网站,:豆瓣电影 Top 250
爬取豆瓣前250电影的信息,
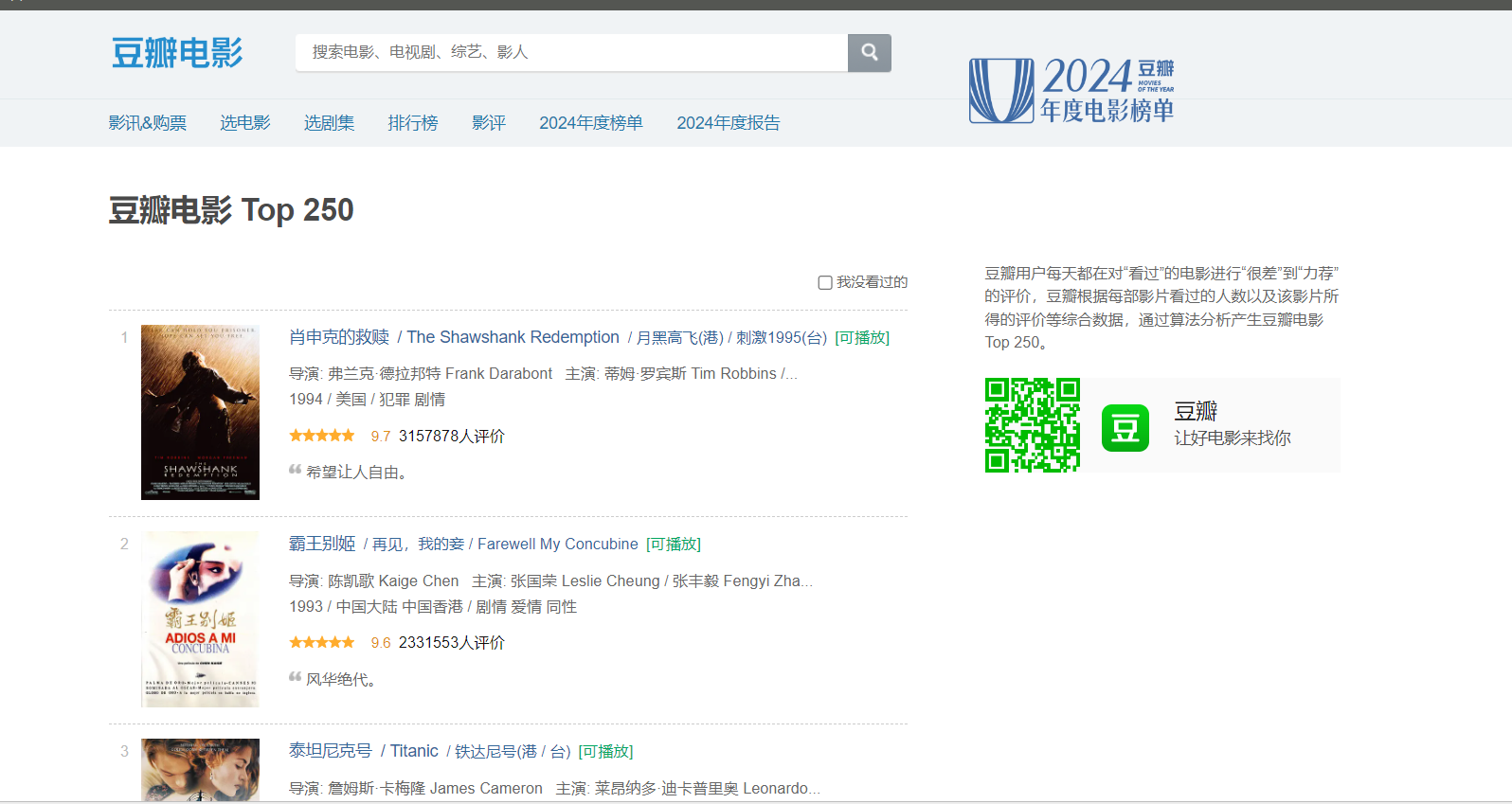
F12打开网页控制台,查看网页元素,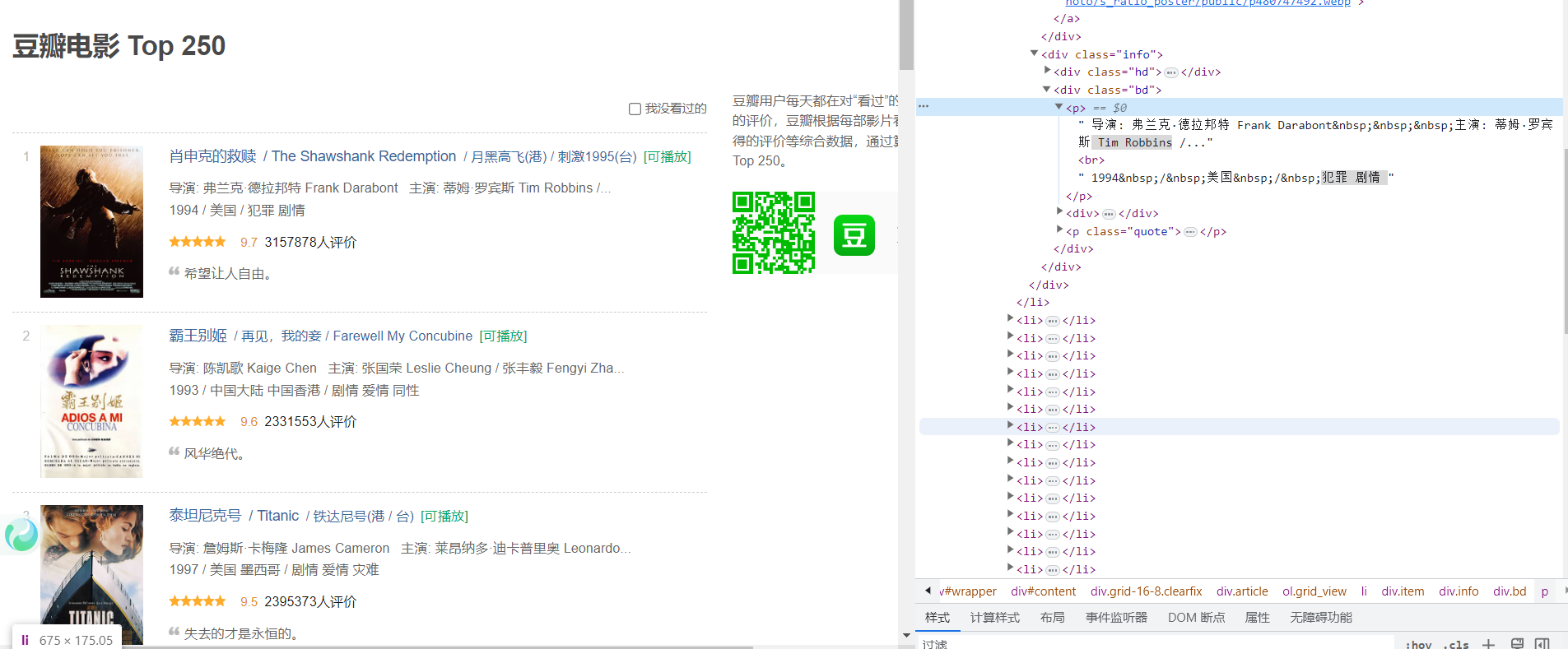
发现网页数据直接可以查看到,为静态网页数据,较为简单
目录
1.第一步使用urllib库获取网页
2.第二步使用BeautifulSoup和re库解析数据
2.1.定位数据块
2.2.正则化匹配
3.第三步数据导出excel
完整代码:
1.第一步使用urllib库获取网页
观察网页url结构:
首先,我们分析一下这个网页的结构,是一个还算比较规则的网页,每页25条,一共10页。
我们点击第一页:url = https://movie.douban.com/top250?start=0&filter=
我们点击第二页:url = 豆瓣电影 Top 250
我们点击第三页:url = 豆瓣电影 Top 250
import urllib.request, urllib.error# 定义基础url,发现规律,每页最后变动的是start=后面的数字
baseurl = "https://movie.douban.com/top250?start="# 定义一个函数getHtmlByURL,得到指定url网页的内容
def geturl(url):# 自定义headers(伪装,告诉豆瓣服务器,我们是什么类型的机器,以免被反爬虫)headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36'}# 利用Request类来构造自定义头的请求req = urllib.request.Request(url, headers=headers)# 定义一个接收变量,用于接收html = ""try:# urlopen()方法的参数,发送给服务器并接收响应resp = urllib.request.urlopen(req)# urlopen()获取页面内容,返回的数据格式为bytes类型,需要decode()解码,转换成str类型html = resp.read().decode("utf-8")except urllib.error.URLError as e:if hasattr(e, "code"):print(e.code)if hasattr(e, "reason"):print(e.reason)return htmlprint(geturl(baseurl + "0"))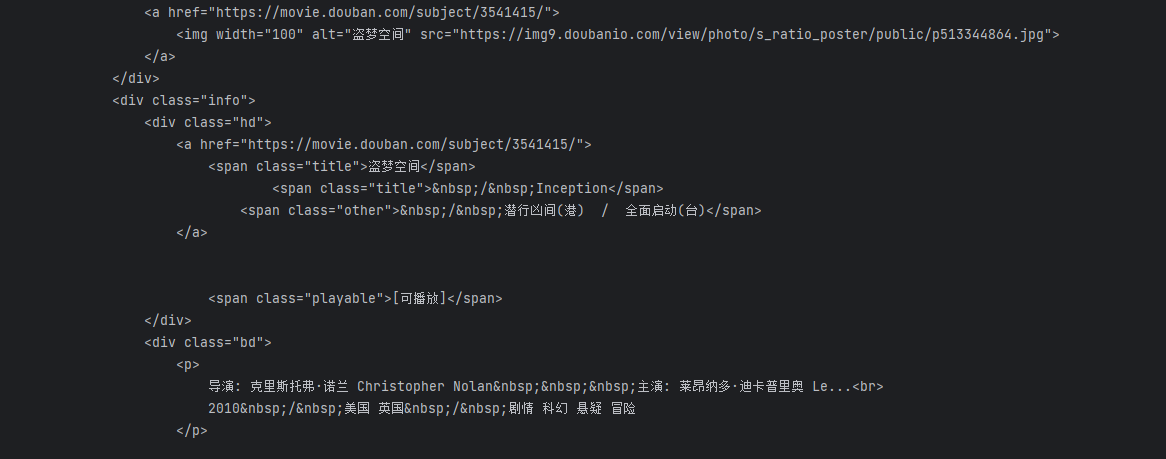
2.第二步使用BeautifulSoup和re库解析数据
2.1.定位数据块
需要找到我们需要的信息在对应数据中的那个位置里面,可以在控制台定位,
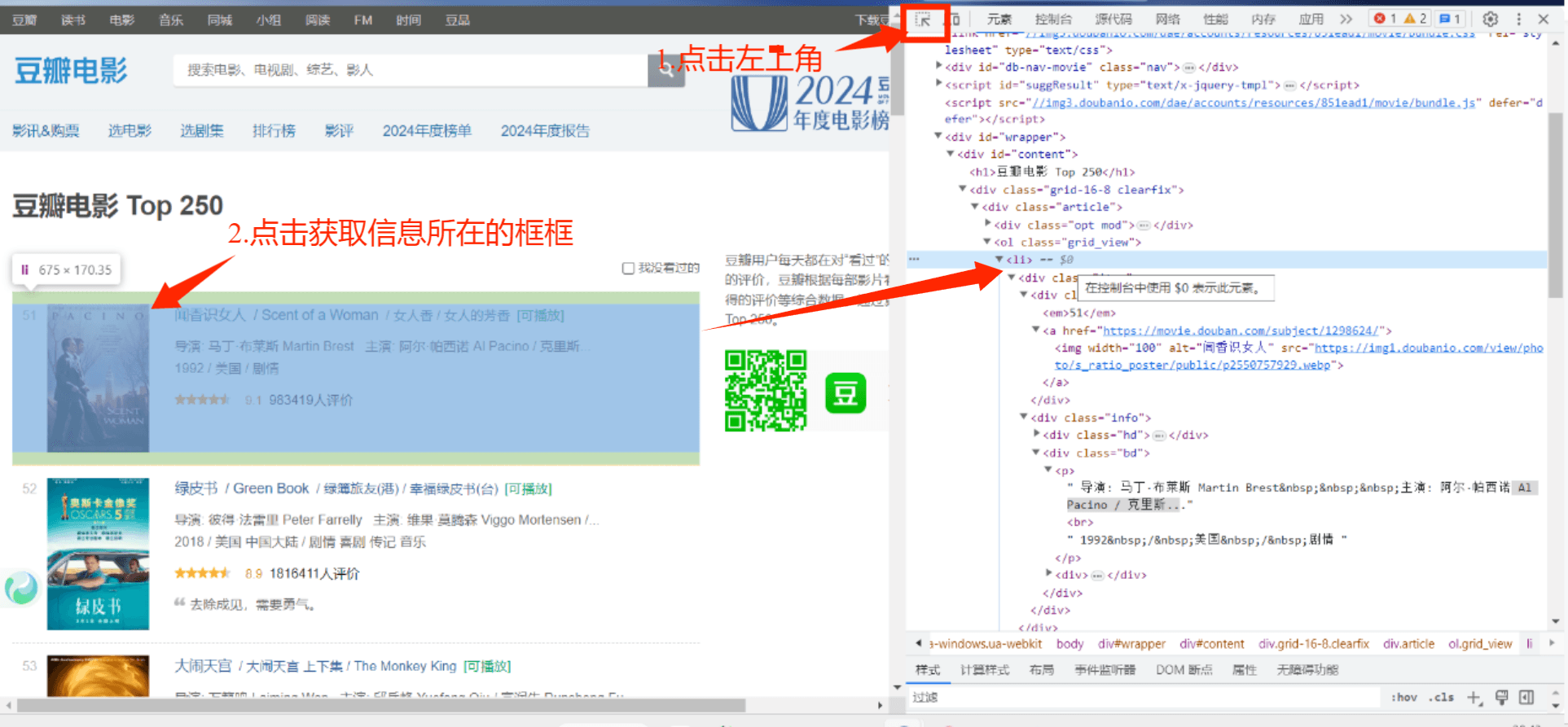
我们需要获取的数据标签是 ‘div’,类名是‘item’,
from bs4 import BeautifulSoup# 定义一个函数,并解析这个网页
def analysisData(url):# 获取指定网页html = geturl(url)# 指定解析器解析html,得到BeautifulSoup对象soup = BeautifulSoup(html, "html5lib")# 定位我们的数据块在哪for item in soup.find_all('div', class_="item"):print(item)return ""analysisData(baseurl)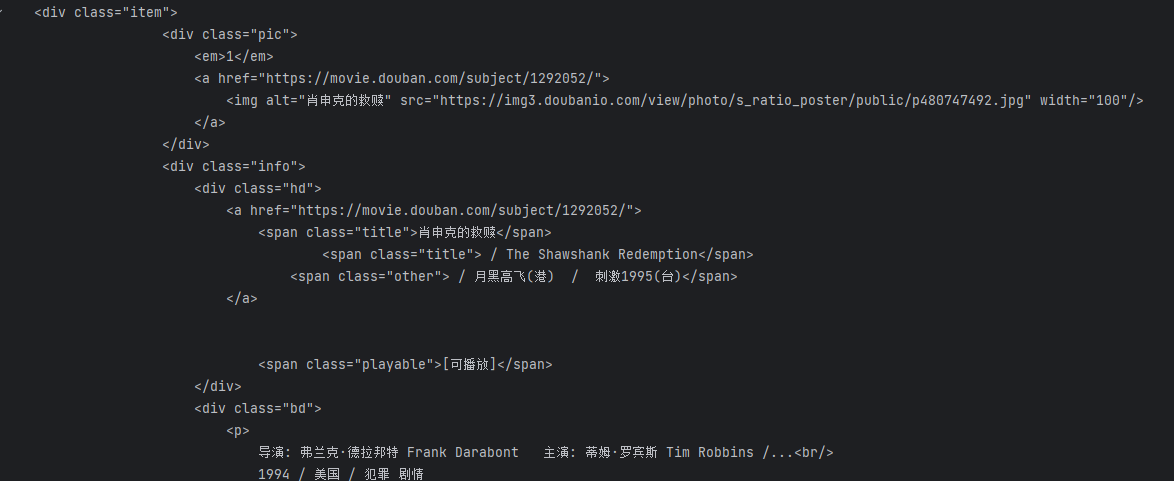 2.2.正则化匹配
2.2.正则化匹配
现在获取到的块还是原始的css代码,创建正则化匹配筛选出我们需要的数据,
- 提取详细链接:

findLink = re.compile(r'<a href="(.*?)">')
- 图片

findImgSrc = re.compile(r'<img.*src="(.*?)"', re.S)
- 片名

findTitle = re.compile(r'<span class="title">(.*)</span>')
import re# 定义正则对象获取指定的内容
# 提取链接(链接的格式都是<a href="开头的)
findLink = re.compile(r'<a href="(.*?)">')
# 提取图片
findImgSrc = re.compile(r'<img.*src="(.*?)"', re.S) # re.S让 '.' 特殊字符匹配任何字符,包括换行符;
# 提取影片名称
findTitle = re.compile(r'<span class="title">(.*)</span>')
# 提取影片评分
findRating = re.compile(r'<span class="rating_num" property="v:average">(.*)</span>')
# 提取评价人数
findJudge = re.compile(r'<span>(\d*)人评价</span>')
# 提取简介
inq= re.compile(r'<p\s+class="quote">.*?<span>(.*?)</span>.*?</p>', re.S)
# 提取相关内容
findBd = re.compile(r'<div class="bd">\s*<p>\s*'r'导演: (.*?)\s*主演: (.*?)<br/>\s*'r'(\d{4}).*?/\s*(.*?)\s*/\s*(.*?)\s*</p>',re.S
)# 定义一个函数,并解析这个网页
def analysisData(baseurl):# 获取指定网页html = geturl(baseurl)# 指定解析器解析html,得到BeautifulSoup对象soup = BeautifulSoup(html, "html5lib")dataList = []# 定位我们的数据块在哪for item in soup.find_all('div', class_="item"):# item 是 bs4.element.Tag 对象,这里将其转换成字符串来处理item = str(item)# 定义一个列表 来存储每一个电影解析的内容data = []# findall返回的是一个列表,这里提取链接link = re.findall(findLink, item)[0]data.append(link) # 添加链接img = re.findall(findImgSrc, item)[0]data.append(img) # 添加图片链接title = re.findall(findTitle, item)# 一般都有一个中文名 一个外文名if len(title) == 2:# ['肖申克的救赎', '\xa0/\xa0The Shawshank Redemption']titlename = title[0] + title[1].replace(u'\xa0', '')else:titlename = title[0] + ""data.append(titlename) # 添加标题pf = re.findall(findRating, item)[0]data.append(pf)pjrs = re.findall(findJudge, item)[0]data.append(pjrs)# 有的可能没有inqInfo = re.findall(inq, item)if len(inqInfo) == 0:data.append(" ")else:data.append(inqInfo[0])matches = re.findall(findBd, item)if matches: # 确保列表非空bd = matches[0]else:bd = None # 或设定默认值/抛出异常# [('\n 导演: 弗兰克·德拉邦特 Frank Darabont\xa0\xa0\xa0主演: 蒂姆·罗宾斯 Tim Robbins /...<br/>\n 1994\xa0/\xa0美国\xa0/\xa0犯罪 剧情\n ', '\n\n \n ')]# bd[0].replace(u'\xa0', '').replace('<br/>', '')# bd = re.sub('<\\s*b\\s*r\\s*/\\s*>', "", bd[0])# bd = re.sub('(\\s+)?', '', bd)data.append(bd)dataList.append(data)return dataListprint(analysisData(baseurl))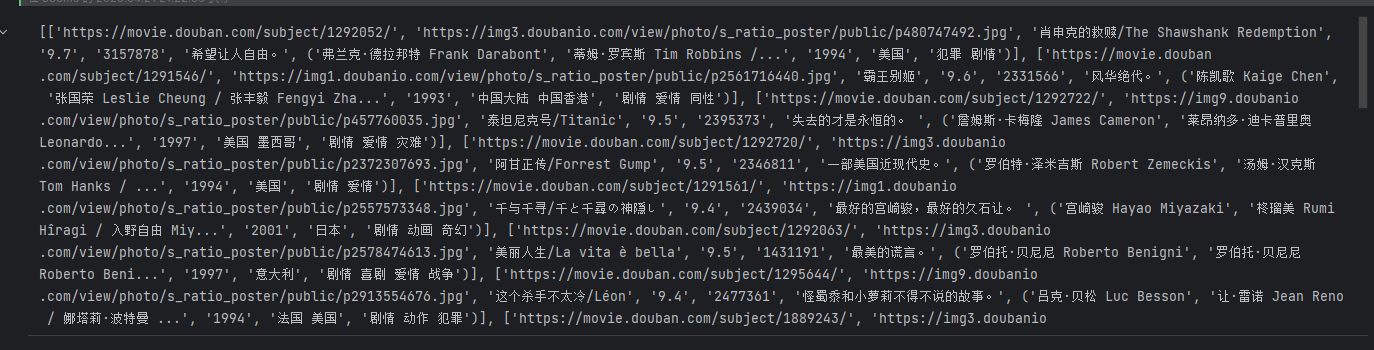
3.第三步数据导出excel
因为处理的是一个页面的,所以需要写一个循环,
import xlwtdef main():allData = []for i in range(0, 250, 25):url = baseurl + str(i)dataList = analysisData(url)allData.extend(dataList)savepath = "C:\pythonProject\python爬虫\爬取豆瓣电影\豆瓣250.xls"book = xlwt.Workbook(encoding="utf-8", style_compression=0) # 创建Workbook对象sheet = book.add_sheet("豆瓣电影Top250", cell_overwrite_ok=True) # 创建工作表col = ("电影详情链接", "图片链接", "电影中/外文名", "评分", "评论人数", "概况", "相关信息")print(len(allData))for i in range(0, 7):sheet.write(0, i, col[i])for i in range(0, 250):print('正在保存第'+str((i+1))+'条')data = allData[i]for j in range(len(data)):sheet.write(i + 1, j, data[j])book.save(savepath)if __name__ == '__main__':main()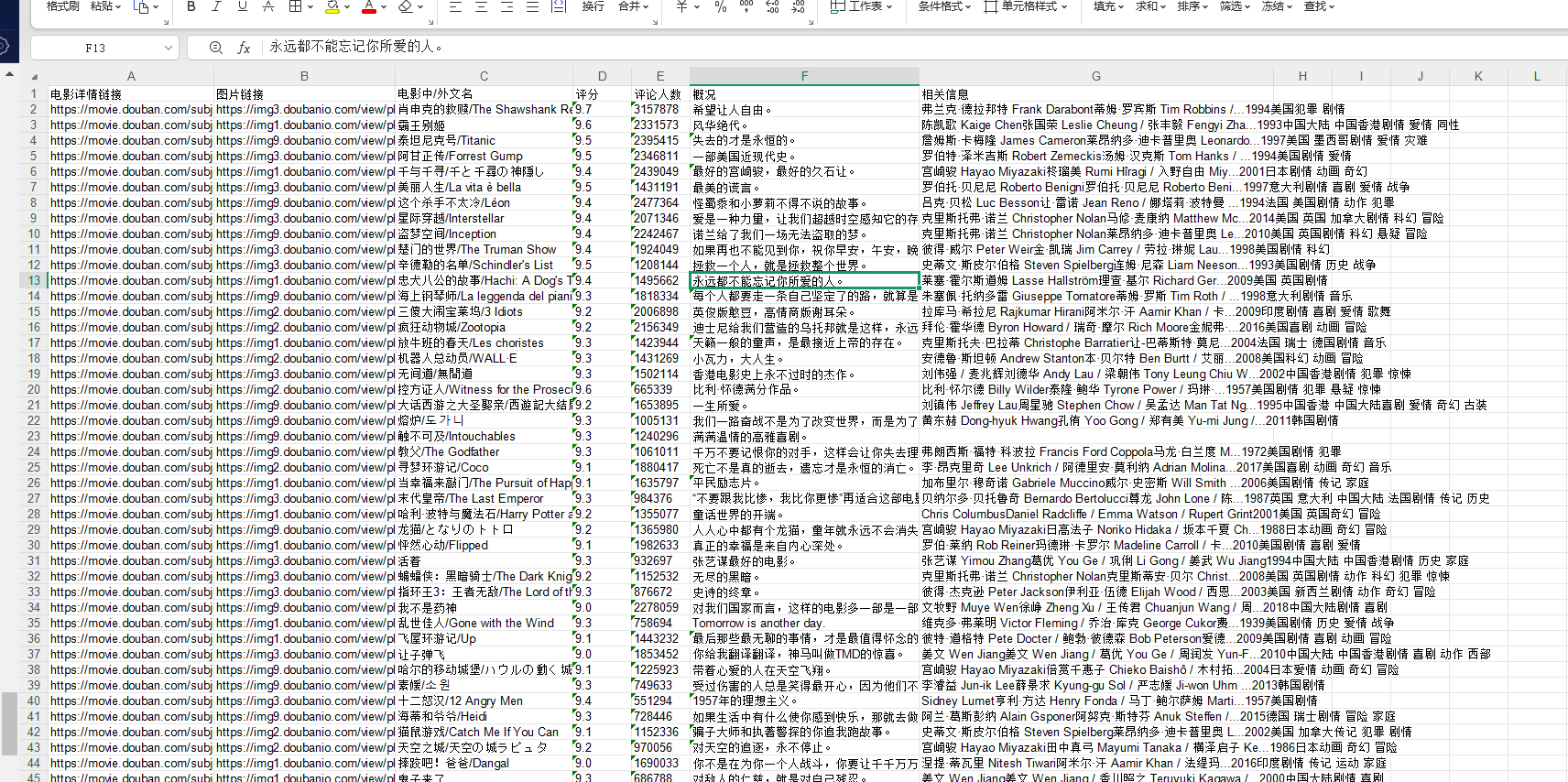
完整代码:
import urllib.request, urllib.error# 定义基础url,发现规律,每页最后变动的是start=后面的数字
baseurl = "https://movie.douban.com/top250?start="# 定义一个函数getHtmlByURL,得到指定url网页的内容
def geturl(url):# 自定义headers(伪装,告诉豆瓣服务器,我们是什么类型的机器,以免被反爬虫)headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36'}# 利用Request类来构造自定义头的请求req = urllib.request.Request(url, headers=headers)# 定义一个接收变量,用于接收html = ""try:# urlopen()方法的参数,发送给服务器并接收响应resp = urllib.request.urlopen(req)# urlopen()获取页面内容,返回的数据格式为bytes类型,需要decode()解码,转换成str类型html = resp.read().decode("utf-8")except urllib.error.URLError as e:if hasattr(e, "code"):print(e.code)if hasattr(e, "reason"):print(e.reason)return htmlfrom bs4 import BeautifulSoup# 定义一个函数,并解析这个网页
def analysisData(url):# 获取指定网页html = geturl(url)# 指定解析器解析html,得到BeautifulSoup对象soup = BeautifulSoup(html, "html5lib")# 定位我们的数据块在哪for item in soup.find_all('div', class_="item"):print(item)return ""analysisData(baseurl)
import re# 定义正则对象获取指定的内容
# 提取链接(链接的格式都是<a href="开头的)
findLink = re.compile(r'<a href="(.*?)">')
# 提取图片
findImgSrc = re.compile(r'<img.*src="(.*?)"', re.S) # re.S让 '.' 特殊字符匹配任何字符,包括换行符;
# 提取影片名称
findTitle = re.compile(r'<span class="title">(.*)</span>')
# 提取影片评分
findRating = re.compile(r'<span class="rating_num" property="v:average">(.*)</span>')
# 提取评价人数
findJudge = re.compile(r'<span>(\d*)人评价</span>')
# 提取简介
inq= re.compile(r'<p\s+class="quote">.*?<span>(.*?)</span>.*?</p>', re.S)
# 提取相关内容
findBd = re.compile(r'<div class="bd">\s*<p>\s*'r'导演: (.*?)\s*主演: (.*?)<br/>\s*'r'(\d{4}).*?/\s*(.*?)\s*/\s*(.*?)\s*</p>',re.S
)# 定义一个函数,并解析这个网页
def analysisData(baseurl):# 获取指定网页html = geturl(baseurl)# 指定解析器解析html,得到BeautifulSoup对象soup = BeautifulSoup(html, "html5lib")dataList = []# 定位我们的数据块在哪for item in soup.find_all('div', class_="item"):# item 是 bs4.element.Tag 对象,这里将其转换成字符串来处理item = str(item)# 定义一个列表 来存储每一个电影解析的内容data = []# findall返回的是一个列表,这里提取链接link = re.findall(findLink, item)[0]data.append(link) # 添加链接img = re.findall(findImgSrc, item)[0]data.append(img) # 添加图片链接title = re.findall(findTitle, item)# 一般都有一个中文名 一个外文名if len(title) == 2:# ['肖申克的救赎', '\xa0/\xa0The Shawshank Redemption']titlename = title[0] + title[1].replace(u'\xa0', '')else:titlename = title[0] + ""data.append(titlename) # 添加标题pf = re.findall(findRating, item)[0]data.append(pf)pjrs = re.findall(findJudge, item)[0]data.append(pjrs)# 有的可能没有inqInfo = re.findall(inq, item)if len(inqInfo) == 0:data.append(" ")else:data.append(inqInfo[0])matches = re.findall(findBd, item)if matches: # 确保列表非空bd = matches[0]else:bd = None # 或设定默认值/抛出异常# [('\n 导演: 弗兰克·德拉邦特 Frank Darabont\xa0\xa0\xa0主演: 蒂姆·罗宾斯 Tim Robbins /...<br/>\n 1994\xa0/\xa0美国\xa0/\xa0犯罪 剧情\n ', '\n\n \n ')]# bd[0].replace(u'\xa0', '').replace('<br/>', '')# bd = re.sub('<\\s*b\\s*r\\s*/\\s*>', "", bd[0])# bd = re.sub('(\\s+)?', '', bd)data.append(bd)dataList.append(data)return dataListimport xlwtdef main():allData = []for i in range(0, 250, 25):url = baseurl + str(i)dataList = analysisData(url)allData.extend(dataList)savepath = "C:\pythonProject\python爬虫\爬取豆瓣电影\豆瓣250.xls"book = xlwt.Workbook(encoding="utf-8", style_compression=0) # 创建Workbook对象sheet = book.add_sheet("豆瓣电影Top250", cell_overwrite_ok=True) # 创建工作表col = ("电影详情链接", "图片链接", "电影中/外文名", "评分", "评论人数", "概况", "相关信息")print(len(allData))for i in range(0, 7):sheet.write(0, i, col[i])for i in range(0, 250):print('正在保存第'+str((i+1))+'条')data = allData[i]for j in range(len(data)):sheet.write(i + 1, j, data[j])book.save(savepath)if __name__ == '__main__':main()