摘要:
作者提到,该方法将物体检测看做直接的集合预测,在传统的目标检测算法中,会先生成候选区域,然后对每个候选区域进行单独的预测(包括物体的分类和预测框的回归),集合预测就是直接基于原始图像生成一系列预测结果,避免了划分区域。(不知道我这样理解对不对)。这样能够简化流程。该模型基于二分匹配(我的理解是预测结果与真实结果之间的匹配)以及transformer机制(简单来说就是编码和解码过程)对目标进行检测的,并且是并行输出,(看来是直接拿transformer的结果来用啊,改都不改一点)。损失计算是全局损失,对预测集合和真实目标整体计算,(相比二阶段任务而言,损失也简化了好多流程)。最后还介绍了一下优势,在COCO数据集上取的了不错的效果,而且模型简单,泛化能力很强。
嗯嗯...,我来让ai读读文章来概括一下:(nonono,只是补充)。
二分强制匹配是一种特定的匹配机制,确保每个预测的物体都是唯一的,确实是是将预测结果和真实结果进行一对一的匹配,好处是模型被迫在输出的时候对每个物体生成唯一的预测,同一个物体不会被多次预测,(达到比非极大抑制更好的效果,但是如果图片中存在多个同一目标呢?),解决方案是detr中存在多个数量的预测。
基于集合的全局损失:损失关注的是预测集合和真实集合的整体损失,而不是逐个比较。
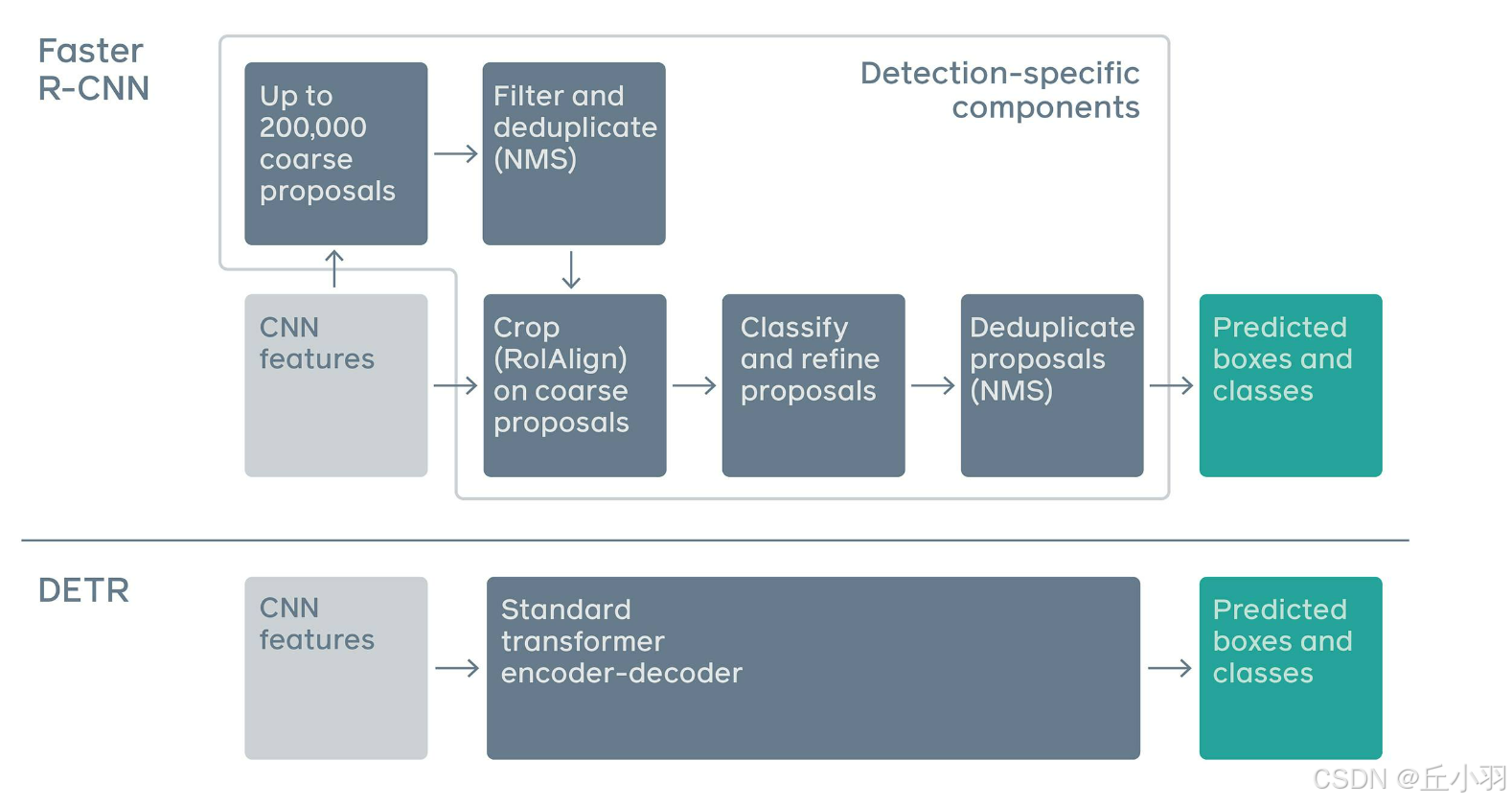
介绍:
第一段没什么很重要的信息,相当于是重复了一遍。第二段:自注意力机制精确的模拟了句子之中元素之间的相互关系,非常适应有限值的集合预测问题(所谓限制是指不能重复预测,看得出作者对非极大抑制方法有点瞧不起)。在这里科普一下自注意力机制:作用是在输入元素的时候,动态的关注其他的元素,计算查询与键之间的相似性,并为其赋予权重。第三段也是重复叙述,第四段,之前的检测器侧重于使用RNN的逻辑回归,我们的匹配机制直接分配预测框给真实框。第四段,重复叙述了优势之后指出对于小目标检测精度一般的问题。后面关于全景分割的部分不看,我们关注的只是目标检测,介绍部分还说,要在下文中寻找影响检测精度的重要因素。
相关工作:
(吐槽一下,内容很冗余,光是看到相关工作部分,我至少听他叙述了四五遍“我们的工作是直接预测,之前还没人做过”,“我们的模型在COCO数据集上表现很好”)。其实这些如果觉得必要,叙述三次就行了,没必要说这么多次。
2.1,这部分没有细讲,就是说传统的检测要避免重复检测,而我们的模型使用的是基于匈牙利算法的二分匹配,有效的避免了后处理,但是匈牙利算法是啥,没有具体叙述,具体数学计算不再赘述,匹配原理大概是这样的: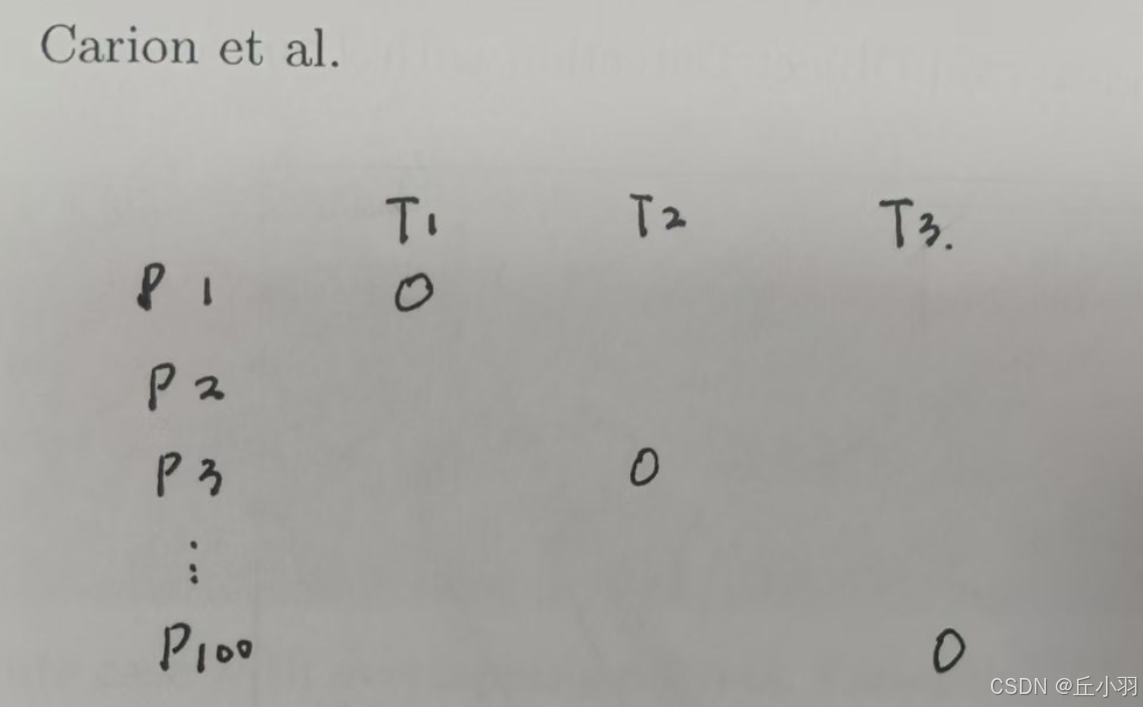
我们预测的目标有100个,但是图像中真实存在的只有3个,对于每一个真实目标,在所有目标框中选择唯一一个与之对应,但是不同真实目标不能选定同一个预测目标,使得损失最小化。
2.2主要是将transformer,其在自然语言处理中的地位,明显的优势是全局计算以及良好的记忆能力,本模型运用了transformer,并在算力成本以及全局计算能力之间折中。这里我再简要介绍一下transformer,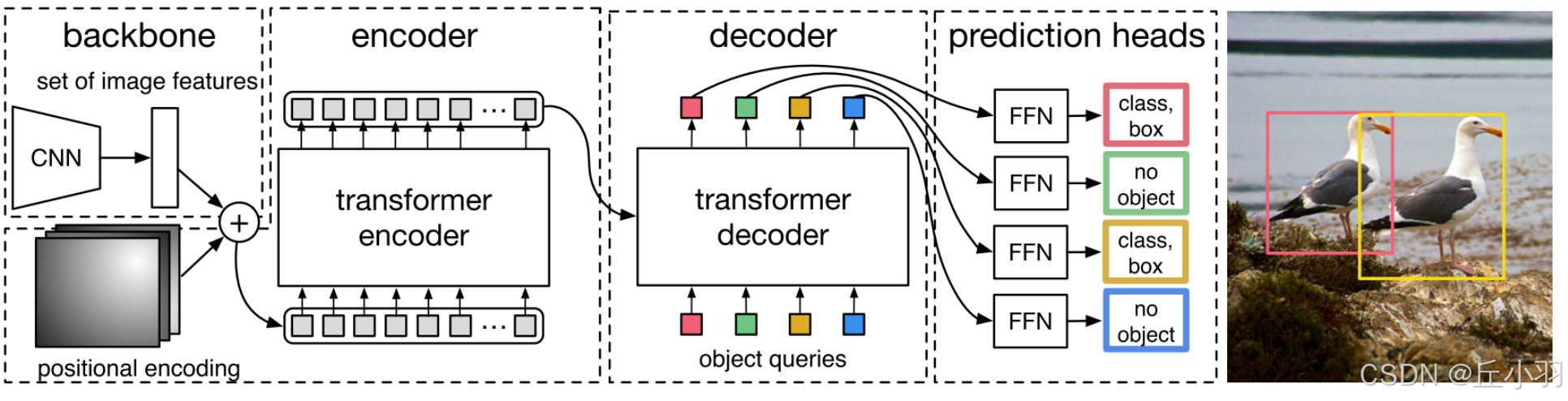
将原始图像提取特征,然后与位置编码相加,再推倒(我喜欢用这个词,虽然不是很合适)成一维,放入encoder模块,得到的结果输出到decoder中,在decode之前初始化100个queries(随机初始化),进行解码,解码结果与真实图像进行二分匹配。
详细讲解一下encoder过程,跟着代码看如下:
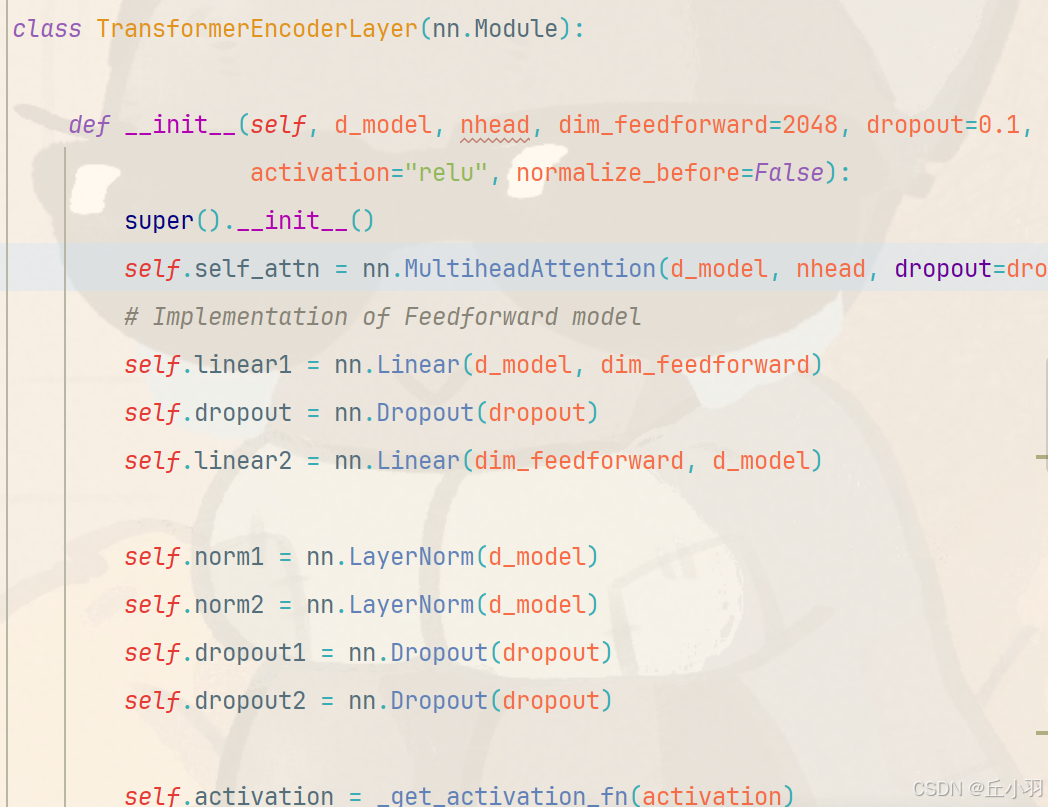
这里头是d_model是512,nhead是8(源码中),首先进入到多头注意力机制函数中......,有点不适合写进博客(上次写博客两万字都卡的要命,原代码内容量大,可能会影响博客原本的布局美感,在此只是截取一段):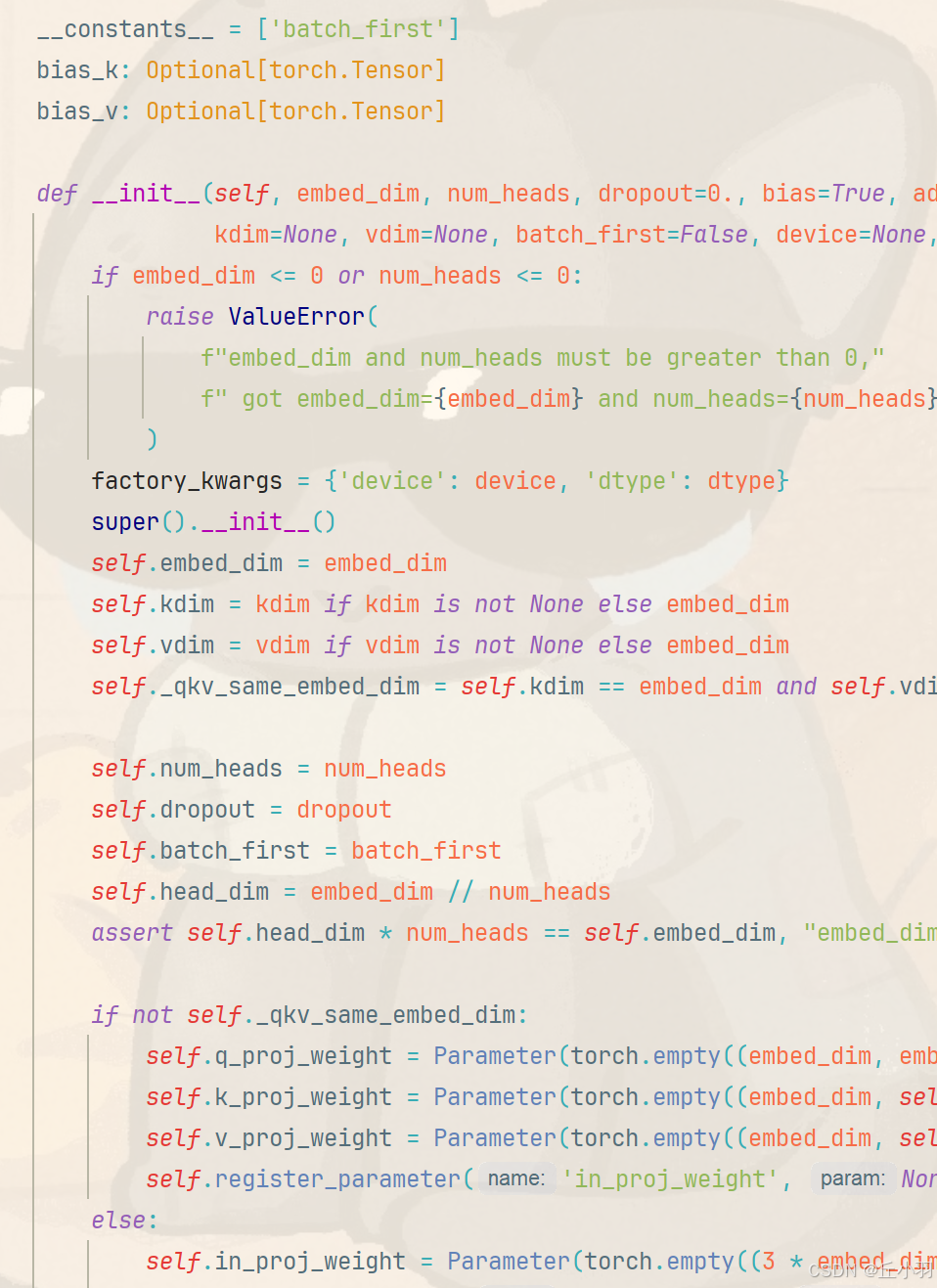
有点丑,直接问AI吧还是:
多头注意力机制先随机初始化三个权重矩阵,对应Q,K,V。使用随机初始化数值,满足Xavier 均匀分布,偏置是可以选择的,在源代码中默认存在偏置。
好像不对,自注意力机制是QKV都是x,也就是代码中的原始输入加上位置编码但是这样也就没有了学习的空间,没有从输入转化为合适的QKV部分(这个非常适合学习)。为了使之具有一定的自由度,我们生成了3个权重矩阵,将其与X相乘得到QKV。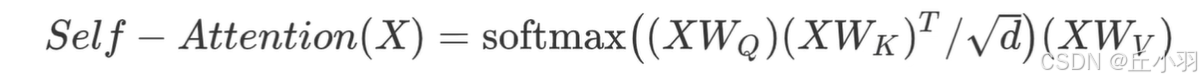
直接看forward过程:
def forward_post(self,src,src_mask: Optional[Tensor] = None,src_key_padding_mask: Optional[Tensor] = None,pos: Optional[Tensor] = None):q = k = self.with_pos_embed(src, pos)src2 = self.self_attn(q, k, value=src, attn_mask=src_mask,key_padding_mask=src_key_padding_mask)[0]src = src + self.dropout1(src2)src = self.norm1(src)src2 = self.linear2(self.dropout(self.activation(self.linear1(src))))src = src + self.dropout2(src2)src = self.norm2(src)return srcdef forward_pre(self, src,src_mask: Optional[Tensor] = None,src_key_padding_mask: Optional[Tensor] = None,pos: Optional[Tensor] = None):src2 = self.norm1(src)q = k = self.with_pos_embed(src2, pos)src2 = self.self_attn(q, k, value=src2, attn_mask=src_mask,key_padding_mask=src_key_padding_mask)[0]src = src + self.dropout1(src2)src2 = self.norm2(src)src2 = self.linear2(self.dropout(self.activation(self.linear1(src2))))src = src + self.dropout2(src2)return srcdef forward(self, src,src_mask: Optional[Tensor] = None,src_key_padding_mask: Optional[Tensor] = None,pos: Optional[Tensor] = None):if self.normalize_before:return self.forward_pre(src, src_mask, src_key_padding_mask, pos)return self.forward_post(src, src_mask, src_key_padding_mask, pos)可选择的forward方法有两种,根据初始化在自注意力机制和前馈网络的顺序,分为post和pre,分别表示在自注意力和前馈网络之前进行归一化以及在自注意力和前馈网络之后进行归一化。
以post为例,首先先将位置嵌入,将q,k,v放入自注意力机制中,对于每个q,分别计算其与所有k相乘的结果,激活后乘以对应的v,得到对于每一个序列的output,将所有的output相加得到结果,(也就是输出),当然使用矩阵计算会更加方便。(保持形状相同)。
然后将dropout之后的finnaloutput与原始输入相加,再经过正则化处理。然后经过的一些列操作源码都很清晰的表示出来了,我将从图像输入到经过第一个encoder layer的过程绘制出来如下:(这里是单头的)。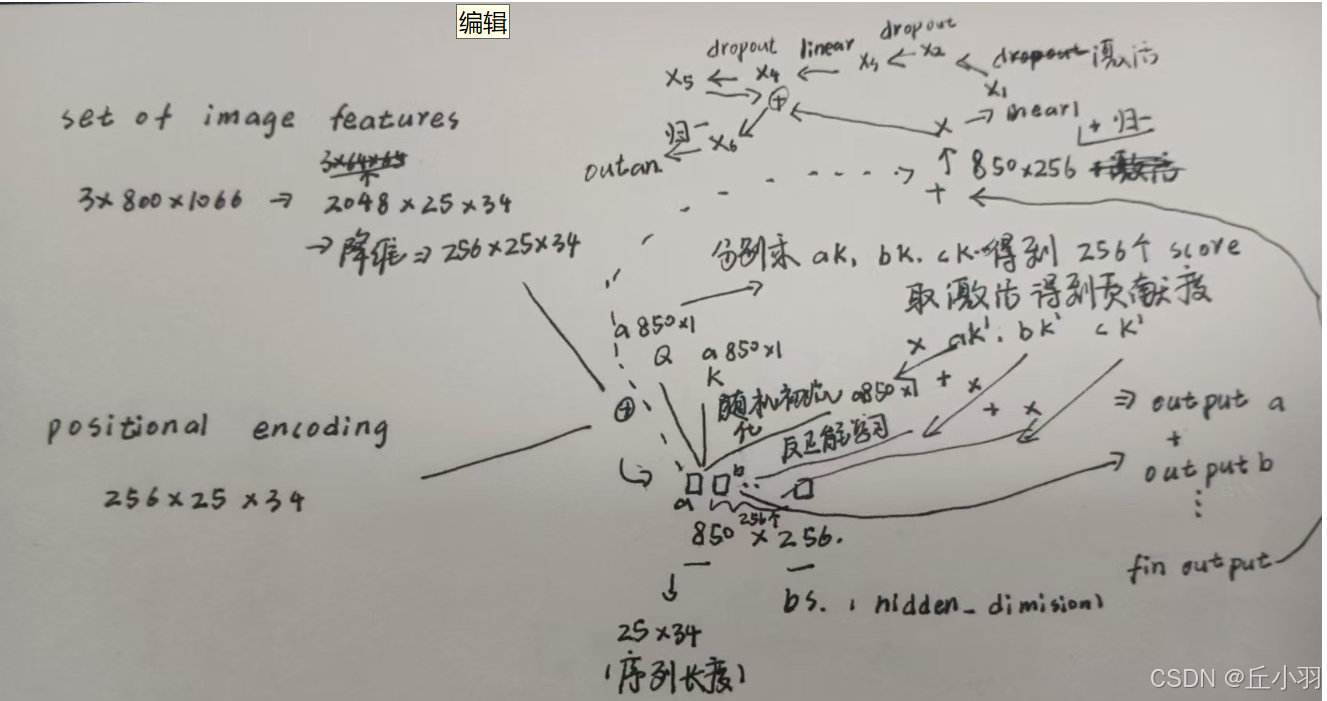 事实上,我们采用的是多头注意力机制,原理如下:
事实上,我们采用的是多头注意力机制,原理如下: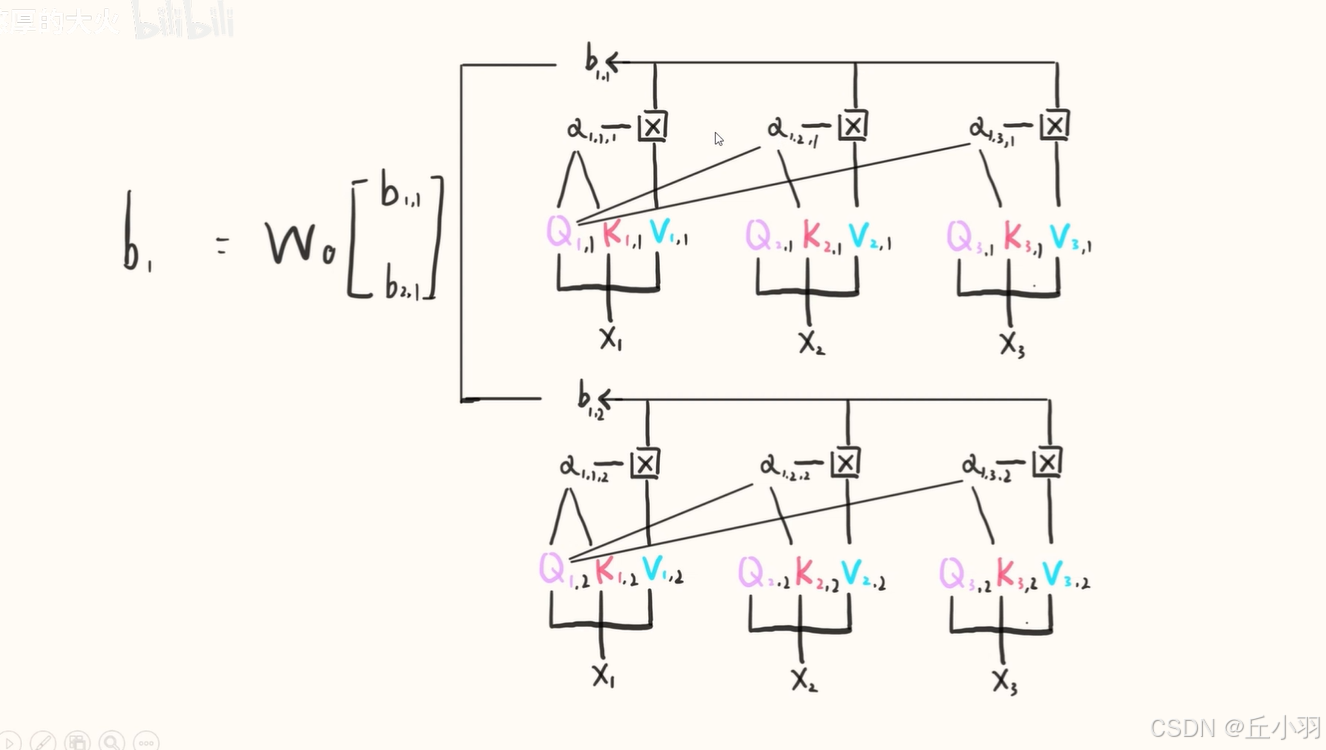
总结而来就是执行多个单头,然后将得到的结果按权重相加,这个权重也是学习来的,从讲故事的角度来说(当然,我认为作者是为了圆自己的说法,没有事实依据的胡扯):每个头会注意到不同的信息。
这里我使用的是forward_post:,在源码中是这样的:
整体是将6个encoder layers层上下接连起来,有意思的是,得到的输出本来就是在最后一个layer层里面归一化过了,但是仍要选择是否要进行进一步的归一化。最后得到输出。
为了清晰明了,作者还将最后一层的输出命名为memory。
编码部分算是过了,然后来看解码部分:
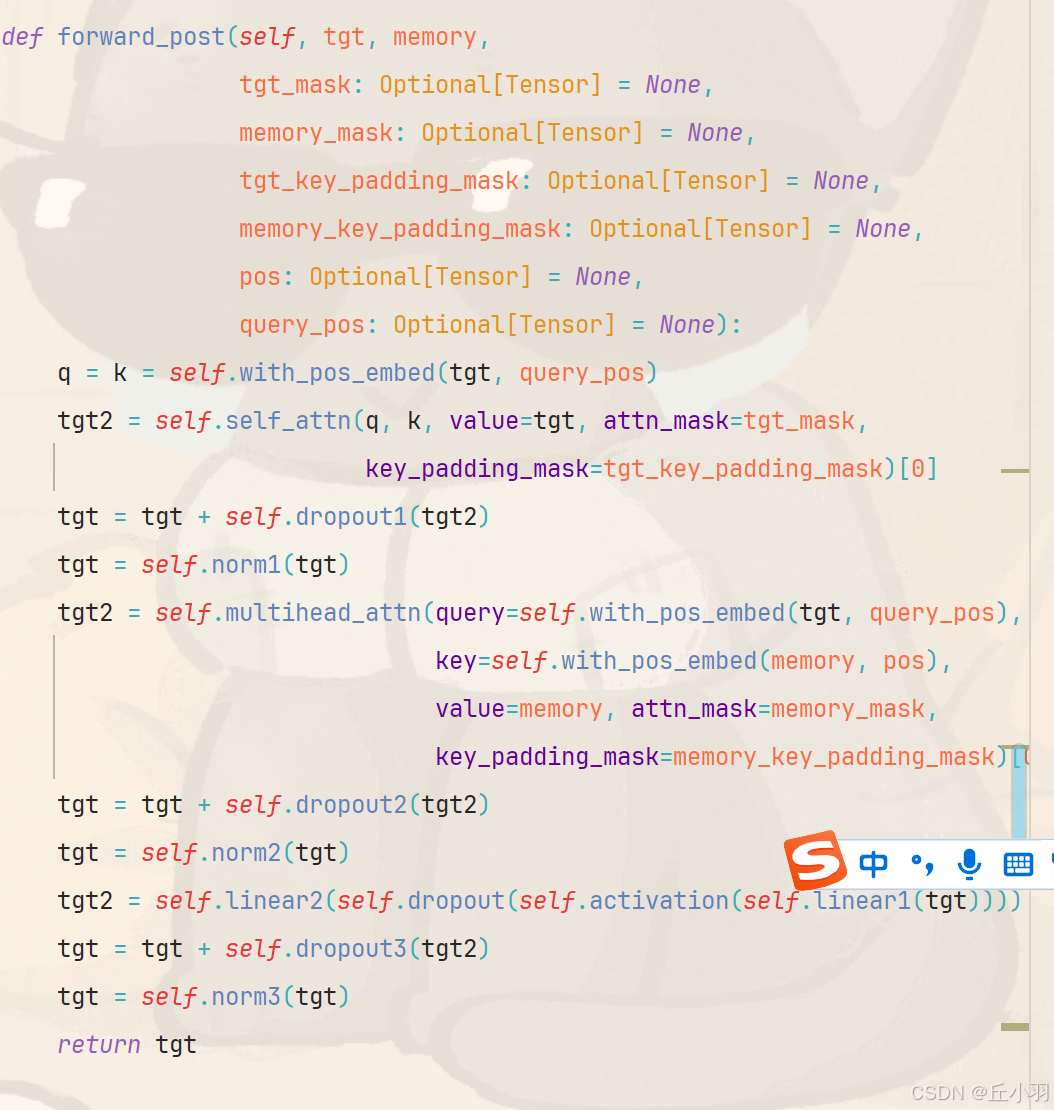
还是以forward_post为例,q和k为原始输入加上位置编码,然后将qk以及不包含位置信息的原始特征输入(其实是随机初始化的tgt),放进自注意力机制中去(代码后面使用了一个multihead_attn)可能会让人觉得自注意力机制不是多头的,其实不然,自注意力机制也是多头的。
自注意力机制得到的结果经过一个残差连接之后,进行归一化,然后再经过一个多头注意力机制模块儿(这个注意力机制中的q为正则化结果再进行一次位置编码,k为encoder得到的输出经过位置编码之后的结果,v为encoder得到的输出)。
多头注意力机制得到的结果进行残差相加...光是叙述不够清晰明了,我还是作图吧。
等下,容我找找tgt在哪。
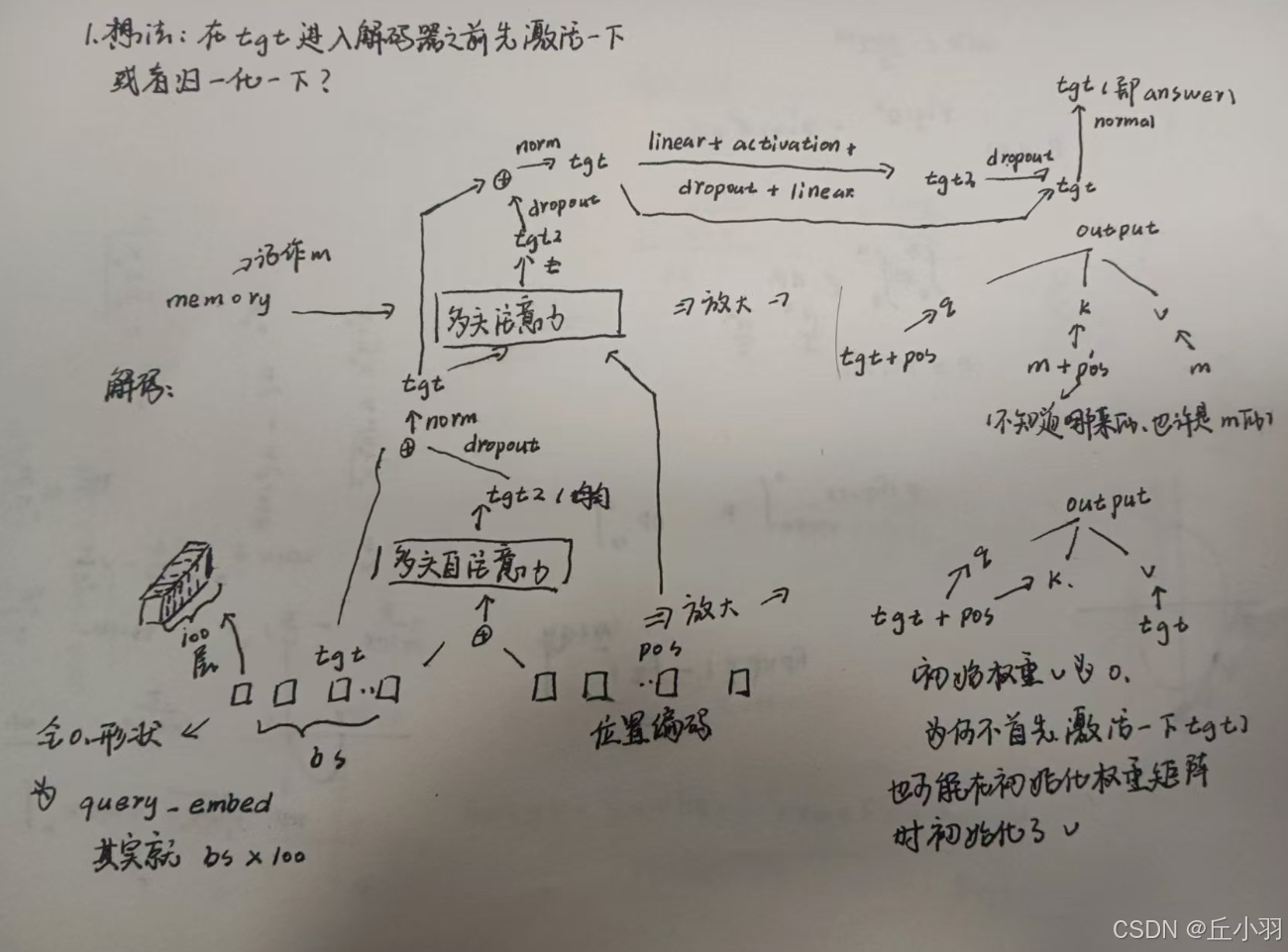
当然,这只是一层的输出,源码中是将每个层的输出都记录下来,得到6个输出后同样将第6层的结果再归一化,且记录下来,总的来说有7个输出。

有源码可知,最后通过一个线性层来预测得到种类:
运用三层感知机来预测边界框:
 。
。