scatterplot 是 seaborn 中用来绘制散点图的函数,其函数原型如下:
1. 函数签名(原型)
seaborn.scatterplot(data=None, *, x=None, y=None, hue=None, size=None, style=None, palette=None, hue_order=None, hue_norm=None, sizes=None, size_order=None, size_norm=None, markers=True, style_order=None, legend='auto', ax=None, **kwargs)
2. 输入参数
各个参数的类型、作用、默认值等解释如下:
| 参数 | 作用 | 类型 | 默认值 | 备注 |
|---|---|---|---|---|
data | 输入数据,包含绘制散点图所需的变量。可以是 DataFrame、数组或其他映射类型。 | pd.DataFrame, numpy.ndarray, mapping | None | 如果是 DataFrame,列名可以直接用作 x、y 等参数的变量名。 |
x | 确定横轴变量。 | str | None | 对应 data 中的一列。如果未指定,将根据输入数据自动选择(可能抛出异常)。 |
y | 确定纵轴变量。 | str | None | 同 x,对应该数据中的列。 |
hue | 分组变量,根据该变量生成不同颜色的点,用于区分不同类别。 | str | None | 对应 data 中的一列。若指定此参数,不同类别的点将被分配不同颜色。 |
size | 分组变量,根据该变量生成不同大小的点,用于区分不同数据点的权重或重要性。 | str | None | 对应 data 中的一列,适合用于表示连续值或类别值。 |
style | 分组变量,根据该变量生成不同形状的点,用于区分数据类别。 | str | None | 对应 data 中的一列,适合用于区分类别值。 |
palette | 调色板,用于控制颜色映射。可以是调色板名称、字典或回调函数。 | str, dict, callable | None | 如果 hue 是分类变量,默认使用分类调色板;如果是连续变量,默认使用渐变调色板。 |
hue_order | 自定义分类变量的绘图顺序(对于 hue 变量)。 | list | None | 如果不指定,顺序由输入数据中值的排序决定。 |
hue_norm | 对连续变量的颜色进行归一化,指定范围或归一化方式。 | tuple 或 Normalize 对象 | None | 适合处理连续变量的颜色映射,指定为 (min, max) 或 Normalize 对象。 |
sizes | 指定点大小的范围或映射方式,用于控制不同数据点的相对大小。 | tuple, dict, callable | None | 适用于指定 size 的场景,范围如 (min_size, max_size)。 |
size_order | 自定义分类变量的绘图顺序(对于 size 变量)。 | list | None | 与 hue_order 类似,但用于大小分类变量。 |
size_norm | 对连续变量的点大小进行归一化,指定范围或归一化方式。 | tuple 或 Normalize 对象 | None | 指定为 (min, max) 或 Normalize 对象,适合处理连续大小变量。 |
markers | 控制是否使用点的不同形状,或者自定义形状列表或字典。 | bool, list, dict | True | 如果是 True,将根据 style 使用默认形状;也可以指定形状列表或字典。 |
style_order | 自定义分类变量的绘图顺序(对于 style 变量)。 | list | None | 如果不指定,顺序由输入数据中值的排序决定。 |
legend | 控制图例的显示方式。 | 'auto', 'brief', 'full', 或 False | 'auto' | 'auto' 自动显示图例;False 不显示图例;其他值控制显示细节。 |
ax | 指定要绘制散点图的 Matplotlib 轴对象。 | matplotlib.axes.Axes | None | 如果未指定,默认在当前活动的轴上绘制图形。 |
**kwargs | 传递给 Matplotlib scatter 方法的其他参数,用于进一步定制图形外观。 | 其他类型 | N/A | 例如可以传递 alpha(透明度)、edgecolors(点边框颜色)等参数。 |
3. 示例解释
使用tips(小费)数据集作为演示:这是一个餐厅服务员收集的小费数据集,包含了7个变量:
总账单、小费、顾客性别、是否吸烟、日期、吃饭时间、顾客人数
tips = sns.load_dataset("tips")
tips.head()
# total_bill作为x轴,tip作为y轴绘制散点图
sns.scatterplot(data=tips, x="total_bill", y="tip")
# day作为x轴,tip作为y轴绘制散点图
sns.scatterplot(data=tips, x="day", y="tip")
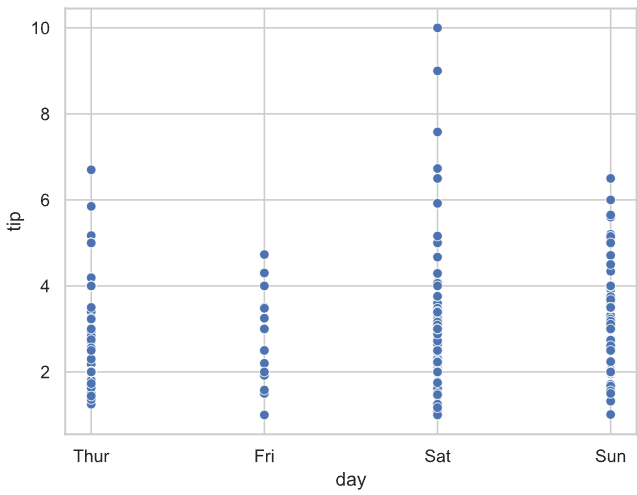
# total_bill作为x轴,tip作为y轴, day确定不同颜色绘制散点图
# 解读:横轴为total_bill,纵轴为tip,不同颜色代表不同day,比如蓝色代表Thur,红色代表Fri
sns.scatterplot(data=tips, x="total_bill", y="tip", hue='day')
# total_bill作为x轴,tip作为y轴, day确定不同颜色绘制散点图
# hue_order指定颜色顺序
# 解读:横轴为total_bill,纵轴为tip,不同颜色代表不同day,按照hue_order顺序,比如蓝色代表Sun,红色代表Fri
sns.scatterplot(data=tips, x="total_bill", y="tip", hue='day', hue_order=['Sun', 'Fri', 'Sat', 'Thur'])
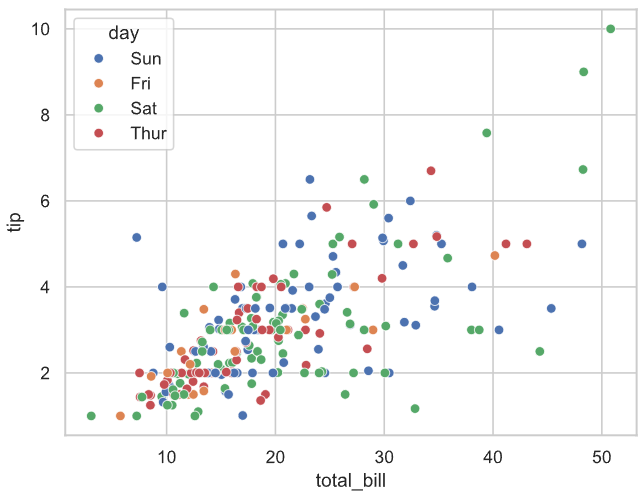
# total_bill作为x轴,tip作为y轴, day确定不同颜色,size确定不同大小绘制散点图
# 解读:横轴为total_bill,纵轴为tip,不同颜色代表不同day,不同大小代表不同size,
# 比如蓝色代表Sun,红色代表Fri,大一点的点代表sex为Female,小一点的点代表sex为Male
sns.scatterplot(data=tips, x="total_bill", y="tip", hue='day', size='sex')
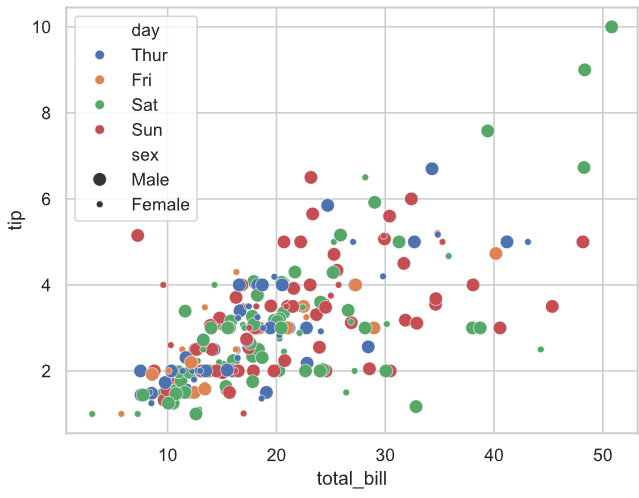
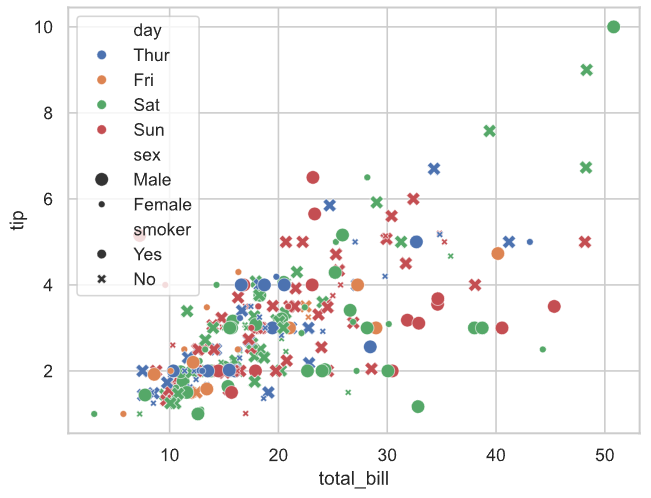
# total_bill作为x轴,tip作为y轴, day确定不同颜色,size确定不同大小,smoker确定不同形状绘制散点图
# 解读:横轴为total_bill,纵轴为tip,不同颜色代表不同day,不同大小代表不同性别,不同形状代表是否吸烟
# 比如:最右上角的点表示:星期六,男性,抽烟,账单为$50几,小费$10
sns.scatterplot(data=tips, x="total_bill", y="tip", hue='day', size='sex', style='smoker')
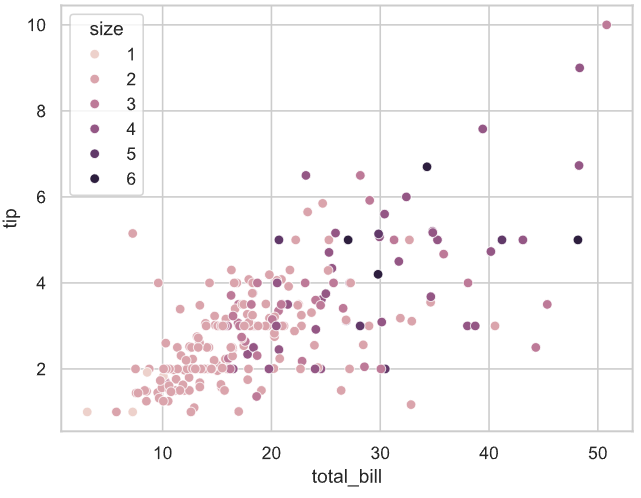
print('dtype of sex: ', tips['sex'].dtype)
print('dtype of size: ', tips['size'].dtype)
# dtype of sex: category
# dtype of size: int64
# 在绘制散点图时,如果分组变量hue的取值是category类型,则每一个类型采用不同颜色指示
# 如果是数值类型,则散点将会以颜色深浅对应数值大小进行表示
sns.scatterplot(data=tips, x='total_bill', y='tip', hue='size')
# 解释:size是一个数值类型,所以散点图的颜色深浅对应数值大小进行表示
# 也可以直接制定调色板(palette)来指定颜色,这里的deep是一个预定义的调色板
sns.scatterplot(data=tips, x="total_bill", y="tip", hue="size", palette="deep")
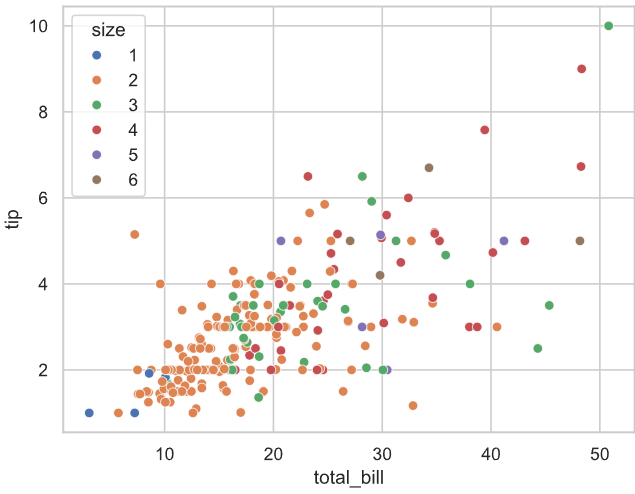
sns.scatterplot(data=tips, x='total_bill', y='tip', hue='size', palette='viridis')
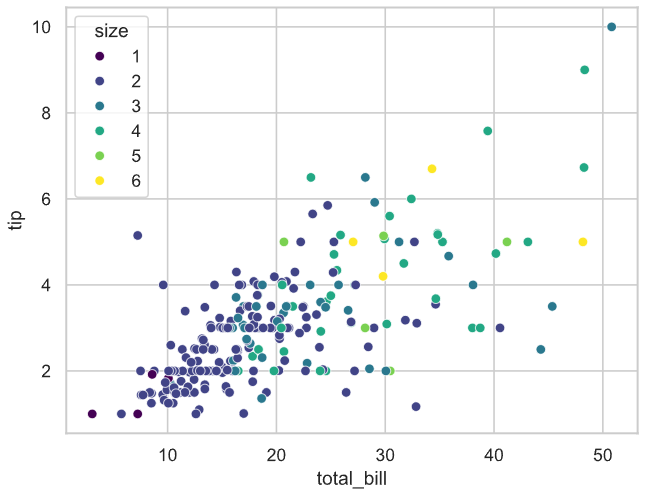
# 分组变量可以同时选定同一个变量,从而获得更强的区分度
# 这里,使用颜色和大小共同表示size这个变量,同时设置了大小的取值范围,从而使得散点图更加美观
sns.scatterplot(data=tips, x="total_bill", y="tip", hue="size", size="size",sizes=(20, 200), legend="full"
)
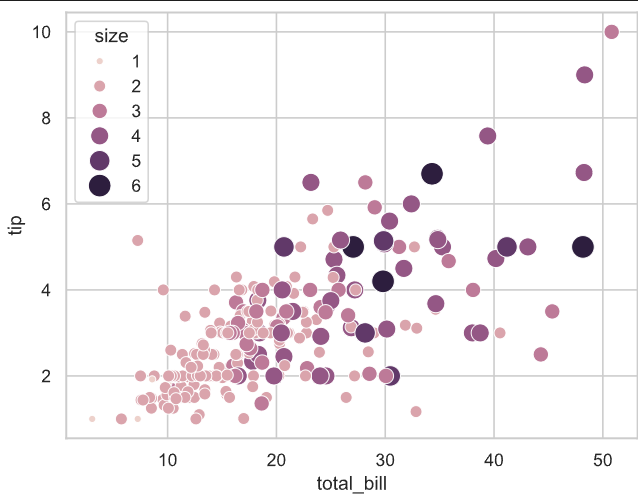
# hue_norm 用于调整颜色的映射范围,从而使得颜色和数值大小更加匹配
# hue_norm 用于规范化连续型 hue 变量的取值范围,以便将其映射到颜色空间中的特定区间。
# 它的数值范围通过一个元组 (min, max) 或 matplotlib.colors.Normalize 对象来定义。
# hue_norm=(min, max) 表示将 hue 变量的值按区间 [min, max] 映射到调色板的完整范围:
# 小于 min 的值会被视为调色板中的最小值颜色。
# 大于 max 的值会被视为调色板中的最大值颜色。
# 介于 min 和 max 之间的值按线性比例映射到调色板中的颜色。
# 默认为自动归一化,也即hue 的最小值和最大值映射到调色板的两端。
# 下面的代码展示的是默认行为
sns.scatterplot(data=tips, x="total_bill", y="tip", hue="size", size="size",sizes=(20, 200), hue_norm=(tips['size'].min(), tips['size'].max()), legend="full"
)
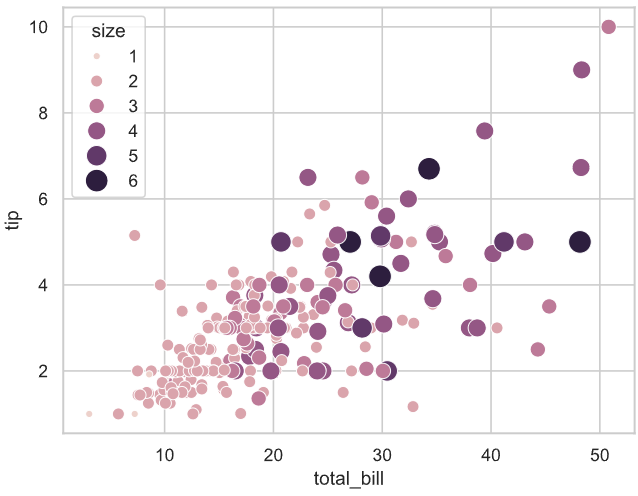
# 手动调整区间范围,也即会改变散点的对比度
sns.scatterplot(data=tips, x="total_bill", y="tip", hue="size", size="size",sizes=(20, 200), hue_norm=(0, 3), legend="full"
)
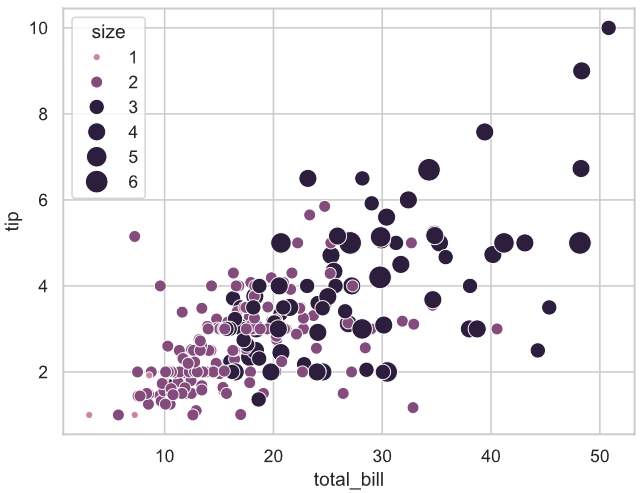
# 自定义形状映射关系
markers = {"Lunch": "s", "Dinner": "X"}
sns.scatterplot(data=tips, x="total_bill", y="tip", style="time", markers=markers)
import pandas as pd
import numpy as npindex = pd.date_range("1 1 2000", periods=100, freq="m", name="date")
data = np.random.randn(100, 4).cumsum(axis=0)
wide_df = pd.DataFrame(data=data, index=index, columns=["a", "b", "c", "d"])
sns.scatterplot(data=wide_df)
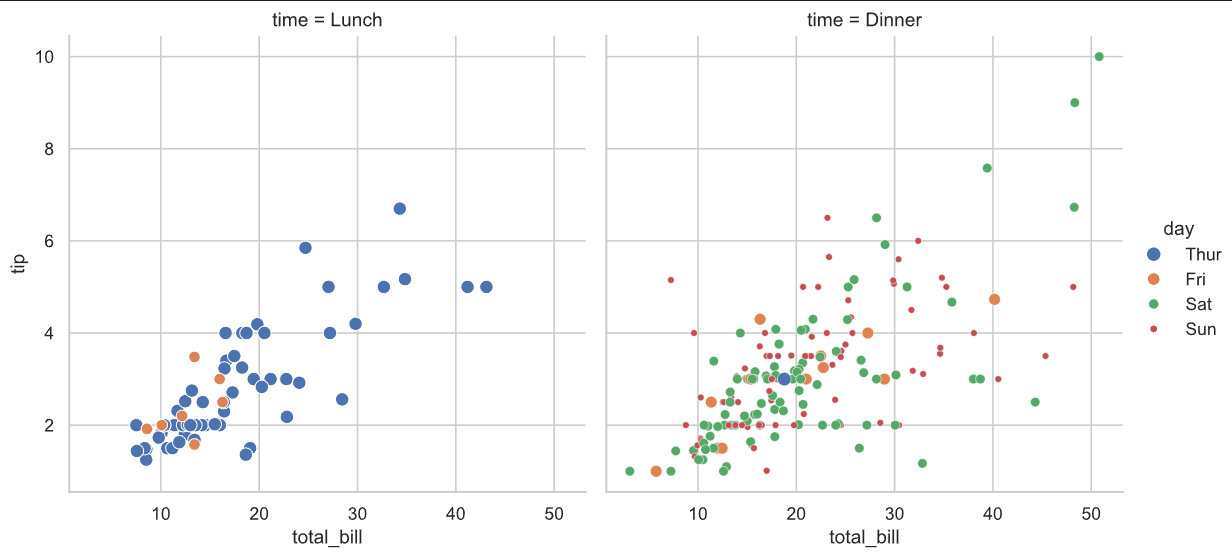
# relplot函数可以绘制多个变量之间的关系(relationship)
# 默认情况下,relplot函数会调用scatterplot函数绘制散点图
# relplot函数可以绘制多种类型的图表,包括散点图、线图、小提琴图、箱线图等
# relplot函数的好处是可以方便地绘制多个子图,通过调整row和col参数来指定子图的排列方式
# 比如下面的col='time'表示按照time变量来划分子图,每个子图表示一个time值
# 从下面的图形中可以分析得到,大部分的晚餐时间都是在周末,而午餐主要是在工作日
sns.relplot(data=tips, x="total_bill", y="tip",col="time", hue="day", size='day',kind="scatter"
)
参考内容:https://seaborn.pydata.org/generated/seaborn.scatterplot.html