💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。

推荐:Linux运维老纪的首页,持续学习,不断总结,共同进步,活到老学到老
导航剑指大厂系列:全面总结 运维核心技术:系统基础、数据库、网路技术、系统安全、自动化运维、容器技术、监控工具、脚本编程、云服务等。
常用运维工具系列:常用的运维开发工具, zabbix、nagios、docker、k8s、puppet、ansible等
数据库系列:详细总结了常用数据库 mysql、Redis、MongoDB、oracle 技术点,以及工作中遇到的 mysql 问题等
懒人运维系列:总结好用的命令,解放双手不香吗?能用一个命令完成绝不用两个操作
数据结构与算法系列:总结数据结构和算法,不同类型针对性训练,提升编程思维,剑指大厂
非常期待和您一起在这个小小的网络世界里共同探索、学习和成长。💝💝💝 ✨✨ 欢迎订阅本专栏 ✨✨
案例:Kubernetes 集群
问题定位与分析
技能目标:
-
了解 Java8 不同子版本对 Docker 的支持
-
掌握 Java8 不同子版本在 Docker 中如何使用
堆资源
-
了解 Etcd 集群架构及部署
-
掌握 Etcd 集群扩容的正确操作案例一:K8S 运行 Java 程序堆内存分配详解
10.1 案例分析
10.1.1 案例概述
在 Docker 容器中运行 Java 程序,如果对内存及 CPU 资源不做任何限制,默认获取到
的是整个宿主机的内存及 CPU 资源。如果容器内 Java 程序出现异常,占用内存过多,可
能会导致应用无法正常访问,严重的会出现 OOM 现象。本章通过在 K8S 内运行不同版本
的 Java 程序,根据配置的不同呈现出不同的结果,使广大读者在实际的工作、学习中能够
避免出现此类问题。
10.1.2 案例前置知识点
1.JVM 内存结构
JVM 程序在运行时需要申请内存空间,申请到的内存空间又可以进行进一步的划分,
总共划分为 5 个部分:程序计数器(Program Counter Register)、Java 栈(VM Stack)、
本地方法栈(Native Method Stack)、方法区(Method Area)、堆(Heap)。如图 10.1
所示。 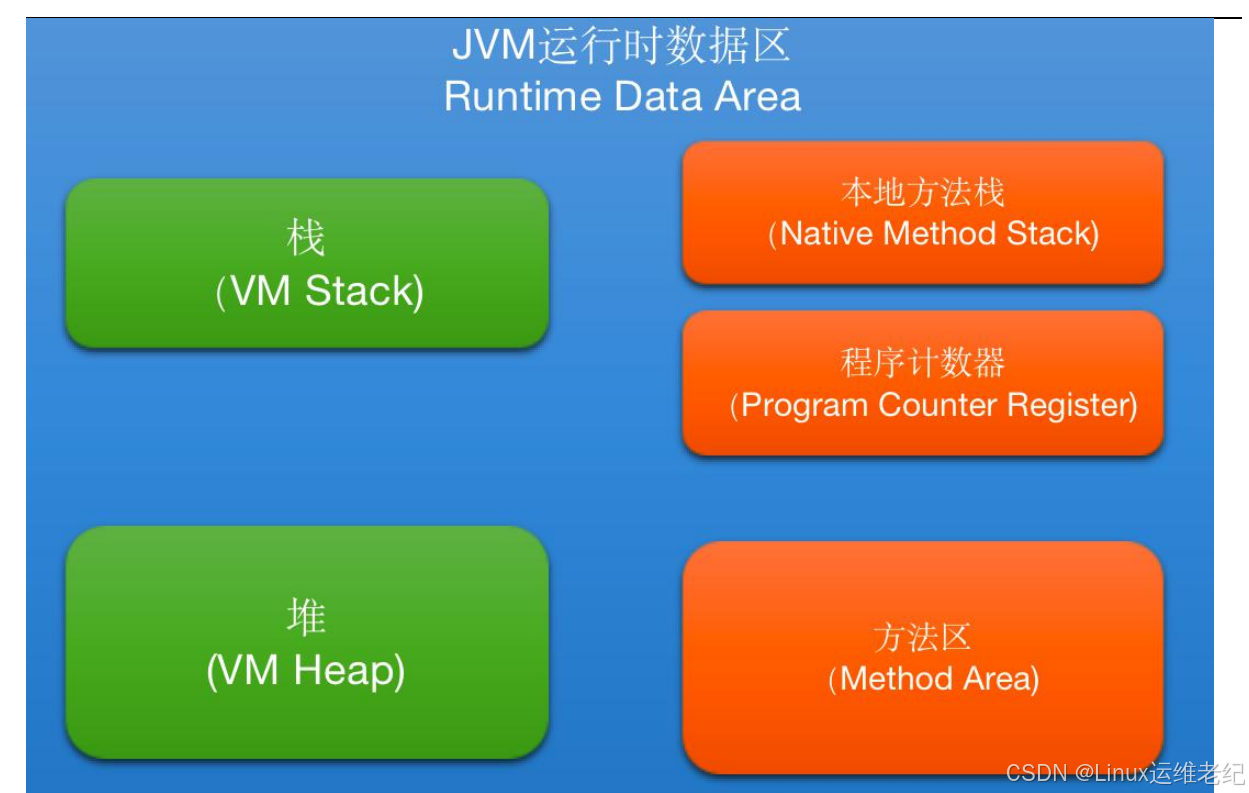
图 10.1 JVM 内存数据区
堆:存储着数组和对象,通过 Java 的 new 关键字创建的对象都存储在堆中,堆中存放
的都是实体(对象)。Java 的垃圾回收机制会自动释放不用的堆空间。堆是所有线程
共享的,在 JVM 中只有一个堆。
方法区:方法区与堆有很多共性,比如线程共享、内存不连续、可扩展、可垃圾回收。
同样,当无法再扩展时会抛出 OutOfMemoryError 异常。通常 Java 虚拟机规范把方法
区描述为堆的一个逻辑部分,但实际上是与 Java 堆分开的(Non-Heap)两个概念。
方法区存储的是已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码
等数据。
程序计数器:它占用内存较小,没有 OutOfMemoryError 异常区域。程序计数器的作用
可以看做是当前线程所执行的字节码的行号指示器,字节码解释器工作时就是通过改变
计数器的值来选取下一条字节码指令。其中,分支、循环、跳转、异常处理、线程恢复
等基础功能都需要依赖计数器来完成。
Java 栈:一个栈帧随着一个方法的调用开始而创建,这个方法调用完成而销毁。栈帧
内存存放着方法中的局部变量,操作数栈等数据。Java 栈也被称作虚拟机栈(Java
Vitual Machine Stack),JVM 栈只对栈帧进行存储、压栈和出栈操作。Java 栈是 Java
方法执行的内存模型。
本地方法栈:本地方法栈(Native Method Stacks)与虚拟机栈作用相似,也会抛出
StackOverflowError 和 OutOfMemoryError 异常。区别在于虚拟机栈为虚拟机执行 Java
方法(字节码)服务,而本地方法栈是为虚拟机使用到的 Native 方法服务。
2.JVM 内存设置参数
对于运行中的 Java 程序需要设置堆内存及栈内存大小,使用到的主要参数如下:
-Xms:JVM 分配的初始堆内存大小,默认为物理内存的 1/64。
-Xmx:JVM 分配的最大堆内存大小,默认为物理内存的 1/4。
10.1.3 案例环境
1. 案例环境
本案例环境如下表所示:
表 10-1 案例环境
主机名
配置
操作系统
IP 地址
K8S 版本
k8s
2 个 CPU、8G 内存
CentOS 7.3 x86_64
192.168.8.3
v1.18.4
本章 K8S 环境采用单台 kubeadm 方式部署。
2. 案例需求
(1)完成 K8S 部署;
(2)在 K8S 上验证 Java 程序不同版本及参数配置内存分配情况。
3. 案例实现思路
(1)安装 Docker;
(2)安装 K8S;
(3)验证 8u-181 版本不设置参数时内存分配情况;
(4)验证 8u-212 版本不设置参数时内存分配情况;
(5)验证 8u-181 版本设置参数时内存分配情况。
10.2 案例实施
10.2.1 环境准备
在开始实验之前,需要对虚拟机“k8s”进行相应的初始化操作。同时,需要提前下载好
实验用到的源码程序。
1. 初始化实验环境
初始化操作包括:安装基础软件包、关闭 SELinux、关闭防火墙、关闭 Swap 交换分区。[root@localhost ~]# hostnamectl set-hostname k8s
[root@localhost ~]# bash
[root@k8s ~]# yum -y install vim net-tools wget lrzsz git
[root@k8s ~]# sed -i '/^SELINUX=/s/enforcing/disabled/' /etc/selinux/config
[root@k8s ~]# setenforce 0
[root@k8s ~]# systemctl stop firewalld
[root@k8s ~]# systemctl disable firewalld
[root@k8s ~]# git version
git version 1.8.3.1
[root@k8s ~]# swapoff -a
[root@k8s ~]# sed -i '/swap/s/^/#/' /etc/fstab
2. 下载案例所需的代码
本章使用 k8s_sample 作为测试代码,需先下载到本地。下载过程如下所示。
[root@k8s ~]# git clone https://github.com/chaikebin/k8s_samples.git
Cloning into 'k8s_samples'...
remote: Enumerating objects: 89, done.
remote: Counting objects: 100% (89/89), done.
remote: Compressing objects: 100% (46/46), done.
remote: Total 89 (delta 21), reused 85 (delta 17), pack-reused 0
Unpacking objects: 100% (89/89), done.
若“git clone”下载失败,请检查网络连接情况并重新下载。
10.2.2 部署 K8S
实验需要 K8S 环境支持,所以要安装 Docker 及 K8S 相关内容。
1. 安装 Docker 服务
K8S 依托于 Docker 容器技术,要想实现 K8S 环境下故障排查,Docker 的安装是必不
可少的,其安装步骤如下所示。
[root@k8s ~]# yum install -y yum-utils device-mapper-persistent-data lvm2
[root@k8s
~]#
yum-config-manager
--add-repo
https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
[root@k8s ~]# yum makecache fast
[root@k8s ~]# yum -y install docker-ce
[root@k8s ~]# mkdir /etc/docker
[root@k8s ~]# cat << EOF >> /etc/docker/daemon.json
{
"registry-mirrors": [
"https://dockerhub.azk8s.cn",
"https://hub-mirror.c.163.com"
]
}
EOF
[root@k8s ~]# systemctl start docker && systemctl enable docker
如果在 Docker 使用过程中出现如下警告信息:
WARNING: bridge-nf-call-iptables is disabled
WARNING: bridge-nf-call-ip6tables is disabled
请添加如下内核配置参数以启用这些功能。
[root@k8s ~]# tee -a /etc/sysctl.conf <<-EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
[root@k8s ~]# sysctl -p
2. 安装 K8S
K8S 的虚拟机环境可参考本章案例环境,K8S 的安装采用 Kubeadm 单节点方式部署。
具体操作如下所示。
[root@k8s ~]# cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg
https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
[root@k8s ~]# yum install -y kubelet kubeadm kubectl
[root@k8s ~]# systemctl enable kubelet
[root@k8s ~]# kubeadm config print init-defaults > init-config.yaml
W0620 13:02:55.920463
13131 configset.go:202] WARNING: kubeadm cannot validate
component configs for API groups [kubelet.config.k8s.io kubeproxy.config.k8s.io]
[root@k8s ~]# vim init-config.yaml
apiVersion: kubeadm.k8s.io/v1beta2
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 192.168.8.3
bindPort: 6443
nodeRegistration:
criSocket: /var/run/dockershim.sock
name: k8s
taints:
- effect: NoSchedule
key: node-role.kubernetes.io/master
---
apiServer:
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta2
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controllerManager: {}
dns:
type: CoreDNS
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: registry.aliyuncs.com/google_containers
kind: ClusterConfiguration
kubernetesVersion: v1.18.0
networking:
dnsDomain: cluster.local
serviceSubnet: 10.96.0.0/12
podSubnet: 10.244.0.0/16
scheduler: {}
[root@k8s ~]# kubeadm config images list --config init-config.yaml
W0624 12:47:43.145643
3478 configset.go:202] WARNING: kubeadm cannot validate
component configs for API groups [kubelet.config.k8s.io kubeproxy.config.k8s.io]
registry.aliyuncs.com/google_containers/kube-apiserver:v1.18.0
registry.aliyuncs.com/google_containers/kube-controller-manager:v1.18.0第 9 页 共 41 页
registry.aliyuncs.com/google_containers/kube-scheduler:v1.18.0
registry.aliyuncs.com/google_containers/kube-proxy:v1.18.0
registry.aliyuncs.com/google_containers/pause:3.2
registry.aliyuncs.com/google_containers/etcd:3.4.3-0
registry.aliyuncs.com/google_containers/coredns:1.6.7
[root@k8s ~]# kubeadm config images pull --config=init-config.yaml
W0624 12:47:52.643822
3484 configset.go:202] WARNING: kubeadm cannot validate
component configs for API groups [kubelet.config.k8s.io kubeproxy.config.k8s.io]
[config/images] Pulled registry.aliyuncs.com/google_containers/kube-apiserver:v1.18.0
[config/images] Pulled registry.aliyuncs.com/google_containers/kube-controller-manager:v1.18.0
[config/images] Pulled registry.aliyuncs.com/google_containers/kube-scheduler:v1.18.0
[config/images] Pulled registry.aliyuncs.com/google_containers/kube-proxy:v1.18.0
[config/images] Pulled registry.aliyuncs.com/google_containers/pause:3.2
[config/images] Pulled registry.aliyuncs.com/google_containers/etcd:3.4.3-0
[config/images] Pulled registry.aliyuncs.com/google_containers/coredns:1.6.7
[root@k8s ~]# docker image ls
REPOSITORY
TAG
IMAGE ID
CREATED
SIZE
registry.aliyuncs.com/google_containers/kube-proxy
v1.18.0
43940c34f24f
3 months ago
117MB
registry.aliyuncs.com/google_containers/kube-apiserver
v1.18.0
74060cea7f70
3 months ago
173MB
registry.aliyuncs.com/google_containers/kube-controller-manager
v1.18.0
d3e55153f52f
3 months ago
162MB
registry.aliyuncs.com/google_containers/kube-scheduler
v1.18.0
a31f78c7c8ce
3 months ago
95.3MB
registry.aliyuncs.com/google_containers/pause
3.2
80d28bedfe5d
4 months ago
683kB
registry.aliyuncs.com/google_containers/coredns
1.6.7
67da37a9a360
4 months ago
43.8MB
registry.aliyuncs.com/google_containers/etcd
3.4.3-0
303ce5db0e90
8 months ago
288MB
[root@k8s ~]# kubeadm init --config=init-config.yaml
//初始化操作
//省略部分内容
[bootstrap-token] Using token: ymfx0p.b48y7o87ycjo7r38
[bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles
[bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to get nodes
[bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for
nodes to get long term certificate credentials
[bootstrap-token] configured RBAC rules to allow the csrapprover controller automatically approve
CSRs from a Node Bootstrap Token
[bootstrap-token] configured RBAC rules to allow certificate rotation for all node client certificates in
the cluster
[bootstrap-token] Creating the "cluster-info" ConfigMap in the "kube-public" namespace[kubelet-finalize] Updating "/etc/kubernetes/kubelet.conf" to point to a rotatable kubelet client
certificate and key
[addons] Applied essential addon: CoreDNS
[addons] Applied essential addon: kube-proxy
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.8.3:6443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash
sha256:3429bb511f8f3b4d7eca2b352ef6e6afb77c803d899cddebbe333e4706ec96a9
[root@k8s ~]# mkdir -p $HOME/.kube
[root@k8s ~]# cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[root@k8s ~]# chown $(id -u):$(id -g) $HOME/.kube/config
[root@k8s ~]# kubectl get nodes
NAME
STATUS
ROLES
AGE
VERSION
localhost.localdomain
NotReady
master
93s
v1.18.4
[root@k8s ~]# wget https://raw.githubusercontent.com/coreos/flannel/master/Documentatio
n/kube-flannel.yml
[root@k8s ~]# sed -i 's@quay.io@quay-mirror.qiniu.com@g' kube-flannel.yml
[root@k8s ~]# kubectl apply -f kube-flannel.yml
podsecuritypolicy.policy/psp.flannel.unprivileged created
clusterrole.rbac.authorization.k8s.io/flannel created
clusterrolebinding.rbac.authorization.k8s.io/flannel created
serviceaccount/flannel created
configmap/kube-flannel-cfg created
daemonset.apps/kube-flannel-ds-amd64 created
daemonset.apps/kube-flannel-ds-arm64 created
daemonset.apps/kube-flannel-ds-arm created
daemonset.apps/kube-flannel-ds-ppc64le created
daemonset.apps/kube-flannel-ds-s390x created
[root@k8s ~]# kubectl get nodes -o wide
NAME
STATUS
ROLES
AGE
VERSION
INTERNAL-IP
EXTE
RNAL-IP
OS-IMAGE
KERNEL-VERSION
CONTAINER-RUNTIME
localhost.localdomain
Ready
master
21m
v1.18.4
192.168.8.4
<none>
C
entOS Linux 7 (Core)
3.10.0-514.el7.x86_64
docker://19.3.8
[root@k8s ~]# kubectl get pods -o wide -n kube-system
NAME
READY
STATUS
RESTARTS
AGE
IP
NODE
NOMINATED NODE
READINESS
GATES
coredns-66bff467f8-98bh2
1/1
Running
0
21m
10.244.0.2
localhost.localdomain
<none>
<none>
coredns-66bff467f8-trl46
1/1
Running
0
21m
10.244.0.3
localhost.localdomain
<none>
<none>
etcd-localhost.localdomain
1/1
Running
0
21m
192.168.8.3
localhost.localdomain
<none>
<none>
kube-apiserver-localhost.localdomain
1/1
Running
0
21m
192.168.8.3
localhost.localdomain
<none>
<none>
kube-controller-manager-localhost.localdomain
1/1
Running
0
21m
192.168.8.3
localhost.localdomain
<none>
<none>
kube-flannel-ds-amd64-frkwk
1/1
Running
0
118s
192.168.8.3
localhost.localdomain
<none>
<none>
kube-proxy-dttp7
1/1
Running
0
21m
192.168.8.3
localhost.localdomain
<none>
<none>
kube-scheduler-localhost.localdomain
1/1
Running
0
21m
192.168.8.3
localhost.localdomain
<none>
<none>
[root@k8s ~]# kubectl taint nodes --all node-role.kubernetes.io/master-
//将 Pod 调 度 到
master 节点
node/k8s untainted
10.2.3 Java 不同版本、参数内存分配
1. 8u-181 版本,不设置-Xms、-Xmx 参数
JDK8u-181 版本是不支持 Docker 容器的。在这个版本的容器中运行 Java 程序,如果
没有设置-Xms 和-Xmx 时,Java 默认将初始堆内存设置为虚拟机内存的 1/64,最大堆内存
设置为虚拟机内存的 1/4。如果在创建的时候设置了 limits 为 512M,当 Java 使用的内存大
于 512M 时,就会导致 cgroup 将 Java 程序 killed 掉。
(1)确认 8u181-jre 目录内文件
[root@k8s 8u181-jre]# pwd
/root/k8s_samples/sample1/yaml/8u181-jre
[root@k8s 8u181-jre]# ls -l
total 8
-rw-r--r-- 1 root root 145 May 9 15:41 Dockerfile
-rw-r--r-- 1 root root 709 May 9 15:41 sample1.yaml
(2)查看 sample1.yaml 文件内容
[root@k8s 8u181-jre]# cat sample1.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: sample1-8u181
labels:
app: sample1-8u181
spec:
replicas: 1
selector:
matchLabels:
app: sample1-8u181
template:
metadata:
labels:
app: sample1-8u181
spec:
containers:
- name: sample1-8u181
image: registry.cn-hangzhou.aliyuncs.com/k8s_samples/sample1:8u181-jre //镜像拉取地
址
command: ["java"]
args:
["-XX:+UseParallelGC","-XX:+PrintFlagsFinal","-XX:+PrintGCDetails","-jar",
"/sample1.jar"]
//启动参数
ports:
- containerPort: 21001
resources:
//资源限制相关配置参数
requests:
cpu: 500m
memory: 512Mi
limits:
cpu: 500m
memory: 512Mi
(3)运行 kubectl create -f sample1.yaml 创建 Pod
[root@k8s 8u181-jre]# kubectl create -f sample1.yaml
deployment.apps/sample1-8u181 created
[root@k8s 8u181-jre]# kubectl get pods -o wide
//需要等待一会才能创建成功
NAME
READY
STATUS
RESTARTS
AGE
IP
NODE
NOMINATED NODE
READINESS GATES
sample1-8u181-5b56f966bb-g7l6c
1/1
Running
0
4m19s
10.244.0.10
localhost.localdomain
<none>
<none>
(4)查看 Pod 日志过滤堆内存大小
[root@k8s 8u181-jre]# kubectl logs sample1-8u181-5b56f966bb-g7l6c | grep HeapSize
uintx ErgoHeapSizeLimit
= 0
{product}
uintx HeapSizePerGCThread
= 87241520
{product}
uintx InitialHeapSize
:= 132120576
{product}
uintx LargePageHeapSizeThreshold
= 134217728
{product}
uintx MaxHeapSize
:= 2088763392
{product}
可以看到 InitialHeapSize 的值是 132120576,连续除两个 1024 之后为 126M,约为虚
拟机内存 8G 的 1/64。MaxHeapSize 的值为 2088763392,可换算为 1992M,约为虚拟机
内存大小的 1/4,并没有受容器 limit 大小的限制。
(5)模拟 JVM 内存溢出
[root@k8s 8u181-jre]# kubectl get pods -o wide
NAME
READY
STATUS
RESTARTS
AGE
IP
NODE
NOMINATED NODE
READINESS GATES
sample1-8u181-5b56f966bb-g7l6c
1/1
Running
0
4m19s
10.244.0.10
localhost.localdomain
<none>
<none>
[root@k8s 8u181-jre]# curl 10.244.0.10:21001/oom
//通过上面命令查到 pod 的 IP 地址
curl: (52) Empty reply from server
[root@k8s 8u181-jre]# kubectl get pods -o wide
NAME
READY
STATUS
RESTARTS
AGE
IP
NODE
NOMINATED NODE
READINESS GATES
sample1-8u181-5b56f966bb-g7l6c
1/1
Running
1
29m
10.244.0.10
localhost.localdomain
<none>
<none>
通过 curl 命令的执行,模拟 JVM 内存溢出,溢出后重启了 Pod,此时“kubectl get pod”
结果的“RESTARTS”值已经变为 1,说明 Pod 已经被重启了一次。
(6)检查 OOM 相关日志
[root@k8s 8u181-jre]# kubectl describe pod sample1-8u181-5b56f966bb-g7l6cNAME
Name:
sample1-8u181-5b56f966bb-g7l6c
Namespace:
default
Priority:
0
Node:
localhost.localdomain/192.168.8.3
Start Time:
Sun, 10 May 2020 21:09:25 +0800
Labels:
app=sample1-8u181
pod-template-hash=5b56f966bb
//省略了部分内容
State:
Running
Started:
Sun, 10 May 2020 21:38:48 +0800
Last State:
Terminated
Reason:
OOMKilled
Exit Code:
137
Started:
Sun, 10 May 2020 21:09:59 +0800
Finished:
Sun, 10 May 2020 21:38:47 +0800
Ready:
True
Restart Count: 1
Limits:
cpu:
500m
memory: 512Mi
//省略了部分内容
通过以上日志信息看到此 POD 的 Last State 为 OOMKilled,表示此 POD 已经 OOM,
已被 K8S 杀掉。
2. 8u-212 版本,不设置-Xms、-Xmx 参数
JDK8u-212 版本之后,Java 已经支持 Docker。在容器中运行 Java 程序,如果没有设
置-Xms 和-Xmx 时,Java 默认将初始堆内存设置为容器内存的 1/64,最大堆内存设置为容
器内存的 1/4,模拟 Java OOM,但由于最大堆内存没有超过 Docker 的 limit,所以 Java
容器不会被 cgroup 杀掉。
(1)确认 8u212-jre 目录内文件
[root@k8s 8u212-jre]# pwd
/root/k8s_samples/sample1/yaml/8u212-jre
[root@k8s 8u212-jre]# ls -l
total 8
-rw-r--r-- 1 root root 145 May 9 15:41 Dockerfile
-rw-r--r-- 1 root root 709 May 9 15:41 sample1.yaml
(2)查看 sample1.yaml 文件内容
[root@k8s 8u212-jre]# cat sample1.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: sample1-8u212
labels:
app: sample1-8u212
spec:
replicas: 1
selector:
matchLabels:
app: sample1-8u212
template:
metadata:
labels:
app: sample1-8u212
spec:
containers:
- name: sample1-8u212
image: registry.cn-hangzhou.aliyuncs.com/k8s_samples/sample1:8u212-jre
command: ["java"]
args:
["-XX:+UseParallelGC","-XX:+PrintFlagsFinal","-XX:+PrintGCDetails","-jar",
"/sample1.jar"]
ports:
- containerPort: 21001
resources:
requests:
cpu: 500m
memory: 512Mi
limits:
cpu: 1000m
memory: 512Mi
(3)运行 kubectl create -f sample1.yaml 创建容器
[root@k8s 8u212-jre]# kubectl create -f sample1.yaml
deployment.apps/sample1-8u212 created
[root@k8s 8u212-jre]# kubectl get pods -o wide
NAME
READY
STATUS
RESTARTS
AGE
IP
NODE
NOMINATED NODE
READINESS GATES
sample1-8u181-5b56f966bb-g7l6c
1/1
Running
1
78m
10.244.0.10
localhost.localdomain
<none>
<none>
sample1-8u212-b58496676-4zv5f
1/1
Running
0
7m48s
10.244.0.11
localhost.localdomain
<none>
<none>
(4)查看 Pod 日志过滤堆内存大小
[root@k8s 8u212-jre]# kubectl logs sample1-8u212-b58496676-4zv5f | grep HeapSize
uintx ErgoHeapSizeLimit
= 0
{product}
uintx HeapSizePerGCThread
= 87241520
{product}
uintx InitialHeapSize
:= 8388608
{product}
uintx LargePageHeapSizeThreshold
= 134217728
{product}
uintx MaxHeapSize
:= 134217728
{product}
可以看到 InitialHeapSize 的值是 8388608,可换算为 8M,是启动的容器内存 512M 的
1/64。MaxHeapSize 的值为 134217728,可换算为 128M,是启动的容器内存 512M 的 1/4,
并没有受容器 limit 大小的限制。
(5)模拟 JVM 内存溢出
[root@k8s 8u212-jre]# kubectl get pods -o wide
NAME
READY
STATUS
RESTARTS
AGE
IP
NODE
NOMINATED NODE
READINESS GATES
sample1-8u181-5b56f966bb-g7l6c
1/1
Running
1
78m
10.244.0.10
localhost.localdomain
<none>
<none>
sample1-8u212-b58496676-4zv5f
1/1
Running
0
7m48s
10.244.0.11
localhost.localdomain
<none>
<none>
[root@k8s 8u212-jre]# curl 10.244.0.11:21001/oom
{"timestamp":"2020-05-10T14:38:53.958+0000","status":500,"error":"Internal
Server
Error","message":"Java heap space","path":"/oom"}
[root@k8s 8u212-jre]# kubectl get pods -o wide
NAME
READY
STATUS
RESTARTS
AGE
IP
NODE
NOMINATED NODE
READINESS GATES
sample1-8u181-5b56f966bb-g7l6c
1/1
Running
1
89m
10.244.0.10
localhost.localdomain
<none>
<none>
sample1-8u212-b58496676-4zv5f
1/1
Running
0
19m
10.244.0.11
localhost.localdomain
<none>
<none>
模拟执行了 JVM 命令后,“RESTARTS”值未发生变化,说明 Pod 未被 K8S 杀掉。
(6)检查 OOM 相关日志
[root@k8s 8u212-jre]# kubectl describe pod sample1-8u212-b58496676-4zv5f
//省略部分内容
State:
Running
Started:
Sun, 10 May 2020 22:20:27 +0800
Ready:
True
Restart Count: 0
//省略部分内容
此时 Pod 的 State 为 Running,Restart Count 为 0,K8S 并未杀掉该 Pod。
(7)查看容器占用内存情况
[root@k8s 8u212-jre]# docker ps -a | grep k8s_sample1-8u212*
cc90dcdc062f
registry.cn-hangzhou.aliyuncs.com/k8s_samples/sample1
"java
-XX:+UseParall…"
8
minutes
ago
Up
8
minutes
k8s_sample1-8u212_sample1-8u212-b58496676-4zv5f_default_e090aab3-d338-4df8-b1ba-90
7071ecdc3f_0
[root@k8s
8u212-jre]#
docker
stats
--no-stream
k8s_sample1-8u212_sample1-8u212-b58496676-4zv5f_default_e090aab3-d338-4df8-b1ba-90
7071ecdc3f_0
CONTAINER
ID
NAME
CPU %
MEM USAGE / LIMIT
MEM %
NET I/O
BLOCK I/O
PIDS
5eb73bba9126
k8s_sample1-8u212_sample1-8u212-b58496676-4zv5f_default_e090aab3-d338-4df8-b1ba-90707
1ecdc3f_0
0.47%
226.6MiB / 512MiB
44.26%
0B / 0B
0B / 0B
29
通过 docker stats 命令可查看容器此时占用内存约为 226M,占分配上线的 44.26%。
3. 8u-181 版本,设置-Xms、-Xmx 参数
JDK8u-181 版本是不支持 Docker 的,在这个版本的容器中运行 Java 程序,设置了-Xms
和-Xmx 时,Java 将使用设置好的值进行堆内存的分配,设置的最大值未超过容器的 limit
设置,Pod 将不会被 K8S 杀掉,JVM 将会出现 OutOfMemoryError。
(1)确认 8u181-jre 目录内文件
[root@k8s 8u181-jre]# pwd
/root/k8s_samples/sample1/yaml/8u181-jre
[root@k8s 8u181-jre]# ls -l
total 8
-rw-r--r-- 1 root root 145 May 9 15:41 Dockerfile
-rw-r--r-- 1 root root 709 May 9 15:41 sample1.yaml
(2)修改 sample1.yaml 文件内容
[root@k8s 8u181-jre]# vim sample1.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: sample1-8u181
labels:
app: sample1-8u181
spec:
replicas: 1
matchLabels:
app: sample1-8u181
template:
metadata:
labels:
app: sample1-8u181
spec:
containers:
- name: sample1-8u181
image: registry.cn-hangzhou.aliyuncs.com/k8s_samples/sample1:8u181-jre //镜像拉取地
址
command: ["java"]
args:
["-Xms8m",
"-Xmx128m",
"-XX:+UseParallelGC","-XX:+PrintFlagsFinal","-XX:+PrintGCDetails","-jar", "/sample1.jar"]
//
增加-Xms8m -Xmx128m
ports:
- containerPort: 21001
resources:
requests:
cpu: 500m
memory: 512Mi
limits:
cpu: 500m
memory: 512Mi
(3)运行 kubectl create -f sample1.yaml 创建容器
[root@k8s 8u181-jre]# kubectl delete -f sample1.yaml
deployment.apps "sample1-8u181" deleted
[root@k8s 8u181-jre]# kubectl create -f sample1.yaml
deployment.apps/sample1-8u181 created
[root@k8s ~]# kubectl get pods -o wide
NAME
READY
STATUS
RESTARTS
AGE
IP
NODE
NOMINATED NODE
READINESS GATES
sample1-8u181-848fb877d4-7p7vc
1/1
Running
0
7s
10.244.0.13
localhost.localdomain
<none>
<none>
sample1-8u212-b58496676-4zv5f
1/1
Running
0
51m
10.244.0.11
localhost.localdomain
<none>
<none>
(4)查看 Pod 日志过滤堆内存大小
[root@k8s ~]# kubectl logs sample1-8u181-848fb877d4-7p7vc | grep HeapSize
uintx ErgoHeapSizeLimit
= 0
{product}
uintx HeapSizePerGCThread
= 87241520
{product}
uintx InitialHeapSize
:= 8388608
{product}
uintx LargePageHeapSizeThreshold
= 134217728
{product}
uintx MaxHeapSize
:= 134217728
{product}
可以看到 InitialHeapSize 的值为 8M,MaxHeapSize 的值为 128M,与配置内设置的一
样。
(5)模拟 JVM 内存溢出
[root@k8s ~]# kubectl get pods -o wide
NAME
READY
STATUS
RESTARTS
AGE
IP
NODE
NOMINATED NODE
READINESS GATES
sample1-8u181-848fb877d4-7p7vc
1/1
Running
0
7s
10.244.0.13
localhost.localdomain
<none>
<none>
sample1-8u212-b58496676-4zv5f
1/1
Running
0
51m
10.244.0.11
localhost.localdomain
<none>
<none>
[root@k8s ~]# curl 10.244.0.13:21001/oom
{"timestamp":"2020-05-10T15:17:12.557+0000","status":500,"error":"Internal
Server
Error","message":"Java heap space","path":"/oom"}
[root@k8s ~]# kubectl get pods -o wide
NAME
READY
STATUS
RESTARTS
AGE
IP
NODE
NOMINATED NODE
READINESS GATES
sample1-8u181-848fb877d4-7p7vc
1/1
Running
0
5m28s
10.244.0.13
localhost.localdomain
<none>
<none>
sample1-8u212-b58496676-4zv5f
1/1
Running
0
57m
10.244.0.11
localhost.localdomain
<none>
<none>
通过 curl 命令模拟了 JVM 内存溢出,此时“kubectl get pod”结果的“RESTARTS”值保持
为 0,说明 Pod 并未被重启。
(6)检查 OOM 相关日志
[root@k8s ~]# kubectl describe pod sample1-sample1-8u181-848fb877d4-7p7vc
//省略了部分内容
State:
Running
Started:
Sun, 10 May 2020 23:11:56 +0800
Ready:
True
Restart Count: 0
//省略了部分内容
此时 Pod 的 State 为 Running,Restart Count 为 0,K8S 并未杀掉该 Pod。
(7)查看容器占用内存情况
[root@k8s ~]# docker ps -a | grep k8s_sample1-8u181*
08e8b827240d
a680a7287eab
"java
-Xms8m
-Xmx128…"
2
minutes
ago
Up
2
minutes
k8s_sample1-8u181_sample1-8u181-848fb877d4-7p7vc_default_f2ca8698-a94b-4135-b67c-29b8
6ec6ad47_0
[root@k8s
~]#
docker
stats
--no-stream
k8s_sample1-8u181_sample1-8u181-848fb877d4-7p7vc_default_f2ca8698-a94b-4135-b67c-2
9b86ec6ad47_0
CONTAINER
ID
NAME
CPU %
MEM USAGE / LIMIT
MEM %
NET I/O
BLOCK I/O
PIDS
40da97b20eb5
k8s_sample1-8u181_sample1-8u181-848fb877d4-7p7vc_default_f2ca8698-a94b-4135-b67c-29b8
6ec6ad47_0
0.36%
221.1MiB / 512MiB
43.18%
0B / 0B
0B / 0B
31
通过 docker stats 命令可查看容器此时占用内存约为 221M,占分配上限的 43.18%。
至此,在使用 Java 的过程中可得出结论:8u-181 及之前的版本在使用时要添加最大和
最小内存限制值,避免超过容器限定值,从而导致 OOM;8u-212 版本则不存在该问题。
案例二:二进制安装的 K8S 中 Etcd 扩容问题
10.3 案例分析
10.3.1 案例概述
Etcd 用于存储 K8S 集群共享配置以及服务发现,它是分布式的、一致性的 KV 存储系
统。在 K8S 的使用过程中,Etcd 由于负载、高可用等可能会出现无法满足当前需求的情况,
这个时候就需要扩容。常见的扩容方式有:从一台扩容到三台;从三台扩容到五台;从五台
扩容到七台。在 K8S 中,Etcd 在扩容的时候要考虑证书中 IP 是否包含新节点的 IP 地址,
没有则会导致新节点无法加入集群,要想成功加入集群,需要重新生成对应的证书。本章通
过介绍 Etcd 扩容的相关知识,希望帮助广大读者在实际工作中避免出现此类问题。
10.3.2 案例前置知识点
1. Etcd 简介
Etcd 是由 Go 语言编写而成的分布式、高可用的一致性键值(key-value)存储系统,
用于提供可靠的分布式键值存储、配置共享和服务发现等功能。Etcd 可以用于存储关键数
据和实现分布式调度,它在集群运行中能够起到关键性的作用。Etcd 基于 Raft 协议,通过
复制日志文件的方式来保证数据的强一致性。虽然 Etcd 是一个强一致性的系统,但也支持
从非 Leader 节点读取数据以提高性能。此外,Etcd 具有一定的容错能力,它能够有效地应
对网络分区和机器故障带来的数据丢失风险。
由以上可知,Etcd 具有如下特点:
简单:安装配置简单,而且提供了 HTTP API 进行交互,使用也很简单。
安全:支持 SSL 证书验证。
快速:根据官方提供的 benchmark 数据,单实例支持每秒 2k+读操作。
可靠:采用 Raft 算法,实现分布式系统数据的可用性和一致性。
2. Etcd 原理
Etcd 的架构原理如图 10.2 所示。 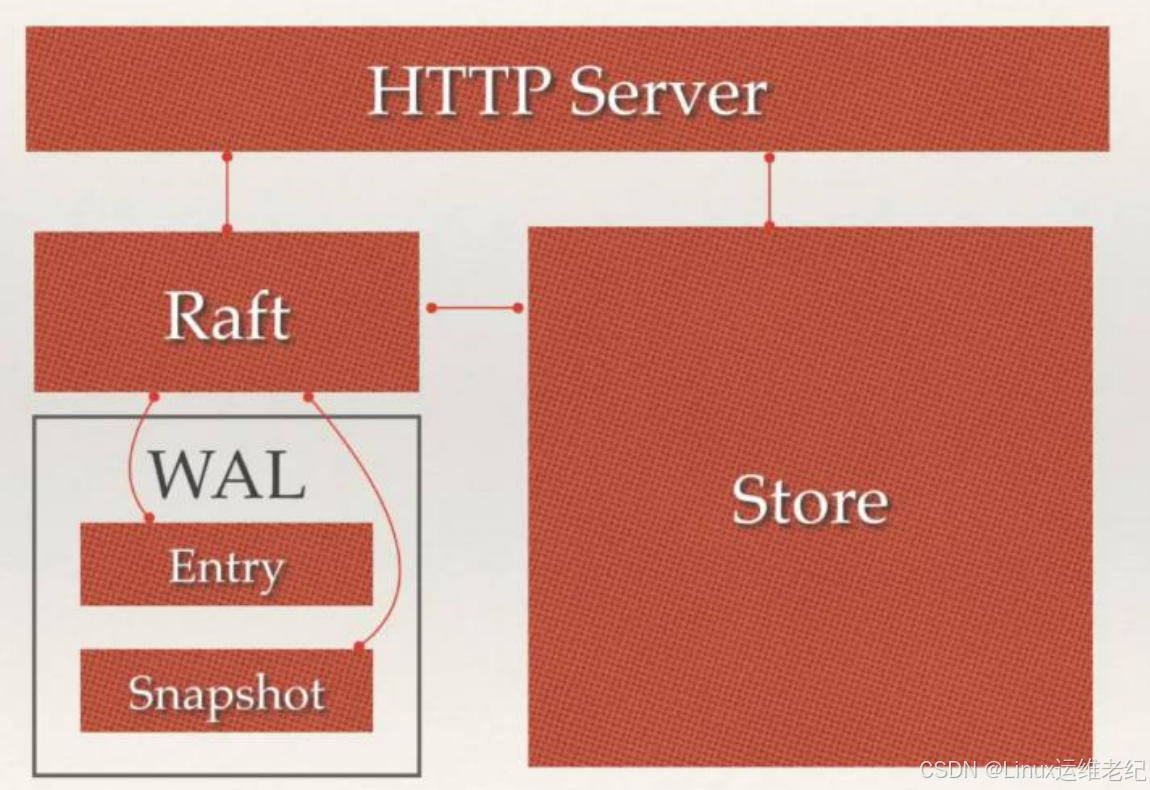
图 10.2 Etcd 原理架构图
Etcd 主要分为四个部分。
HTTP Server:用于处理用户发送的 API 请求以及其它 Etcd 节点的同步与心跳信息请
求。
Store:用于处理 Etcd 支持的各类功能事务,包括数据索引、节点状态变更、监控与反
馈、事件处理与执行等等,是 Etcd 对用户提供的大多数 API 功能的具体实现。
Raft:Raft 强一致性算法的具体实现,是 Etcd 的核心内容。
WAL:Write Ahead Log(预写式日志),是 Etcd 的数据存储方式。除了在内存中存有
所有数据的状态以及节点的索引以外,Etcd 就是通过 WAL 进行持久化存储。在 WAL
中,所有的数据提交之前都会事先记录日志。 其中 Snapshot 是为了防止数据过多而
进行的状态快照;Entry 表示存储的具体日志内容。
通常,用户的一个请求发送过来,会经由 HTTP Server 转发给 Store 进行具体的事务
第 25 页 共 41 页第 26 页 共 41 页
处理,如果涉及到节点的修改,则交给 Raft 模块进行状态的变更、日志的记录,然后再同
步给别的 Etcd 节点以确认数据是否一致,最后进行数据的提交,再次同步。
10.3.3 案例环境
1.本案例环境
本案例环境如表 10-2 所示。
表 10-2 案例环境
主机名
操作系统
IP 地址
安装软件
etcd01 CentOS 7.3 x86_64
192.168.9.107
Etcd
etcd02 CentOS 7.3 x86_64
192.168.9.108
Etcd
etcd03 CentOS 7.3 x86_64
192.168.9.109
Etcd
etcd04 CentOS 7.3 x86_64
192.168.9.110
Etcd
etcd05 CentOS 7.3 x86_64
192.168.9.111
Etcd
实验的拓扑图,如图 10.3 所示。 
图 10.3 实验拓扑
2.案例需求
本案例的需求如下:
(1)安装部署三台 Etcd 集群;
(2)另外两台 Etcd 主机通过扩容的方式加入集群。
3.案例实现思路
本案例的实现思路如下:
(1)对五台主机进行系统初始化配置;
(2)为 Etcd 集群签发证书;
(3)安装部署三台结构的 Etcd 集群;
(4)为 Etcd 集群扩容;
(5)验证扩容后集群状态。
10.4 案例实施
10.4.1 环境准备
1. 主机名设置
为五台主机分别设置主机名,具体操作如下所示。
[root@localhost ~]# hostnamectl set-hostname etcd01
//以 etcd01 为例
[root@localhost ~]# bash
[root@etcd01 ~]#
2. 关闭防火墙
为五台主机分别关闭防火墙,具体操作如下所示。
[root@etcd01 ~]# systemctl stop firewalld
//以 etcd01 为例
[root@etcd01 ~]# systemctl disable firewalld
3. 禁用 SELinux
[root@etcd01 ~]# sed -i '/^SELINUX=/s/enforcing/disabled/' /etc/selinux/config
[root@etcd01 ~]# setenforce 0
//以 etcd01 为例
4. 安装必备软件
[root@etcd01 ~]# yum -y install vim lrzsz net-tools wget
//以 etcd01 为例
10.4.2 为 Etcd 签发证书
Kubernetes 系统二进制方式安装后,各 Etcd 之间需要使用 TLS 证书对通信进行加密,
本实验使用 CloudFlare 的 PKI 工具集 CFSSL 来生成相关证书。
1. 生成 CA 证书
执行以下操作,创建证书存放位置并上传证书生成工具。在 Etcd01 节点上操作,生成
CA 证书。
[root@etcd01 ~]# mkdir /root/keys
[root@etcd01 ~]# cd /root/keys
//上传第 5 章二进制安装使用过的证书生成工具
[root@etcd01 keys]# chmod +x *
[root@etcd01 keys]# mv cfssl_linux-amd64 /usr/local/bin/cfssl
[root@etcd01 keys]# mv cfssljson_linux-amd64 /usr/local/bin/cfssljson
[root@etcd01 keys]# mv cfssl-certinfo_linux-amd64 /usr/local/bin/cfssl-certinfo
执行以下命令,拷贝证书生成脚本。
[root@etcd01 keys]# cat > ca-config.json <<EOF
{
"signing": {
"default": {
"expiry": "87600h"
},
"profiles": {
"kubernetes": {
"expiry": "87600h",
"usages": [
"signing",
"key encipherment",
"server auth",
"client auth"
]
}
}
}
}
EOF
[root@etcd01 keys]# cat > ca-csr.json <<EOF
{
"CN": "kubernetes",
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "Beijing",
"ST": "Beijing",
"O": "k8s",
"OU": "System"
}
]
}
EOF
执行以下操作,生成 CA 证书。
[root@etcd01 keys]# cfssl gencert -initca ca-csr.json | cfssljson -bare ca -
2020/06/21 10:51:27 [INFO] generating a new CA key and certificate from CSR
2020/06/21 10:51:27 [INFO] generate received request
2020/06/21 10:51:27 [INFO] received CSR
2020/06/21 10:51:27 [INFO] generating key: rsa-2048
2020/06/21 10:51:28 [INFO] encoded CSR
2020/06/21
10:51:28
[INFO]
signed
certificate
with
serial
number
628326064741337757488292270895082513392238194609第 30 页 共 41 页
2. 生成 Etcd 证书
拷贝 Etcd 证书生成文件,之后生成 Etcd 证书。在 Etcd01 节点上操作,生成 Etcd 证
书。
[root@etcd01 keys]# cat << EOF >etcd-csr.json
{
"CN": "etcd",
"hosts": [
"127.0.0.1",
"192.168.9.107",
"192.168.9.108",
"192.168.9.109"
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "Beijing",
"L": "Beijing",
"O": "etcd",
"OU": "etcd"
}
]
}
EOF
[root@etcd01 keys]# cfssl gencert -ca=ca.pem -ca-key=ca-key.pem
-config=ca-config.jso
n -profile=kubernetes etcd-csr.json | cfssljson -bare etcd
2020/06/21 10:53:51 [INFO] generate received request
2020/06/21 10:53:51 [INFO] received CSR
2020/06/21 10:53:51 [INFO] generating key: rsa-2048
2020/06/21 10:53:51 [INFO] encoded CSR
2020/06/21
10:53:51
[INFO]
signed
certificate
with
serial
number
241990889354121720024774931276683805396199439392
2020/06/21 10:53:51 [WARNING] This certificate lacks a "hosts" field. This makes it unsuitable for
websites. For more information see the Baseline Requirements for the Issuance and Managementof Publicly-Trusted Certificates, v.1.1.6, from the CA/Browser Forum (https://cabforum.org);
specifically, section 10.2.3 ("Information Requirements").
10.4.3 安装配置 Etcd
Etcd 集群的安装,采用先安装配置 Etcd01 节点,然后在将相关文件拷贝到其他节点的
方式。下列步骤如无特别说明,都是在 Etcd01 节点上操作。
1. 安装 Etcd
[root@etcd01 ~]# wget https://github.com/etcd-io/etcd/releases/download/v3.4.1/etcd-v3.4.1
-linux-amd64.tar.gz
[root@etcd01 ~]# tar xvf etcd-v3.4.1-linux-amd64.tar.gz
[root@etcd01 ~]# cd etcd-v3.4.1-linux-amd64
[root@etcd01 etcd-v3.4.1-linux-amd64]# mv etcd* /usr/local/bin/
[root@etcd01 etcd-v3.4.1-linux-amd64]# mkdir /etc/etcd /var/lib/etcd
[root@etcd01 etcd-v3.4.1-linux-amd64]# /bin/cp /root/keys/*.pem /etc/etcd/
2. 创建配置文件
[root@etcd01 ~]# vim /etc/etcd/etcd
NAME="etcd1"
INTERNAL_IP="192.168.9.107"
ETCD_SERVERS="etcd1=https://192.168.9.107:2380,etcd2=https://192.168.9.108:2380,etcd3=htt
ps://192.168.9.109:2380"
3. 创建 systemd 服务配置文件
[root@etcd01 ~]# vim /etc/systemd/system/etcd.service
[Unit]
Description=etcd
Documentation=https://github.com/coreos
[Service]
Type=notify
EnvironmentFile=-/etc/etcd/etcd
ExecStart=/usr/local/bin/etcd \
--name ${NAME} \
--cert-file=/etc/etcd/etcd.pem \
--key-file=/etc/etcd/etcd-key.pem \
--peer-cert-file=/etc/etcd/etcd.pem \
--peer-key-file=/etc/etcd/etcd-key.pem \
--trusted-ca-file=/etc/etcd/ca.pem \
--peer-trusted-ca-file=/etc/etcd/ca.pem \
--peer-client-cert-auth \
--client-cert-auth \
--initial-advertise-peer-urls https://${INTERNAL_IP}:2380 \
--listen-peer-urls https://${INTERNAL_IP}:2380 \
--listen-client-urls https://${INTERNAL_IP}:2379,https://127.0.0.1:2379 \
--advertise-client-urls https://${INTERNAL_IP}:2379 \
--initial-cluster-token etcd-cluster-0 \
--initial-cluster ${ETCD_SERVERS} \
--initial-cluster-state new \
--data-dir=/var/lib/etcd
Restart=on-failure
RestartSec=5
[Install]
WantedBy=multi-user.target
4. 拷贝文件到 Etcd02、Etcd03
[root@etcd02 ~]# mkdir /etc/etcd
//在 etcd02、etcd03 上创建目录
[root@etcd01 ~]# scp /etc/etcd/* 192.168.9.108:/etc/etcd/
//从 etcd01 上拷贝
[root@etcd01 ~]# scp /etc/etcd/* 192.168.9.109:/etc/etcd/
[root@etcd01 ~]# scp /etc/systemd/system/etcd.service 192.168.9.108:/etc/systemd/system/
[root@etcd01 ~]# scp /etc/systemd/system/etcd.service 192.168.9.109:/etc/systemd/system/
[root@etcd01 ~]# scp /usr/local/bin/etcd* 192.168.9.108:/usr/local/bin/
[root@etcd01 ~]# scp /usr/local/bin/etcd* 192.168.9.109:/usr/local/bin/
5. 修改 Etcd02、Etcd03 配置
[root@etcd02 ~]# vim /etc/etcd/etcd
//在 etcd02 上修改
NAME="etcd2"
INTERNAL_IP="192.168.9.108"
ETCD_SERVERS="etcd1=https://192.168.9.107:2380,etcd2=https://192.168.9.108:2380,etcd3=htt
ps://192.168.9.109:2380"
[root@etcd03 ~]# vim /etc/etcd/etcd
//在 etcd03 上修改
NAME="etcd3"
INTERNAL_IP="192.168.9.109"
ETCD_SERVERS="etcd1=https://192.168.9.107:2380,etcd2=https://192.168.9.108:2380,etcd3=htt
ps://192.168.9.109:2380"
6. 逐个启动 Etcd01、Etcd02、Etcd03
[root@etcd01 ~]# systemctl enable etcd
[root@etcd01 ~]# systemctl start etcd
//etcd01 上跟第 5 章类似,可能出现卡住情况,直
接 Ctrl+C 结束,etcd02、etcd03 上逐个启动
7. 查看 Etcd 集群状态
[root@etcd01 ~]# etcdctl --cacert=/etc/etcd/ca.pem --cert=/etc/etcd/etcd.pem --key=/etc/etc
d/etcd-key.pem --endpoints="https://192.168.9.107:2379,https://192.168.9.108:2379,https://19
2.168.9.109:2379" member list -w table
+------------------+---------+--------+----------------------------+----------------------------+------------+
|
ID
| STATUS | NAME |
PEER ADDRS
|
CLIENT
ADDRS
| IS LEARNER |
+------------------+---------+--------+----------------------------+----------------------------+------------+
| f054c04091dcaf8 | started | etcd1 | https://192.168.9.107:2380 | https://192.168.9.107:2379
|
false |
| c78ea993ce47312f | started | etcd3 | https://192.168.9.109:2380 | https://192.168.9.109:2379
|
false |
| f967889e726a5c34 | started | etcd2 | https://192.168.9.108:2380 | https://192.168.9.108:2379
|
false |
+------------------+---------+--------+----------------------------+----------------------------+------------+
[root@etcd01 ~]# etcdctl --cacert=/etc/etcd/ca.pem --cert=/etc/etcd/etcd.pem --key=/etc/etc
d/etcd-key.pem --endpoints="https://192.168.9.107:2379,https://192.168.9.108:2379,https://19第 34 页 共 41 页
2.168.9.109:2379" endpoint health -w table
+----------------------------+--------+-------------+-------+
|
ENDPOINT
| HEALTH |
TOOK
| ERROR |
+----------------------------+--------+-------------+-------+
| https://192.168.9.108:2379 |
true | 36.930651ms |
|
| https://192.168.9.107:2379 |
true | 39.565983ms |
|
| https://192.168.9.109:2379 |
true | 40.177647ms |
|
+----------------------------+--------+-------------+-------+
10.4.4 Etcd 节点扩容
将 Etcd04、Etcd05 两个节点加入到现有 Etcd 集群中,从而实现 Etcd 集群扩容,从三
个节点到五个节点。扩容的操作如下所示。
1. 拷贝文件到 Etcd04、Etcd05 节点
拷贝相关操作在 Etcd01 节点执行。
[root@etcd04 ~]# mkdir /etc/etcd
//etcd04、etcd05 都需创建该目录
[root@etcd01 ~]# scp /etc/etcd/* 192.168.9.110:/etc/etcd/
[root@etcd01 ~]# scp /etc/etcd/* 192.168.9.111:/etc/etcd/
[root@etcd01 ~]# scp /etc/systemd/system/etcd.service 192.168.9.110:/etc/systemd/system/
[root@etcd01 ~]# scp /etc/systemd/system/etcd.service 192.168.9.111:/etc/systemd/system/
[root@etcd01 ~]# scp /usr/local/bin/* 192.168.9.110:/usr/local/bin/
[root@etcd01 ~]# scp /usr/local/bin/etcd* 192.168.9.111:/usr/local/bin/
2. 修改 Etcd04 节点配置文件
[root@etcd04 etcd]# vim /etc/etcd/etcd
NAME="etcd4"
INTERNAL_IP="192.168.9.110"
ETCD_SERVERS="etcd1=https://192.168.9.107:2380,etcd2=https://192.168.9.108:2380,etcd3=htt
ps://192.168.9.109:2380,etcd4=https://192.168.9.110:2380"
//注意新增内容
[root@etcd04 ~]# vim /etc/systemd/system/etcd.service
//省略部分内容
--initial-cluster-token etcd-cluster-0 \第 35 页 共 41 页
--initial-cluster ${ETCD_SERVERS} \
--initial-cluster-state existing \
//此处要从 new 修改为 existing
--data-dir=/var/lib/etcd
//省略部分内容
3. 将 Etcd04 加入集群
[root@etcd04 etcd]# rm -rf /var/lib/etcd/*
//删除待加入 etcd 存储目录内数据,如果没有该目
录则不需要删除
[root@etcd04 etcd]# etcdctl --cacert=/etc/etcd/ca.pem --cert=/etc/etcd/etcd.pem --key=/etc/e
tcd/etcd-key.pem --endpoints="https://192.168.9.107:2379" member add etcd4 --peer-urls=
https://192.168.9.110:2380
//将新成员加入到集群中
Member ede8d973e99bee24 added to cluster fc924b3aa6e31f92
ETCD_NAME="etcd4"
ETCD_INITIAL_CLUSTER="etcd1=https://192.168.9.107:2380,etcd3=https://192.168.9.109:2380,e
tcd4=https://192.168.9.110:2380,etcd2=https://192.168.9.108:2380"
ETCD_INITIAL_ADVERTISE_PEER_URLS="https://192.168.9.110:2380"
ETCD_INITIAL_CLUSTER_STATE="existing"
4. 启动 Etcd04
[root@etcd04 ~]# systemctl enable etcd
[root@etcd04 ~]# systemctl start etcd
查看日志会有如下错误。
[root@etc04 ~]# tail -f /var/log/messages
Jun 21 00:11:03 localhost etcd: rejected connection from "192.168.9.109:50228" (error "remot
e error: tls: bad certificate", ServerName "")
Jun 21 00:11:03 localhost etcd: rejected connection from "192.168.9.108:51866" (error "remot
e error: tls: bad certificate", ServerName "")
Jun 21 00:11:03 localhost etcd: rejected connection from "192.168.9.108:51864" (error "remot第 36 页 共 41 页
e error: tls: bad certificate", ServerName "")
Jun 21 00:11:03 localhost etcd: rejected connection from "192.168.9.108:51872" (error "remot
e error: tls: bad certificate", ServerName "")
Jun 21 00:11:03 localhost etcd: rejected connection from "192.168.9.109:50234" (error "remot
e error: tls: bad certificate", ServerName "")
Jun 21 00:11:03 localhost etcd: rejected connection from "192.168.9.109:50236" (error "remot
e error: tls: bad certificate", ServerName "")
Jun 21 00:11:03 localhost etcd: rejected connection from "192.168.9.108:51876" (error "remot
e error: tls: bad certificate", ServerName "")
Jun 21 00:11:03 localhost etcd: rejected connection from "192.168.9.108:51874" (error "remot
e error: tls: bad certificate", ServerName "")
Jun 21 00:11:03 localhost etcd: rejected connection from "192.168.9.108:51882" (error "remot
e error: tls: bad certificate", ServerName "")
通过报错日志信息可知,Etcd04 被拒绝,提示远程认证错误。报错的主要原因是新节
点的 IP 信息不在认证证书内,导致新节点无法加入。证书的内容如下所示。
[root@etcd01 ~]# openssl x509 -in /etc/etcd/etcd.pem -noout -text
//etcd01 节点查看
Certificate:
Data:
Version: 3 (0x2)
Serial Number:
07:cb:74:19:84:0e:5b:6e:52:47:30:40:f5:e1:84:cc:78:48:fd:f0
Signature Algorithm: sha256WithRSAEncryption
Issuer: C=CN, ST=Beijing, L=Beijing, O=k8s, OU=System, CN=kubernetes
Validity
Not Before: Jun 22 07:13:00 2020 GMT
Not After : Jun 20 07:13:00 2030 GMT
//省略了部分内容
X509v3 Subject Key Identifier:
DD:BF:5D:DB:0D:A0:29:E5:CF:A6:E4:31:B0:BF:23:AB:01:97:B5:EB
X509v3 Authority Key Identifier:
keyid:DC:AD:D1:89:AA:3D:CD:60:19:98:68:FC:B7:4E:D7:85:D2:30:0A:C9
X509v3 Subject Alternative Name:
IP Address:127.0.0.1, IP Address:192.168.9.107, IP Address:192.168.9.108,
IP Address:192.168.9.109
Signature Algorithm: sha256WithRSAEncryption
1c:40:3b:12:57:5e:61:24:5b:42:98:cf:50:2e:f1:86:5c:3f:
b0:98:61:09:ca:1b:8a:2e:ee:0f:2c:04:86:97:e7:11:af:ab:第 37 页 共 41 页
//省略了部分内容
5. 重新生成证书
新生成证书的操作在 Etcd04 节点上完成。
[root@etcd01 ~]# scp -r /root/keys 192.168.9.110:/root/ //从 etcd01 上将 keys 目录拷贝到 etcd
04
[root@etcd04 ~]# vim /root/keys/etcd-csr.json
{
"CN": "etcd",
"hosts": [
"127.0.0.1",
"192.168.9.107",
"192.168.9.108",
"192.168.9.109",
"192.168.9.110",
//增加新节点 IP,注意标点符号
"192.168.9.111"
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "Beijing",
"L": "Beijing",
"O": "etcd",
"OU": "etcd"
}
]
}
[root@etcd04 ~]# cd /root/keys
[root@etcd04 keys]# cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json
-profile=kubernetes etcd-csr.json | cfssljson -bare etcd
2020/06/21 15:25:43 [INFO] generate received request
2020/06/21 15:25:43 [INFO] received CSR
2020/06/21 15:25:43 [INFO] generating key: rsa-2048
2020/06/21 15:25:44 [INFO] encoded CSR
2020/06/21 15:25:44 [INFO] signed certificate with serial number 17556246285527919764449
2877358087299952238539023
2020/06/21 15:25:44 [WARNING] This certificate lacks a "hosts" field. This makes it unsuitabl
e for
websites. For more information see the Baseline Requirements for the Issuance and Manage
ment
of Publicly-Trusted Certificates, v.1.1.6, from the CA/Browser Forum (https://cabforum.org);
specifically, section 10.2.3 ("Information Requirements").
[root@etcd04 keys]# /bin/cp /root/keys/etcd*pem /etc/etcd/
//覆盖原证书
5. 再次启动 Etcd04 节点
[root@etcd04 ~]# systemctl start etcd
查看 Etcd04 加入集群后状态。
[root@etcd04 ~]# etcdctl --cacert=/etc/etcd/ca.pem --cert=/etc/etcd/etcd.pem --key=/etc/etc
d/etcd-key.pem --endpoints="https://192.168.9.107:2379,https://192.168.9.108:2379,https://19
2.168.9.109:2379" member list -w table
+------------------+---------+--------+----------------------------+----------------------------+------------+
|
ID
| STATUS | NAME |
PEER ADDRS
|
CLIENT
ADDRS
| IS LEARNER |
+------------------+---------+--------+----------------------------+----------------------------+------------+
| f054c04091dcaf8 | started | etcd1 | https://192.168.9.107:2380 | https://192.168.9.107:2379
|
false |
| c78ea993ce47312f | started | etcd3 | https://192.168.9.109:2380 | https://192.168.9.109:2379
|
false |
| ede8d973e99bee24 | started | etcd4 | https://192.168.9.110:2380 | https://192.168.9.110:237
9 |
false |
| f967889e726a5c34 | started | etcd2 | https://192.168.9.108:2380 | https://192.168.9.108:2379
|
false |
+------------------+---------+--------+----------------------------+----------------------------+------------+
[root@etcd04
~]#
etcdctl
--cacert=/etc/etcd/ca.pem
--cert=/etc/etcd/etcd.pem
--key=/etc/etcd/etcd-key.pem
--endpoints="https://192.168.9.107:2379,https://192.168.9.108:2379,https://192.168.9.109:237
9,https://192.168.9.110:2379" endpoint health -w table
+----------------------------+--------+-------------+-------+第 39 页 共 41 页
|
ENDPOINT
| HEALTH |
TOOK
| ERROR |
+----------------------------+--------+-------------+-------+
| https://192.168.9.110:2379 |
true | 76.983152ms |
|
| https://192.168.9.107:2379 |
true | 52.118826ms |
|
| https://192.168.9.108:2379 |
true | 53.369632ms |
|
| https://192.168.9.109:2379 |
true | 52.646081ms |
|
+----------------------------+--------+-------------+-------+
10.4.5 Etcd05 节点配置
1. 修改配置文件
[root@etcd05 ~]# vim /etc/etcd/etcd
NAME="etcd5"
INTERNAL_IP="192.168.9.111"
ETCD_SERVERS="etcd1=https://192.168.9.107:2380,etcd2=https://192.168.9.108:2380,etcd3=htt
ps://192.168.9.109:2380,etcd4=https://192.168.9.110:2380,etcd5=https://192.168.9.111:2380"
[root@etcd05 ~]# vim /etc/systemd/system/etcd.service
//省略部分内容
--initial-cluster-token etcd-cluster-0 \
--initial-cluster ${ETCD_SERVERS} \
--initial-cluster-state existing \
//此处要从 new 修改为 existing
--data-dir=/var/lib/etcd
//省略部分内容
2. 拷贝证书
[root@etc04 ~]# scp /etc/etcd/etcd*pem 192.168.9.110:/etc/etcd/
//从 etcd04 拷贝到 etcd05
3. 将 Etcd05 加入集群
[root@etcd05 etcd]# etcdctl --cacert=/etc/etcd/ca.pem --cert=/etc/etcd/etcd.pem --key=/etc/e
tcd/etcd-key.pem --endpoints="https://192.168.9.107:2379" member add etcd5 --peer-urls=
https://192.168.9.111:2380第 40 页 共 41 页
Member ecd2968d7ec03a52 added to cluster fc924b3aa6e31f92
ETCD_NAME="etcd5"
ETCD_INITIAL_CLUSTER="etcd1=https://192.168.9.107:2380,etcd3=https://192.168.9.109:2380,e
tcd5=https://192.168.9.111:2380,etcd4=https://192.168.9.110:2380,etcd2=https://192.168.9.108:23
80"
ETCD_INITIAL_ADVERTISE_PEER_URLS="https://192.168.9.111:2380"
ETCD_INITIAL_CLUSTER_STATE="existing"
4. 启动 Etcd05
[root@etcd05 ~]# systemctl enable etcd
[root@etcd05 ~]# systemctl start etcd
5. 查看运行结果
[root@etcd05 ~]# etcdctl --cacert=/etc/etcd/ca.pem --cert=/etc/etcd/etcd.pem --key=/etc/etc
d/etcd-key.pem --endpoints="https://192.168.9.107:2379,https://192.168.9.108:2379,https://19
2.168.9.109:2379" member list -w table
+------------------+---------+--------+----------------------------+----------------------------+------------+
|
ID
| STATUS | NAME |
PEER ADDRS
|
CLIENT
ADDRS
| IS LEARNER |
+------------------+---------+--------+----------------------------+----------------------------+------------+
| f054c04091dcaf8 | started | infra0 | https://192.168.9.107:2380 | https://192.168.9.107:2379
|
false |
| c78ea993ce47312f | started | infra2 | https://192.168.9.109:2380 | https://192.168.9.109:2379
|
false |
| ecd2968d7ec03a52 | started | infra4 | https://192.168.9.111:2380 | https://192.168.9.111:2379
|
false |
| ede8d973e99bee24 | started | infra3 | https://192.168.9.110:2380 | https://192.168.9.110:237
9 |
false |
| f967889e726a5c34 | started | infra1 | https://192.168.9.108:2380 | https://192.168.9.108:2379
|
false |
+------------------+---------+--------+----------------------------+----------------------------+------------+
[root@etcd05 ~]# etcdctl --cacert=/etc/etcd/ca.pem --cert=/etc/etcd/etcd.pem --key=/etc/et
cd/etcd-key.pem --endpoints="https://192.168.9.107:2379,https://192.168.9.108:2379,https://1
92.168.9.109:2379,https://192.168.9.110:2379,https://192.168.9.111:2379" endpoint health -w
table
+----------------------------+--------+-------------+-------+
|
ENDPOINT
| HEALTH |
TOOK
| ERROR |
+----------------------------+--------+-------------+-------+
| https://192.168.9.111:2379 |
true | 44.643934ms |
|
| https://192.168.9.108:2379 |
true | 26.522164ms |
|
| https://192.168.9.110:2379 |
true | 39.109227ms |
|
| https://192.168.9.109:2379 |
true | 39.484042ms |
|
| https://192.168.9.107:2379 |
true | 59.261277ms |
|
+----------------------------+--------+-------------+-------+
[root@etcd05 ~]# etcdctl --cacert=/etc/etcd/ca.pem --cert=/etc/etcd/etcd.pem --key=/etc/etc
d/etcd-key.pem --endpoints="https://192.168.9.107:2379,https://192.168.9.108:2379,https://19
2.168.9.109:2379,https://192.168.9.110:2379,https://192.168.9.111:2379" endpoint status -w
table
+----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+-----
---------------+--------+
|
ENDPOINT
|
ID
| VERSION | DB SIZE | IS LEADER | I
S LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS |
+----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+-----
---------------+--------+
| https://192.168.9.107:2379 | 32156d399a8c126b |
3.4.1 |
25 kB |
false |
false
|
62 |
14 |
14 |
|
| https://192.168.9.108:2379 | f71a55dc85e08902 |
3.4.1 |
25 kB |
false |
false
|
62 |
14 |
14 |
|
| https://192.168.9.109:2379 | 5d84127042114763 |
3.4.1 |
25 kB |
true |
false
|
62 |
14 |
14 |
|
| https://192.168.9.110:2379 | c7480dfafe52cd0c |
3.4.1 |
20 kB |
false |
false |
62 |
14 |
14 |
|
| https://192.168.9.111:2379 | 987347c11b054b8a |
3.4.1 |
20 kB |
false |
false
|
62 |
14 |
14 |
|
+----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+-----
---------------+--------+
将五台 Etcd 主机的“/etc/etcd/etcd”文件内“ETCD_SERVERS”的值统一成 Etcd05
节点的配置,也就是说都包含五台信息。这样在后续重启的过程中,不会导致错误的出现,
可以保证集群通过配置正常加载、正常运行。
至此,Etcd 集群扩容完成。
