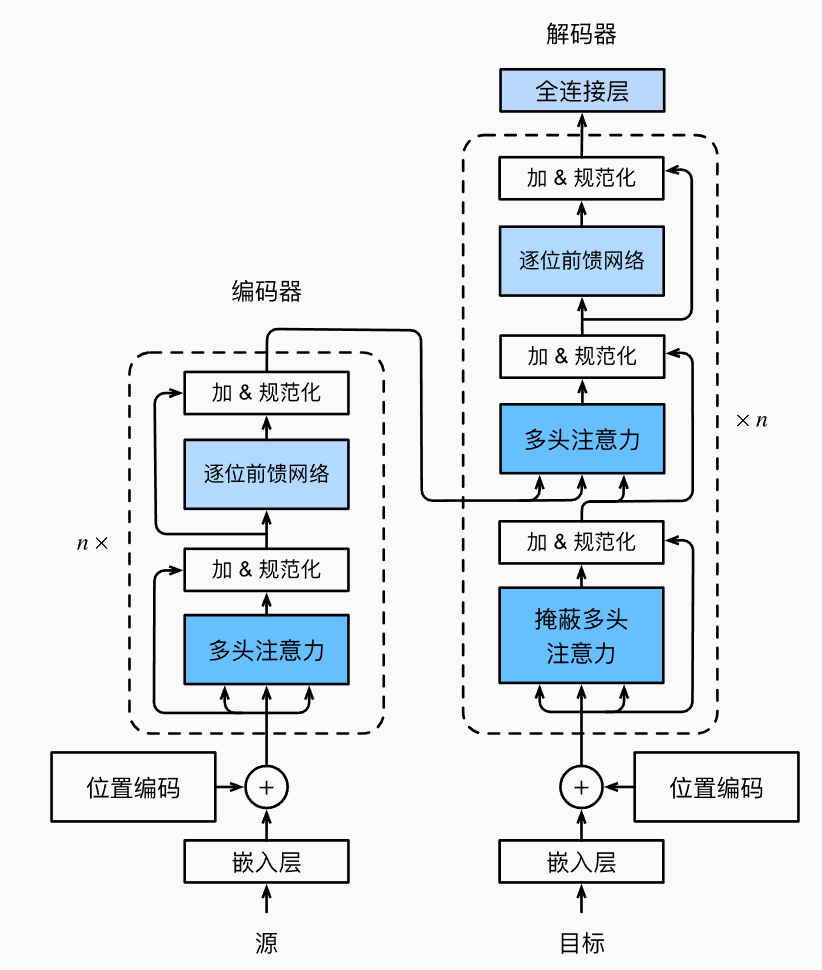
Transformer 使用编码器(Encoder)和解码器(Decoder)架构。
(1)编码器(Encoder)
由 N 个相同的层(通常 N=6)堆叠而成。
每层包含:
**多头自注意力(Multi-Head Self-Attention)
**前馈神经网络(Feed Forward Network, FFN)
**残差连接(Residual Connection)+ 层归一化(Layer Normalization)
(2)解码器(Decoder)
同样由N 个相同的层堆叠。
每层包含:
**掩码多头自注意力(Masked Multi-Head Self-Attention)(防止未来信息泄露)
**编码器-解码器注意力(Encoder-Decoder Attention):编码器的输出作为value和key,解码器输出作为query
**前馈神经网络(FFN)
**残差连接 + 层归一化
多头自注意力和位置编码
在前面文章已经提到动手学深度学习——注意力、自注意力和位置编码-CSDN博客
前馈神经网络
其实就是每个注意力层后接一个两层全连接网络

残差连接和层归一化
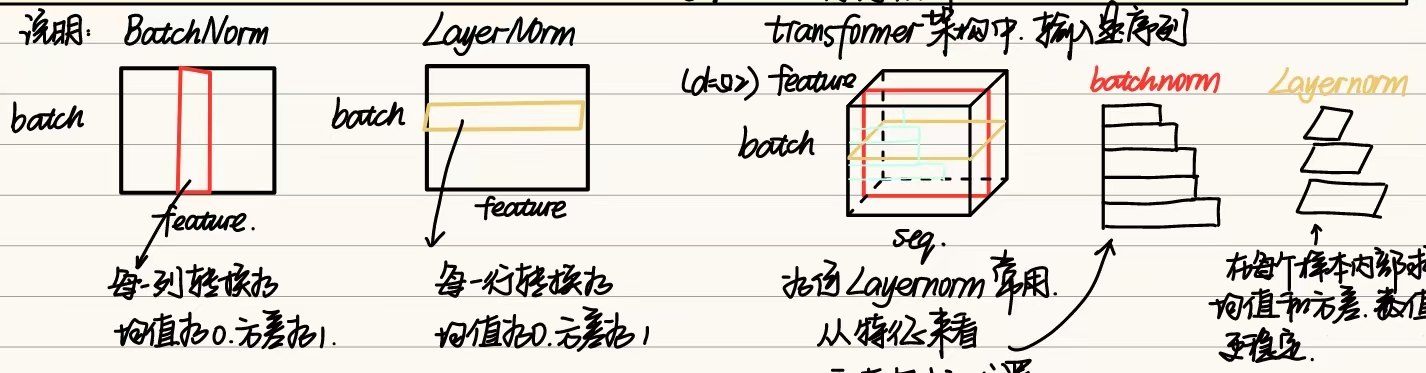
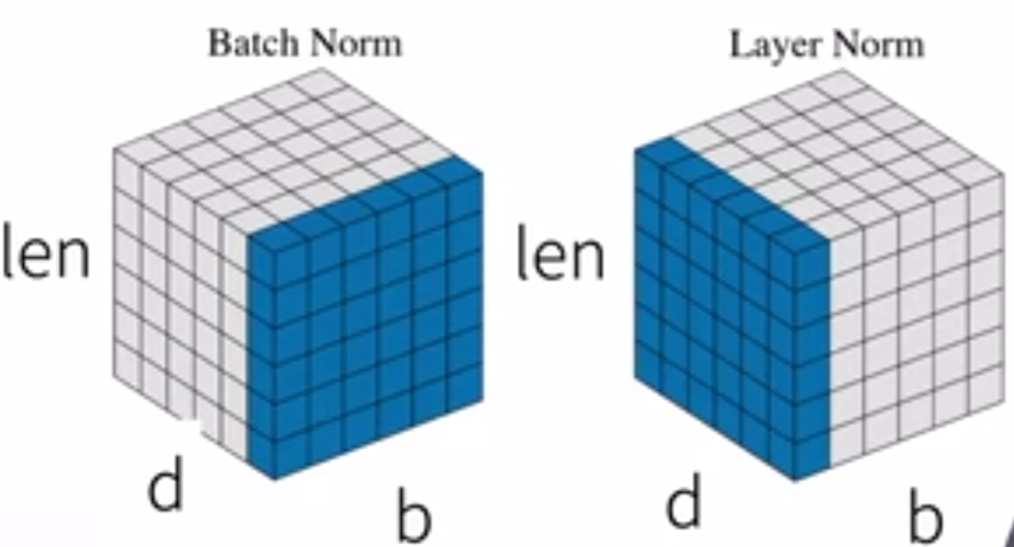
和之前的batchnorm有所区别,Transformer使用的是LayerNorm,对每一个样本的所有特征做归一化,可以避免序列长度不同的问题。
模型整体架构如下图所示
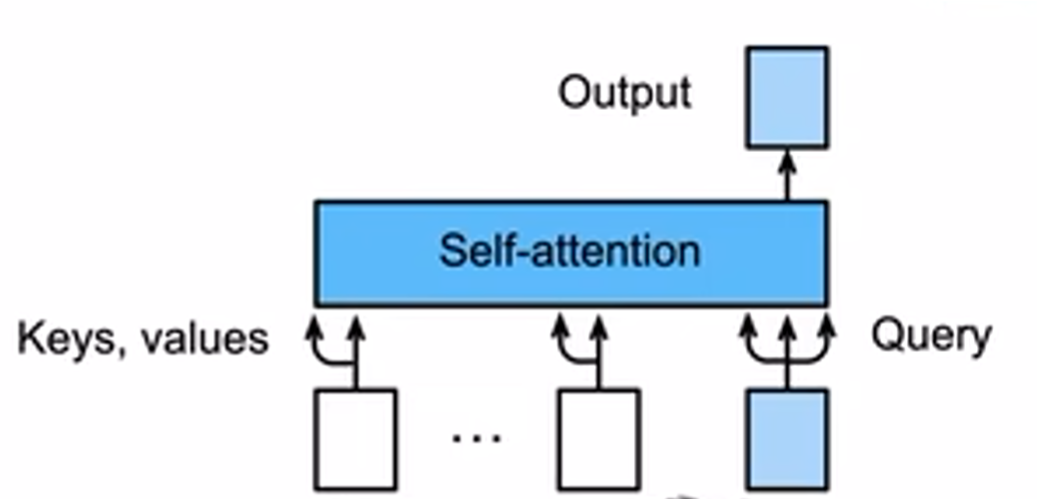
3、模型预测
模型预测第t+1个输出时,解码器中输入前t个预测值。在自注意力中,前t个预测值作为key和value,第t个预测值还作为query。
二、transformer实现
①导入需要的库
import math
import pandas as pd
import torch
from torch import nn
from d2l import torch as d2l②前馈神经网络、归一化层定义
class PositionWiseFFN(nn.Module):def __init__(self,ffn_num_input,ffn_num_hiddens,ffn_num_outputs,**kwargs):super().__init__(*kwargs)self.dense1 = nn.Linear(ffn_num_input,ffn_num_hiddens)self.relu = nn.ReLU()self.dense2 = nn.Linear(ffn_num_hiddens,ffn_num_outputs)def forward(self,X):return self.dense2(self.relu(self.dense1(X)))class AddNorm(nn.Module):def __init__(self,normalized_shape,dropout,*kwargs):super().__init__(*kwargs)self.ln = nn.LayerNorm(normalized_shape)self.dropout = nn.Dropout(dropout)def forward(self,X,Y):return self.ln(X + self.dropout(Y))③编码器
class EncoderBlock(nn.Module):'注意力层+残差链接和归一化层+前馈神经网络+残差链接和归一化层'def __init__(self,key_size, query_size, value_size, num_hiddens,norm_shape,ffn_num_input,ffn_num_hiddens,num_heads,dropout,use_bias=False,*kwargs):super().__init__(*kwargs)self.attention = MultiHeadAttention(key_size, query_size, value_size, num_hiddens,num_heads, dropout,use_bias)self.addnorm1 = AddNorm(norm_shape,dropout)self.ffn = PositionWiseFFN(ffn_num_input,ffn_num_hiddens,num_hiddens)self.addnorm2 = AddNorm(norm_shape,dropout)def forward(self,X,valid_lens):Y = self.addnorm1(X,self.attention(X,X,X,valid_lens))return self.addnorm2(Y,self.ffn(Y))X = torch.ones((2, 100, 24))
valid_lens = torch.tensor([3, 2])
encoder_blk = EncoderBlock(24, 24, 24, 24, [100, 24], 24, 48, 8, 0.5)
encoder_blk.eval()
encoder_blk(X, valid_lens).shapeclass TransformerEncoder(d2l.Encoder):def __init__(self,vocab_size, key_size, query_size, value_size,num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens,num_heads, num_layers, dropout, use_bias=False, *kwargs):super().__init__(*kwargs)self.embedding = nn.Embedding(vocab_size,num_hiddens)self.pos_encoding = d2l.PositionalEncoding(num_hiddens, dropout)self.num_hiddens = num_hiddensself.blk = nn.Sequential()for i in range(num_layers):self.blk.add_module('block'+str(i),EncoderBlock(key_size, query_size, value_size, num_hiddens,norm_shape,ffn_num_input,ffn_num_hiddens,num_heads,dropout,use_bias))def forward(self,X,valid_lens):X = self.pos_encoding(self.embedding(X)*math.sqrt(self.num_hiddens))self.attention_weights = [None]*len(self.blk)for i,blk in enumerate(self.blk):X = blk(X,valid_lens)self.attention_weights[i] = blk.attention.Attention.attention_weightsreturn X④解码器
class DecoderBlock(nn.Module):def __init__(self,key_size, query_size, value_size, num_hiddens,norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,dropout, i, **kwargs):super().__init__(**kwargs)self.i = iself.attention1 = MultiHeadAttention(key_size, query_size, value_size, num_hiddens,num_heads, dropout)self.addnorm1 = AddNorm(norm_shape,dropout)self.attention2 = MultiHeadAttention(key_size, query_size, value_size, num_hiddens,num_heads, dropout)self.addnorm2 = AddNorm(norm_shape,dropout)self.ffn = PositionWiseFFN(ffn_num_input,ffn_num_hiddens,num_hiddens)self.addnorm3 = AddNorm(norm_shape,dropout)def forward(self,X,state):enc_outputs,enc_valid_lens = state[0],state[1]if state[2][self.i] == None:key_values = X #训练阶段else:key_values = torch.cat((state[2][self.i],X),dim=1)state[2][self.i] = key_valuesif self.training:batch_size,num_steps,_ = X.shapedec_valid_lens = torch.arange(1,num_steps+1,device=X.device).repeat(batch_size,1)else:dec_valid_lens = NoneY = self.addnorm1(X,self.attention1(X,key_values,key_values,dec_valid_lens))Y2 = self.addnorm2(Y,self.attention2(Y,enc_outputs,enc_outputs,enc_valid_lens))return self.addnorm3(Y2,self.ffn(Y2)),stateclass TransformerDecoder(d2l.AttentionDecoder):def __init__(self,vocab_size, key_size, query_size, value_size,num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens,num_heads, num_layers, dropout, use_bias=False, **kwargs):super().__init__(**kwargs)self.num_layers = num_layersself.num_hiddens = num_hiddensself.embedding = nn.Embedding(vocab_size,embed_size)self.pos_encoding = d2l.PositionalEncoding(num_hiddens, dropout)self.blk = nn.Sequential()for i in range(len(num_layers)):self.blk.add_module("block"+str(i),DecoderBlock(key_size, query_size, value_size, num_hiddens,norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,dropout, i))self.dense = nn.Linear(num_hiddens,vocab_size)def init_state(self,enc_outputs,enc_valid_lens,*args):return [enc_outputs,enc_valid_lens,[None]*self.num_layers]def forward(self,X,state):X = self.pos_encoding(self.embedding(X)*math.sqrt(self.num_hiddens))self._attention_weights = [[None]*len(self.blk) for _ in range(2)]for i,blk in self.blk:X,state = blk(X,state)self._attention_weights[0][i] = blk.attention1.Attention.attention_weightsself._attention_weights[1][i] = blk.attention2.Attention.attention_weightsreturn self.dense(X),state@propertydef attention_weights(self):return self._attention_weights