文章目录
- 问题设计
- Q-learning
- 原理
- 模拟
- 参数设计
- Q-table初始化
- 学习过程
- 第一次
- 第二次
- 第三次
- 中间省略1000次
- 结果
- DQN(深度Q-learning)
- 经验回放
- 原理
- 模拟
- 参数设计
- 学习过程
- 结果
在之前学习的过程中我了解到深度学习中很重要的一个概念是反向传播,最近看论文发现深度强化学习(DRL)有各种各样的方法,但是却很难区分他们的损失函数的计算以及反向传播的过程有何不同。在有监督的学习中,损失可以理解为预测值和真实值之间的距离,那么在这里的损失指的是什么?是否也涉及到两个值之间的差距呢,具体是哪两个东西之间的拟合(学习)?如何拟合?这里通过举例对几种强化学习方法进行比较。
问题设计

假设有一个3×3的迷宫(如上图),用S表示起点(入口)、E表示终点(出口)、O表示通路、W表示墙壁,目标是从S到E找到一条通路。
Q-learning
原理
Q-learning是一种基于值函数的强化学习方法,其核心思想是通过更新和维护动作值函数 Q ( s , a ) Q(s,a) Q(s,a)来间接推导出最优策略,使用Q-table存储每个状态-动作对的期望奖励。与深度学习中的反向传播不同,Q-learning在传统实现中并不依赖反向传播。
Q ( s , a ) Q(s,a) Q(s,a)的更新公式为贝尔曼方程:
Q ( s , a ) ← Q ( s , a ) + α [ r + γ max a ′ Q ( s ′ , a ′ ) − Q ( s , a ) ] Q(s,a)←Q(s,a)+α[r+γ\max_{a'}Q(s',a')-Q(s,a)] Q(s,a)←Q(s,a)+α[r+γa′maxQ(s′,a′)−Q(s,a)]
其中, α α α是学习率, γ γ γ是折扣因子, r r r是当前奖励, s ′ s' s′是下一个状态。这是一个迭代更新公式,直接对Q-table进行更新,无需显式的梯度计算或反向传播,Q-table存储了所有状态-动作对的值,更新过程是逐个元素地调整表格中的值。
模拟
参数设计
- 奖励规则:到达终点奖励+100;到达墙壁或超出迷宫奖励-10;其他情况奖励分值为6-到出口最短路线距离(假设这些距离提前都计算好了)。比如走到(1,0)+3,走到(2,2)+4,走到(0,1)-10,走到(0,2)+100。
- 贝尔曼方程参数: α = 0.8 α=0.8 α=0.8; γ = 0.2 γ=0.2 γ=0.2。
Q-table初始化
初始化一个Q-table,大小为状态数×行为数。对于3×3的迷宫,状态数为9(每个格子为一个状态),行为数为4(上下左右)。初始化Q-table为0:

学习过程
第一次
状态和状态转移:
| 状态s | 行为(随机) | 下一个状态s’ |
|---|---|---|
| (0,0) | UP | × |
更新Q-table:
| 原始Q[(0,0), UP] | 奖励 | 下一状态能获得的最大奖励 | 更新后的Q[(0,0), UP] |
|---|---|---|---|
| 0 | -10 | 0 | -8 |
结果:

第二次
状态和状态转移:
| 状态s | 行为(随机) | 下一个状态s’ |
|---|---|---|
| (0,0) | DOWN | (1,0) |
更新Q-table:
| 原始Q[(0,0), DOWN] | 奖励 | 下一状态能获得的最大奖励 | 更新后的Q[(0,0), DOWN] |
|---|---|---|---|
| 0 | +3 | 0 | 2.4 |
结果:

第三次
| 状态s | 行为(随机) | 下一个状态s’ | 原始Q[(1,0), RIGHT] | 奖励 | 下一状态能获得的最大奖励 | 更新后的Q[(1,0), RIGHT] |
|---|---|---|---|---|---|---|
| (1,0) | RIGHT | (1,1) | 0 | +4 | 0 | 3.2 |
结果:

中间省略1000次
| 状态s | 行为(随机) | 下一个状态s’ | 原始Q[(1,1), LEFT] | 奖励 | 下一状态能获得的最大奖励 | 更新后的Q[(1,1), LEFT] |
|---|---|---|---|---|---|---|
| (1,1) | LEFT | (1,0) | 0 | +3 | 3.2 | 2.912 |
| 状态s | 行为(随机) | 下一个状态s’ | 原始Q[(1,0), DOWN] | 奖励 | 下一状态能获得的最大奖励 | 更新后的Q[(1,0), DOWN] |
|---|---|---|---|---|---|---|
| (1,0) | DOWN | (2,0) | 0 | +2 | 0 | 1.6 |
自己抽签和计算太麻烦了,于是写了代码大致模拟了一下。
# Dangerous
import randomkeys = [(0,0,'up'), (0,0,'down'), (0,0,'left'), (0,0,'right'),(0,1,'up'), (0,1,'down'), (0,1,'left'), (0,1,'right'),(0,2,'up'), (0,2,'down'), (0,2,'left'), (0,2,'right'),(1,0,'up'), (1,0,'down'), (1,0,'left'), (1,0,'right'),(1,1,'up'), (1,1,'down'), (1,1,'left'), (1,1,'right'),(1,2,'up'), (1,2,'down'), (1,2,'left'), (1,2,'right'),(2,0,'up'), (2,0,'down'), (2,0,'left'), (2,0,'right'),(2,1,'up'), (2,1,'down'), (2,1,'left'), (2,1,'right'),(2,2,'up'), (2,2,'down'), (2,2,'left'), (2,2,'right')]
values = [-8,2.4,0,0,0,0,0,0,0,0,0,0,0,0,0,3.2,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0] # 经历三次学习后的值rewards = [[2, -10, 100], [3, 4, 5], [2, -10, 4]]action_list = ['up', 'down', 'left', 'right']qTable = dict(zip(keys, values)) # 创建初始列表alpha = 0.8
gamma = 0.2now_x = 1
now_y = 1def transfer_x(x, act):if act == 'up': return x-1elif act == 'down': return x+1else: return xdef transfer_y(y, act):if act == 'left': return y-1elif act == 'right': return y+1else: return yfor i in range(1000): # 学习1000次action = random.choice(action_list) # 行为next_x = transfer_x(now_x, action) # 下一个状态s'next_y = transfer_y(now_y, action)before_q = qTable[(now_x, now_y, action)] # 原始Qif next_x not in [0,1,2] or next_y not in [0,1,2]: # 奖励reward = -10else: reward = rewards[next_x][next_y]if next_x not in [0, 1, 2] or next_y not in [0, 1, 2]: # 下一状态能获得的最大奖励max_reward = 0else:max_reward = 0for a in action_list:r = qTable[(next_x, next_y, a)]if r > max_reward: max_reward = rqTable[(now_x, now_y, action)] = before_q + alpha * (reward + gamma * max_reward - before_q) # 更新后的Q值random_start_list = [(0,0), (1,0), (1,1), (1,2), (2,0), (2,2)]random_start = random.choice(random_start_list)random_p = random.randint(1,10)random_flag = True if random_p == 1 else Falseif next_x == 0 and next_y == 2: # 如果走到终点就从随机位置开始now_x = random_start[0]now_y = random_start[1]elif next_x not in [0, 1, 2] or next_y not in [0, 1, 2]:# 如果走出去就不改变当前位置(以0.1的概率随机初始位置)if random_flag:now_x = random_start[0]now_y = random_start[1]elif next_y == 1 and (next_x == 0 or next_x == 2):# 如果走到墙上就不改变当前位置(以0.1的概率随机初始位置)if random_flag:now_x = random_start[0]now_y = random_start[1]else: # 或者以0.1的概率随机初始位置now_x = next_xnow_y = next_yif random_flag:now_x = random_start[0]now_y = random_start[1]# 打印Q表
for key in qTable:print("key:" + str(key) + " " + str(qTable[key]))
结果
得到结果如下:

其中阴影部分是墙和终点的位置,由于无法到达墙、到达终点后游戏结束,所以这两个位置不会更新Q值。
上表的解释:在(0,0)位置时(对应当前状态),Q值在行为"down"处最大为4.8,因此应该向下走,下一个状态是(1,0)。其余位置类似。

红色箭头表示每一个状态的最优行为,绿色箭头表示用该方法计算得出的最优路线。
DQN(深度Q-learning)
DQN和Q学习的主要区别在于如何表示和更新Q值,DQN使用神经网络来近似Q值函数,而不是使用表格。
经验回放
经验回放(Experience Replay)是强化学习中的一个重要技术,主要用于解决强化学习算法中的一些问题,提高算法的稳定性和学习效率。

具体来说,就是不每次都立刻进行Q值计算和反向传播,而是将每次的<状态、动作、状态转移>(称为经验样本或经验元组)先放到缓冲区,然后每次从缓冲区取一部分一次性计算。类似计算机视觉中同时对数据集中的多张图片进行处理,大小表示为batch_size。
原理
其实就是将Q学习中需要查Q-table的时候都用网络替换。旧的Q表值和奖励共同作用下更新为新的Q表值。
(我以前一直以为是要让Q值越来越拟合奖励,所以很奇怪,明明奖励的公式我们已经知道了,还要怎么去学习呢,其实奖励只是作为一个已知的数值加入到计算中,并不是说我们要去模拟奖励的生成方式。)
Q-learning中的贝尔曼方程:
Q ( s , a ) ← Q ( s , a ) + α [ r + γ max a ′ Q ( s ′ , a ′ ) − Q ( s , a ) ] Q(s,a)←Q(s,a)+α[r+γ\max_{a'}Q(s',a')-Q(s,a)] Q(s,a)←Q(s,a)+α[r+γa′maxQ(s′,a′)−Q(s,a)]
可以写为:
Q ( s , a ) ← ( 1 − α ) Q ( s , a ) + α [ r + γ max a ′ Q ( s ′ , a ′ ) ] Q(s,a)←(1-α)Q(s,a)+α[r+γ\max_{a'}Q(s',a')] Q(s,a)←(1−α)Q(s,a)+α[r+γa′maxQ(s′,a′)]
就像加权求和,它在原来Q的基础上加上了一部分奖励作用下的分数。
深度Q-learning中的损失函数:
L ( θ ) = E s , a , r , s ′ [ ( Q θ ( s , a ) − ( r + γ max a ′ Q θ − ( s ′ , a ′ ) ) ) 2 ] L(θ)=\mathbb{E}_{s,a,r,s'}[(Q_θ(s,a)-(r+γ\max_{a'}Q_{θ^-}(s',a')))^2] L(θ)=Es,a,r,s′[(Qθ(s,a)−(r+γa′maxQθ−(s′,a′)))2]
它就是使计算得到的Q值逐渐趋于稳定,基本上等于那个奖励作用下的分数,这个分数不仅考虑了当前奖励,还考虑了下一步能够得到的分数。注意上式中有两组参数,分别为 θ θ θ和 θ − θ^- θ−,对应两个网络(结构一样)。
- Q θ ( s , a ) Q_θ(s,a) Qθ(s,a)通过主网络训练得到
主网络(Main Network)也称为在线网络(Online Network)或当前网络(Current Network)。主网络负责学习环境中的状态-动作值函数(Q函数),即预测在给定状态下采取某个动作所能获得的预期回报。主网络通过梯度下降等优化算法不断更新其参数,以最小化预测Q值和实际Q值之间的差距。主网络直接与环境交互,根据采集到的经验(状态、动作、奖励、下一个状态)进行学习。 - max a ′ Q θ − ( s ′ , a ′ ) \max_{a'}Q_{θ^-}(s',a') maxa′Qθ−(s′,a′)由目标网络计算
目标网络(Target Network)是主网络的一个延迟更新版本,其参数定期从主网络复制过来。目标网络不直接参与学习,而是为主网络提供一个稳定的训练目标。在计算Q值的目标值时,使用目标网络来预测下一个状态下的Q值,这样可以减少学习过程中的方差,使学习更加稳定。目标网络的更新频率通常低于主网络,例如,每几千个时间步更新一次。
说明通过神经网络得到的Q值不仅体现了当前决策的奖励,还综合了未来的奖励。
模拟
参数设计
- 奖励规则:到达终点奖励+1000;到达墙壁或超出迷宫奖励-1000;其他情况奖励分值不等(假设这些距离提前都计算好了),迷宫格内的奖励矩阵可以表示为:
R = [ 5 − 1000 1000 50 200 500 5 − 1000 200 ] R=\begin{bmatrix} 5&-1000&1000 \\ 50&200&500 \\ 5&-1000&200 \end{bmatrix} R= 5505−1000200−10001000500200 - 损失函数贝尔曼方程参数: γ = 0.4 γ=0.4 γ=0.4。
- 网络输入:状态 s s s,由坐标表示(长度为2的列表)。从上往下三行的行号分别为0、1、2,从左到右三列的列标号分别为0,1,2,
(0,0)是起点位于左上角,(0,2)是终点位于右上角。 - 网络输出:每个动作的Q值(长度为4的列表)。
- 隐藏层架构:1层有16个神经元的全连接层,激活函数为ReLU。
- 梯度学习率:0.01。
- ε-贪婪策略:初始阶段,以较高概率ϵ(设置为1.0)随机选择动作。随着训练进行,逐渐降低ϵ(最后衰减到0.25),更多地依赖网络预测的动作。衰减速度为0.995。
- 经验回放:缓冲区大小为 100 100 100, b a t c h s i z e = 32 batch_{size}=32 batchsize=32。
- 同步目标网络步长为100。
10.训练次数:1000
学习过程
- 初始化将智能体放置在起点
(0,0)。 - 选择动作。使用ε-贪婪策略选择动作a。如果 r a n d o m < ϵ random<ϵ random<ϵ,随机选择动作。否则,选择 a r g max a Q θ ( s , a ) arg\max_aQ_θ(s,a) argmaxaQθ(s,a)。
- 执行动作:根据选定的动作 a a a,更新智能体的位置 s ′ s′ s′。如果超出迷宫范围或撞到障碍墙,给予奖励并结束回合;如果到达终点 (0, 2),给予奖励 100 并结束回合;否则,根据奖励矩阵 R R R给出奖励 r r r并继续选择下一步动作。
- 存储经验:将经验存入缓冲区。
- 采样并更新网络:从缓冲区中随机采样一批数据计算目标值。
更新主网络参数 θ θ θ以最小化损失函数 L ( θ ) L(θ) L(θ)。 - 同步目标网络:每隔若干步,将主网络参数复制到目标网络。
- 测试(关闭探索,使用网络预测的动作观察智能体是否能够成功从起点走到终点)。
# Dangerousimport torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import randomdef plus1(state): # 原来以为输入是0有可能会在乘法计算的时候使参数不生效,所以统一加了1,后来发现不加1效果更好,可见没必要考虑是否非0# return [x+1 for x in state]return stateclass DQNAgent:def __init__(self, state_size, action_size):self.state_size = state_size # 状态向量大小=2(x坐标和y坐标)self.action_size = action_size # 动作向量大小=4self.memory = [] # 经验缓冲区self.memory_size = 100self.gamma = 0.4 # 折扣因子self.epsilon = 1.0 # 初始εself.epsilon_min = 0.25 # ε衰减下限self.epsilon_decay = 0.995 # ε衰减率self.learning_rate = 0.01 # 学习率αself.model, self.optimizer = self._build_model() # 主网络self.target_model, self.optimizer_bed = self._build_model() # 目标网络self.update_target_model() # 同步网络参数def _build_model(self):class NeuralNetwork(nn.Module):def __init__(self, input_dim, output_dim):super(NeuralNetwork, self).__init__()# 隐藏层大小为16self.fc1 = nn.Linear(input_dim, 16)self.fc2 = nn.Linear(16, output_dim)def forward(self, x):x = torch.relu(self.fc1(x))return self.fc2(x)model = NeuralNetwork(self.state_size, self.action_size)optimizer = optim.Adam(model.parameters(), lr=self.learning_rate)return model, optimizerdef update_target_model(self):# Copy weights from the main model to the target modelself.target_model.load_state_dict(self.model.state_dict())def remember(self, state, action, reward, next_state, done):if len(self.memory) >= self.memory_size:self.memory.pop(0)self.memory.append((state, action, reward, next_state, done))def act(self, state): # 已知状态# 要么随机选择动作if np.random.rand() <= self.epsilon:return random.choice(range(self.action_size))# 要么选择下一个最有可能的动作state = torch.tensor(plus1(state), dtype=torch.float32).unsqueeze(0) # 在0维插入一个维度 # plus1(state)q_values = self.model(state).detach().numpy() # 计算Q值return np.argmax(q_values[0])""" .unsqueeze()插入维度大多数深度学习框架(包括 PyTorch)中的神经网络模型期望输入数据具有特定的形状。对于全连接网络,输入通常需要是二维张量,形状为(batch_size, input_dim):batch_size:表示批量大小,即一次输入的数据样本数量。input_dim:表示每个样本的特征维度。例如,如果 state 是 [0, 0],它的原始形状是 (2,),表示一个一维数组。但神经网络期望输入的是 (1, 2),其中 1 表示批量大小(只有 1 个样本),2 表示状态的特征维度。"""""".detach() 方法会创建一个新的张量,与原张量共享数据但不记录梯度信息。也就是说,使用 .detach() 后的张量不再参与反向传播计算。"""def replay(self, batch_size):if len(self.memory) < batch_size:return # 前31个经验样本只生成不训练minibatch = random.sample(self.memory, batch_size) # 从memory中随机抽取batch_size个样本for state, action, reward, next_state, done in minibatch:state = torch.tensor(plus1(state), dtype=torch.float32).unsqueeze(0) # plus1(state)next_state = torch.tensor(plus1(next_state), dtype=torch.float32).unsqueeze(0) # plus1(state)# 计算Q值是奖励值r加未来回报,要判断有没有下一步从而判断加不加回报target = rewardif not done:"""torch.max()返回最大值和索引"""target = reward + self.gamma * torch.max(self.target_model(next_state)).item()target_f = self.model(state).clone().detach().numpy()[0] # 用主网络计算得到的当前状态的Q值target_f[action] = target # 更新对应动作下的理想Q值用于计算损失(不更新经验缓冲池)target_f = torch.tensor(target_f, dtype=torch.float32).unsqueeze(0)# Compute loss and backpropagateself.optimizer.zero_grad() # 将所有梯度清零prediction = self.model(state)loss = nn.MSELoss()(prediction, target_f) # 计算实际Q值与理想Q值的损失loss.backward() # 计算梯度self.optimizer.step() # 根据梯度更新参数print("\t loss:{}".format(loss))# Decay epsilonif self.epsilon > self.epsilon_min:self.epsilon *= self.epsilon_decay# Define the environment
def get_reward(state):x, y = staterewards = [[5, -1000, 1000], [50, 200, 500], [5, -1000, 200]]if x < 0 or x >= 3 or y < 0 or y >= 3:return -1000return rewards[x][y]def is_terminal(state):x, y = statereturn (x == 0 and y == 2)def move(state, action):x, y = stateif action == 0: # UPx -= 1elif action == 1: # DOWNx += 1elif action == 2: # LEFTy -= 1elif action == 3: # RIGHTy += 1return [x, y]# Train the agent
state_size = 2
action_size = 4
agent = DQNAgent(state_size, action_size)
batch_size = 32
episodes = 1000for e in range(episodes):# state_start_list = [[0,0], [1,0], [1,1], [1,2], [2,0], [2,2]]# state = state_start_list[random.randint(0, len(state_start_list)-1)]"""本来在想每次都从起点走会不会导致第三行的格子学习次数少,数据证明每次都从起点走才效果更好,可能是因为前几步的可靠性会有利于后面的选择"""state = [0, 0]done = Falsei = 0while not done: # 每个epoch走到游戏失败就结束,步长不一定相同i += 1action = agent.act(state)next_state = move(state, action)reward = get_reward(next_state)done = is_terminal(next_state) or reward == -1000agent.remember(state, action, reward, next_state, done)state = next_stateif len(agent.memory) > batch_size:agent.replay(batch_size)if e % 20 == 0: # 同步目标网络步长为50agent.update_target_model() # Update target network periodicallyprint(f"Episode {e+1}/{episodes}, epsilon: {agent.epsilon}")# 测试
print("---------------------训练完成---------------------\n")
for x in [0, 1, 2]:for y in [0, 1, 2]:if y == 1 and x != 1:continueif x == 0 and y == 2:continuestate = [x, y]print(state, ":")state = torch.tensor(plus1(state), dtype=torch.float32).unsqueeze(0) # 在0维插入一个维度 # plus1(state)q_values = agent.model(state).detach().numpy() # 计算Q值action = np.argmax(q_values[0])action_list = ["up", "down", "left", "right"]for i in range(4):print("\t\t", action_list[i], ": ", q_values[0][i])print("\n---------------------模拟结果---------------------")
state = [0, 0]
done = False
step = 0 # 记录步长
action_time = [0, 0, 0, 0]
while not done:print("当前位置为:", state)state_temp = torch.tensor(plus1(state), dtype=torch.float32).unsqueeze(0) # 在0维插入一个维度 # plus1(state)q_values = agent.model(state_temp).detach().numpy() # 计算Q值action_old = np.argmax(q_values[0])print("\t old q_values:", q_values[0])"""本来把重复路线加到了学习的过程中,想减少‘摆烂’绕圈的情况,但是发现步长并没有作为状态输入,所以这样反而会导致奖励一直在变化而无法学习"""action_time[action] += 1q_values[0][action_old] -= action_time[action]*5 # 减少重复路线action_new = np.argmax(q_values[0]) # 根据新的奖励选择动作print("\t new q_values:", q_values[0])action = np.argmax(q_values[0])next_state = move(state, action)print("\t执行动作:", action_list[action])print("\t下一位置为:", next_state)reward = get_reward(next_state)done = is_terminal(next_state) or reward == -1000if done:print("**********停止**********, terminal? ", is_terminal(next_state), " reward=-400: ", reward==-400)if is_terminal(next_state):print("到达终点")state = next_state
print("---------------------模拟结束---------------------")
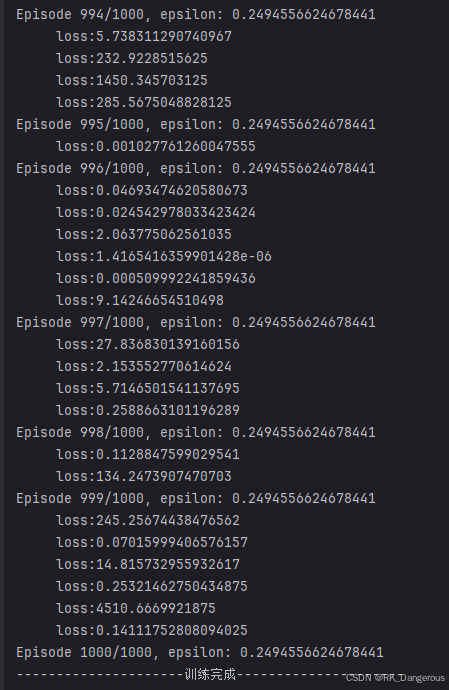
结果
每个位置上动作的Q值如下:
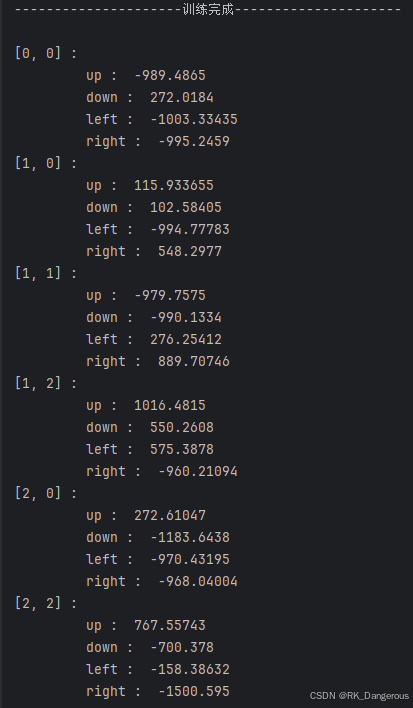
一次推理的结果如下:
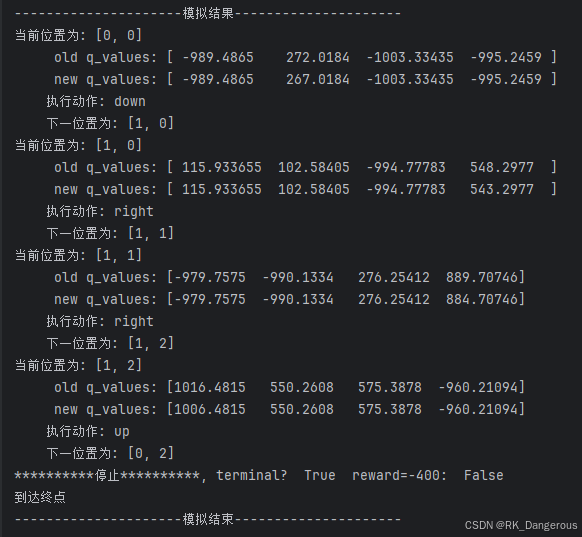
所得结果与Q-learning相同,图示为:
红色箭头表示每一个状态的最优行为,绿色箭头表示用该方法计算得出的最优路线。
【欢迎指正】
特别鸣谢:YanJiayi