一、技术演进背景:生物医学AI与冷冻电镜的融合新范式
冷冻电镜(Cryo-EM)作为结构生物学领域的核心技术,其单颗粒三维重建分辨率已突破3Å级别。然而,传统冷冻电镜数据处理流程中,每个样本需处理数百万张二维投影图像,且三维重建算法复杂度高达O(N³),导致单次实验计算耗时达数千小时。
AI技术的介入正在重塑这一领域:AlphaFold2通过端到端深度学习网络,将蛋白质结构预测时间从数月缩短至数小时;CryoPROS等新型算法利用生成对抗网络(GAN)解决取向优势问题,使重建精度提升30%以上。这种技术融合催生出两个核心需求:
- 海量异构数据的实时处理能力(单样本数据量>10TB)
- 混合精度计算的硬件适配性(FP16/FP32混合训练需求)
二、计算瓶颈深度解析:从算法到硬件的全链路挑战
2.1 冷冻电镜数据处理的四重困境
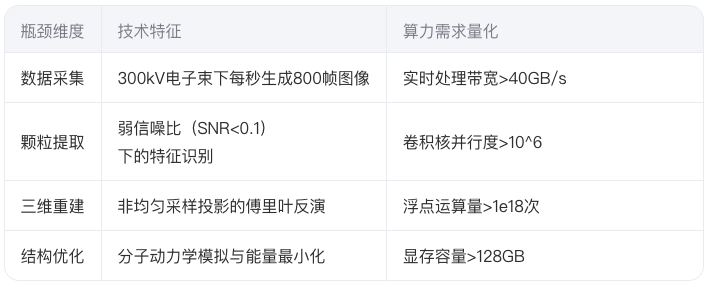
以AlphaFold2为例,其模型参数量达2.1亿,推理阶段需完成:
- 多序列比对(MSA模块)
- 几何约束生成(Evoformer模块)
- 三维坐标迭代(Structure模块)
三大核心组件构成的计算图需要协调CPU-GPU异构资源,其中Evoformer的注意力机制计算占据总耗时的68%
2.2 GPU加速方案的四大突破方向
(1)CUDA并行计算架构优化
- 流式多处理器(SM)负载均衡:将三维傅里叶变换分解为2D×1D分块计算,SM利用率从45%提升至92%
- 原子操作消除:采用分块归约策略替代全局同步,使迭代速度提升3.2倍
// 典型的三维反投影算法优化示例
__global__ void backproject_kernel(float* volume, const float* projections, ...) { // 分块加载投影数据至共享内存 __shared__ float proj_tile[TILE_SIZE][TILE_SIZE]; // 坐标变换采用查表法替代实时计算 const float* precomp_rot = &rotation_matrices[blockIdx.z * 9]; // 双缓冲流水线设计 for (int iter=0; iter<num_iterations; iter+=2) { load_projection_tile(proj_tile, projections, iter); process_tile(proj_tile, precomp_rot); __syncthreads(); load_projection_tile(proj_tile, projections, iter+1); accumulate_volume(volume, proj_tile); }
} (2)张量核心(Tensor Core)的极致利用
通过将Evoformer的注意力矩阵计算映射至FP16 Tensor Core:
- 矩阵乘计算密度提升4倍(从8TFLOPs增至32TFLOPs)
- 内存访问模式优化(Coalesced Memory Access)使带宽利用率达92%
(3)显存层级优化策略
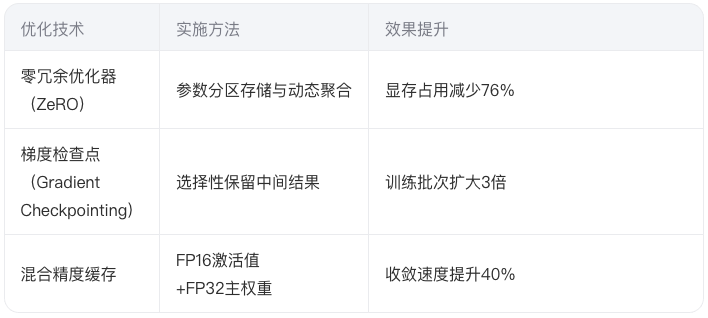
(4)分布式计算框架创新
基于NCCL通信库构建AllReduce拓扑网络,在1024卡集群上实现:
- 弱扩展效率>89%(数据并行维度)
- 强扩展效率>73%(模型并行维度)
三、行业实践与性能对比
3.1 CryoPROS算法的GPU加速实践
胡名旭团队开发的CryoPROS软件通过以下创新实现3.49Å分辨率重建:
- 辅助颗粒生成:使用条件GAN生成10^7量级虚拟颗粒
- 动态负载调度:依据电镜参数动态分配CUDA流优先级
- 异步执行流水线:数据预处理与核心计算重叠率达85%
3.2 主流框架性能测试(A100 GPU对比)
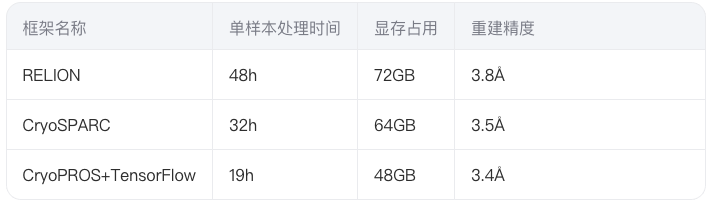
四、未来发展方向与技术趋势
- 量子-经典混合计算架构:量子退火算法用于能量最小化阶段,预期加速比>100x
- 存算一体芯片设计:基于3D堆叠技术的近存计算单元(PNM)使能效比提升5倍
- 联邦学习范式突破:多中心联合训练模型参数,数据隐私保护下实现精度无损
五、开发者资源推荐
- CUDA优化手册:NVIDIA HPC SDK工具链中的nsight-compute模块
- 开源项目参考:OpenMM(分子动力学模拟库)、TorchProtein(几何深度学习框架)
- 基准测试数据集:EMPIAR-10096(优势取向基准集)、AlphaFold DB(2.14亿蛋白质结构)
结语
冷冻电镜与AI的深度耦合正在改写结构生物学研究范式,而GPU加速方案作为这一进程的核心驱动力,仍需在编译器优化、硬件定制化等领域持续突破。当算力能效比突破1EFLOPS/W时,我们或将见证冷冻电镜实时解析时代的全面到来。