概述
随着计算机视觉技术的发展,单目深度估计成为了连接二维图像世界与三维现实空间的重要桥梁。深度估计技术不仅在自动驾驶领域具有重要意义,而且在机器人导航、虚拟现实、增强现实等领域也有着广泛的应用前景。在上一篇文章中我们简单介绍了一下利用拉普拉斯金字塔深度残差的单目深度估计,在此基础上,本篇将会带领大家跑一遍demo,对该项目有个更直观的理解
论文名字:Monocular_Depth_Estimation_Using_Laplacian_Pyramid-Based_Depth_Residuals
项目地址:https://github.com/tjqansthd/LapDepth-release/tree/master

一、准备工作
1、安装相关库
- python >= 3.7
- Pytorch >= 1.6.0(如果使用gpu就安装gpu的版本)
- 其他:geffnet, path, IPython, blessings, progressbar
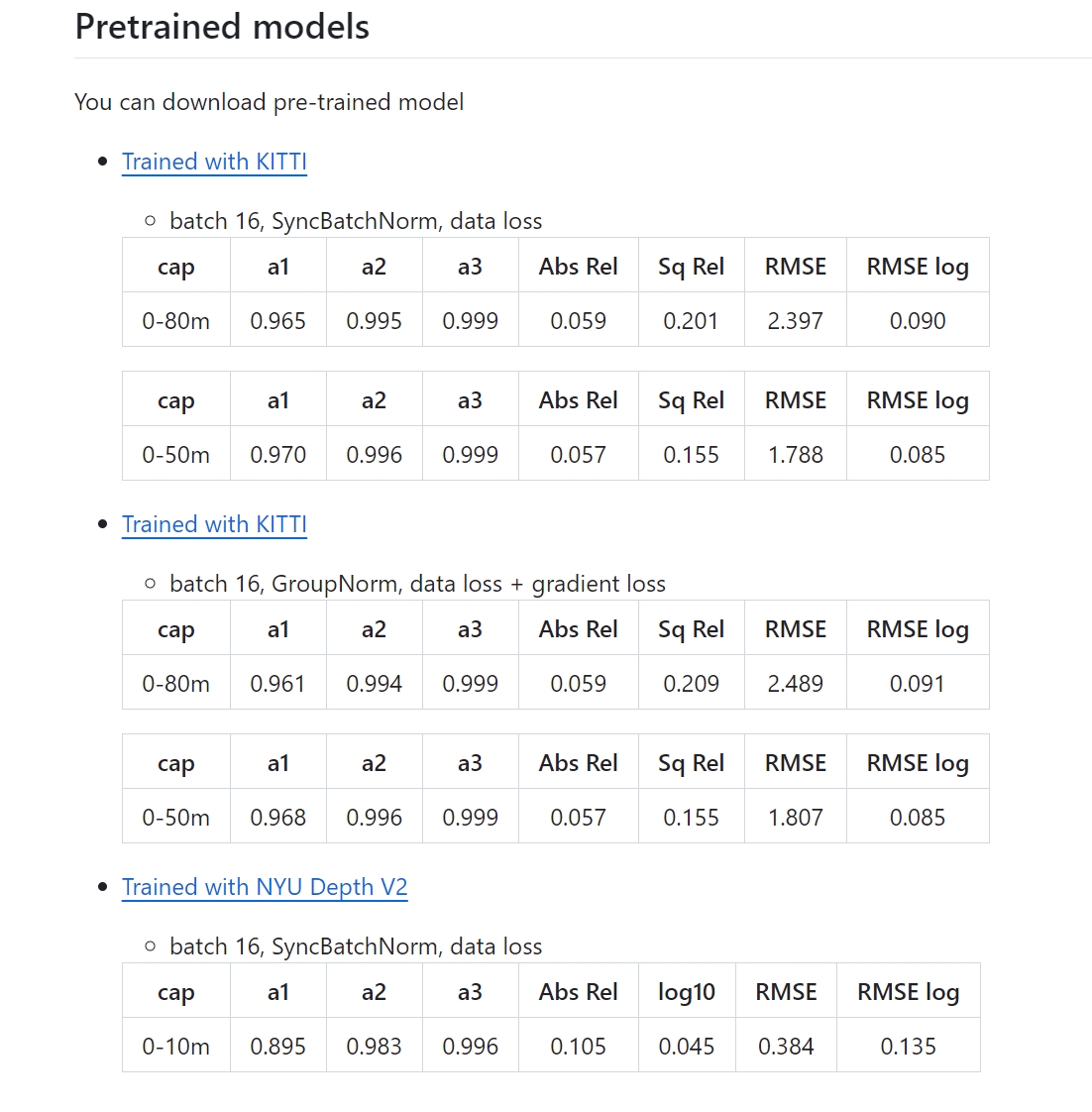
2、下载预训练模型
项目提供了三个预训练的模型,其指标如下所示
二、工作流程
该demo的目标在于,使用预训练的深度估计模型(Laplacian Depth Residual Network,简称LDRN)来预测图像的深度图。最重要的是,该模型可以使用KITTI数据集,并且可以根据输入的是单张图片还是一个图片文件夹来进行处理。接下来我们详细看看各部分
1.命令行参数解析
使用argparse模块解析命令行参数,包括模型目录、输入图像或文件夹目录、使用的编码器类型、是否使用预训练权重、是否使用CUDA等。下面贴出来几行示例
# 文件设置 parser.add_argument('--model_dir',type=str, default = '')
parser.add_argument('--img_dir', type=str, default = None)
parser.add_argument('--img_folder_dir', type=str, default= None)
...# 模型设置
parser.add_argument('--pretrained', type=str, default = "KITTI")
...# GPU 设置
parser.add_argument('--cuda', action='store_true')
parser.add_argument('--gpu_num', type=str, default = "0,1,2,3", help='force available gpu index')
...
2、环境配置:
根据用户是否指定了使用CUDA(即GPU加速)来设置环境变量,并告知用户当前使用的是CPU还是CUDA。
if args.cuda and torch.cuda.is_available():os.environ["CUDA_VISIBLE_DEVICES"]= args.gpu_numcudnn.benchmark = Trueprint('=> on CUDA')
else:print('=> on CPU')
3、加载模型:
根据提供的参数实例化LDRN模型。将模型转换为多GPU模式(如果有多个GPU的话)。加载预训练模型权重。设置模型为评估模式。
model = LDRN(args)
if args.cuda and torch.cuda.is_available():Model = Model.cuda()
Model = torch.nn.DataParallel(Model)
assert (args.model_dir != ''), "Expected pretrained model directory"
Model.load_state_dict(torch.load(args.model_dir))
Model.eval()
4、获取图像列表:
如果提供了单个图像文件路径,则将其添加到图像列表中。如果提供了图像文件夹路径,则获取该文件夹下所有的PNG和JPG图像文件路径,并按字母顺序排序后添加到图像列表中。
if args.img_dir is not None:pass
elif args.img_folder_dir is not None:if args.img_folder_dir[-1] == '/':args.img_folder_dir = args.img_folder_dir[:-1]pass
5、预处理图像:
遍历图像列表中的每一个图像文件路径。使用Image.open()方法打开图像,并将其转换为numpy数组。如果图像只有一个通道(灰度图),则将其扩展为三个通道。 转换图像维度,从(H, W, C)变为(C, H, W),以符合PyTorch的输入格式。之后将numpy数组转换为torch.Tensor。
for i, img_file in enumerate(img_list):img = Image.open(img_file)img = np.asarray(img, dtype=np.float32)/255.0if img.ndim == 2:img = np.expand_dims(img,2)img = np.repeat(img,3,2)img = img.transpose((2, 0, 1))img = torch.from_numpy(img).float()img = normalize(img)if args.cuda and torch.cuda.is_available():img = img.cuda()
6、调整图像大小
首先获取图像的原始高度和宽度。将图像维度扩展为(batch_size, channels, height, width),其中batch_size为1。再根据使用的预训练模型,调整图像的高度和宽度,使其能被16整除,并使用双线性插值进行重采样。
_, org_h, org_w = img.shapeimg = img.unsqueeze(0)if args.pretrained == 'KITTI':new_h = 352new_w = org_w * (352.0/org_h)new_w = int((new_w//16)*16)img = F.interpolate(img, (new_h, new_w), mode='bilinear')
elif args.pretrained == 'NYU':new_h = 432new_w = org_w * (432.0/org_h)new_w = int((new_w//16)*16)img = F.interpolate(img, (new_h, new_w), mode='bilinear')
7、预测
我们可以直接使用模型输出的预测图象(注释部分),但是为了提高其鲁棒性,代码中先计算原图的深度图,再计算翻转后的图像的深度图,最后取两者的平均作为最终的深度图。
# depth prediction
#with torch.no_grad():
# _, out = Model(img)img_flip = torch.flip(img,[3])
with torch.no_grad():_, out = Model(img)_, out_flip = Model(img_flip)out_flip = torch.flip(out_flip,[3])out = 0.5*(out + out_flip)点击:【计算机视觉】深度估计-LapDepth-demo使用示例———古月居可查看全文