heap4
从这个出发 先做出来 然后了解怎么实验对比 在改进 然后再做实验; //可以从多线程角度和ptmalloc角度去想咋设计
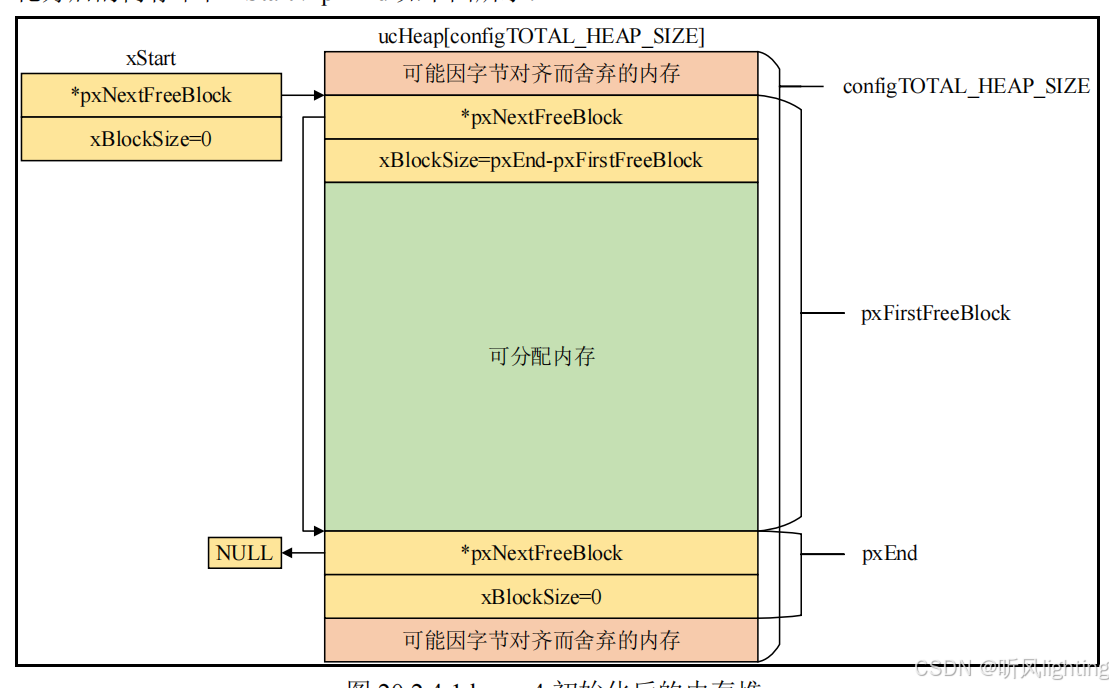
heap4.c 实际管理的是一个全局的大数组 static uint8_t ucHeap[ configTOTAL_HEAP_SIZE ];
xPortGetFreeHeapSize()获取内存堆中未分配的内存总量
结构体 struct A_BLOCK_LINK
typedef struct A_BLOCK_LINK
{// 指向下个空闲内存块struct A_BLOCK_LINK * pxNextFreeBlock; /*<< The next free block in the list. */// 最高位是标记 标记是不是用了这个内存块// size_t 的大小是最大就是 2的31次方减1// 所以整个算法内存支持的大小不超过 0x80000000字节size_t xBlockSize; /*<< The size of the free block. */
} BlockLink_t;
所以需要判断是不是超过了 0x80000000字节 也就是2GB
-
空闲链表
未分配的内存块构成空闲列表–刚开始就1项越来越多
而此时空闲列表是有顺序的 内存块起始地址越小越靠前–方便合并 -
prvHeapInit()函数
第一件事就是内存对齐 比如内存是按照8字节对齐的 就需要舍弃一些地址- 这个对齐有点妙的–只能是2的倍数情况下
- 假设对齐的是8字节 掩码就是7就是111 那8字节的整数倍和111按位与一定是0
- 如果不是0 先给他加上111 比如只有uxAddress = 0x1加上之后就是8 最起码够用
- 然后在和反转之后的按位与操作 去除掉低3位的值就可以了
uxAddress = ( size_t ) ucHeap;
if( ( uxAddress & portBYTE_ALIGNMENT_MASK ) != 0 )
{
uxAddress += ( portBYTE_ALIGNMENT - 1 );
uxAddress &= ~( ( size_t ) portBYTE_ALIGNMENT_MASK );
xTotalHeapSize -= uxAddress - ( size_t ) ucHeap;
}
pxStart不是第一块内存 而是指向了第一块空闲内存 也就是记录开头位置在哪里
xStart.pxNextFreeBlock = ( void * ) pucAlignedHeap;
xStart.xBlockSize = ( size_t ) 0;
而pxEnd不一样 他就是最后一块内存的地址 并标明下一块空闲内存是NULL - 这个对齐有点妙的–只能是2的倍数情况下
uxAddress = ( ( size_t ) pucAlignedHeap ) + xTotalHeapSize;uxAddress -= xHeapStructSize;uxAddress &= ~( ( size_t ) portBYTE_ALIGNMENT_MASK );pxEnd = ( void * ) uxAddress;pxEnd->xBlockSize = 0;pxEnd->pxNextFreeBlock = NULL;
这个xHeapStructSize也很有意思:
先加然后按位与
static const size_t xHeapStructSize = ( sizeof( BlockLink_t ) + ( ( size_t ) ( portBYTE_ALIGNMENT - 1 ) ) ) & ~( ( size_t ) portBYTE_ALIGNMENT_MASK );
- 空闲管理算法空闲块链表插入空闲内存块
prvInsertBlockIntoFreeList(),用于将空闲内存块插入空闲块链表
这个写一遍是最好使的
TLSF算法
TLSF(全称Two-Level Segregated Fit),从命名来看主要分为三部分
Segregated Free List
Two-Level Bitmap
Good Fit
分级空闲块链表(Segregated Free List)
-
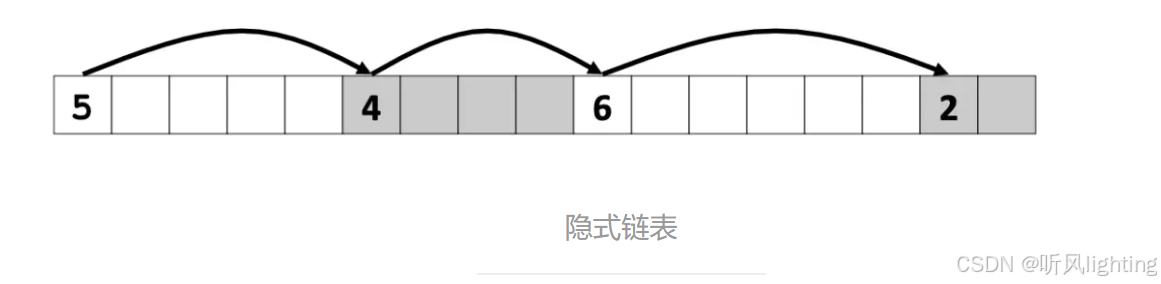
隐式链表–上面的heap4就是
连接所有内存块 只记录内存块大小 这样的话地址一加就知道下快内存在哪里了
不好的地方就是–分配内存就要从开始进行检索
上面的heap4.c就是 借助size的最高位实现了区分空闲与分空闲,但是分配的时候呢就得重新遍历一遍
-
fee List
把链表拿出来 显式空闲块列表 之指向空闲块

-
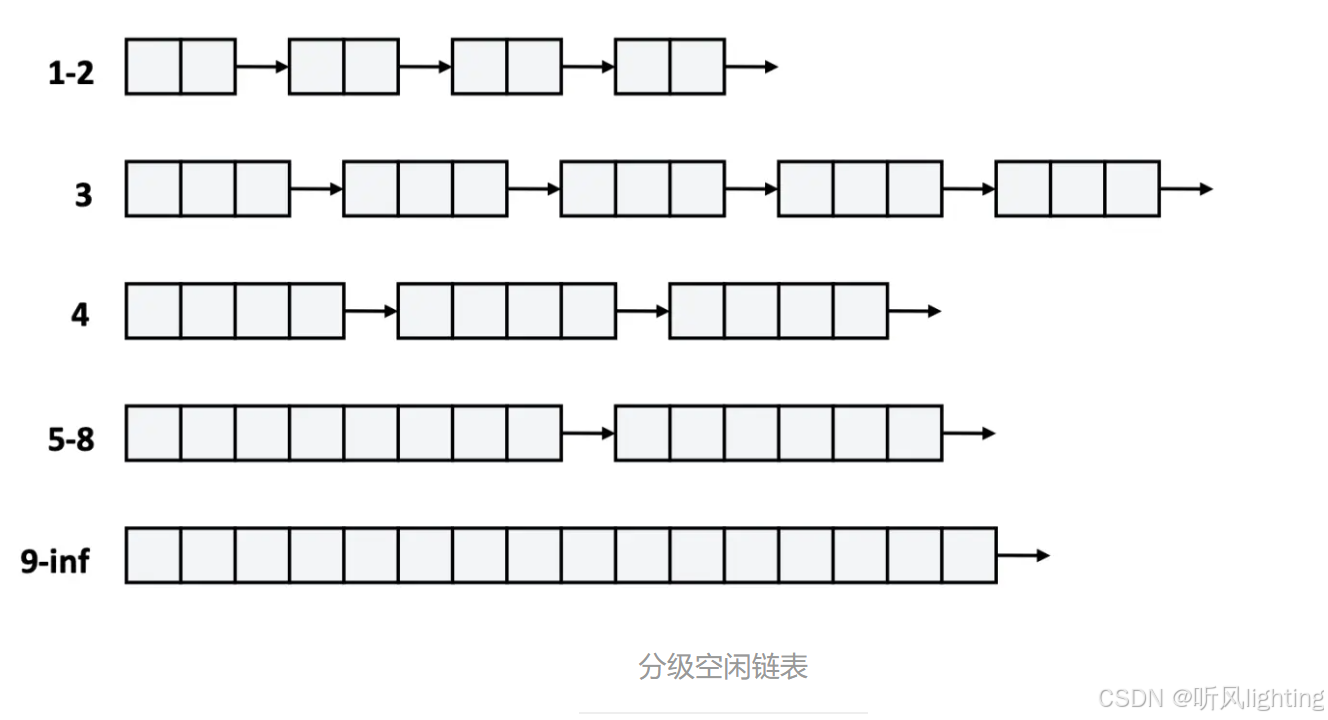
分块空闲链表
将空闲块按照大小分级 形成不同块的大小范围的分级
组内空闲块用链表连接起来 每次分配时按照分级大小查找相应链表
-
位图
操作1和0呗
TLSF大致了解
先是一个一级的bitmap fli 进行大小的粗了划分,每一位代表了具体的区间 比如[32,64]之类的
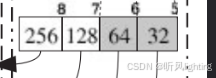
然后还有细分的二级bitmap sli [32-64]假设我分成了4 那就以4为区间进行划分,在细分的同时,如果内个区间有空闲内存块就把对应位置为1

然后二级bitmap还有一个用就是 链接了内些空闲块
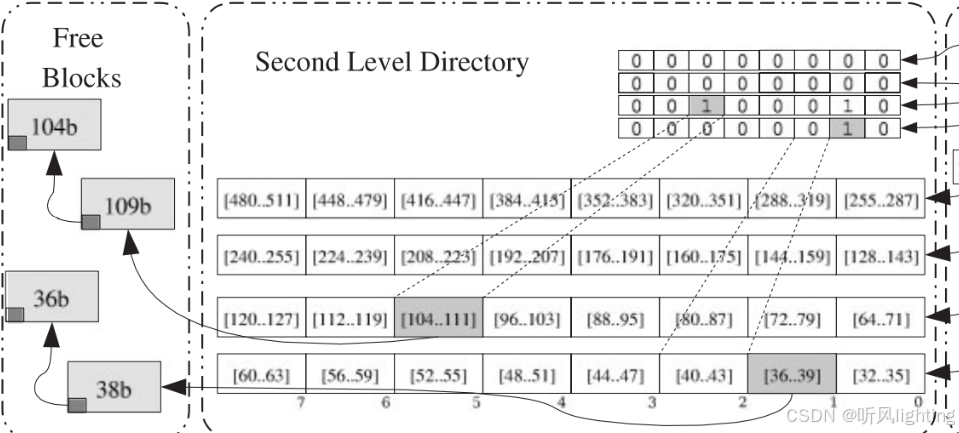
- malloc的过程
- mapping_search 调整size大小 并计算fli 和 sli的大小
针对源码讲解
针对源码讲解前先要了解一下这样几个特性
- struct block_header_t
typedef struct block_header_t{//prev_phys_block 是放在上一个空闲块的末尾的 如果上一个块不是空闲的 那prev_phy_block是无效的struct block_header_t* prev_phys_block;// 四字节对齐 永远是4的整数倍 所以后俩位肯定用不到// 因为这么操作了 后两位变成flag了 所以我们需要如下API// 1. 返回真正的block size// 2. 设置/查询 标志位1 第0位 当前快是否被使用// 3. 设置/查询 标志位2 第1位 上一块是否被使用uint32_t size;// 在物理空间上可是不相邻的 -- 这俩个在use状态下是无效的struct block_header_t* next_free;struct block_header_t* prev_free;}block_header_t;
- size大小到底是多大
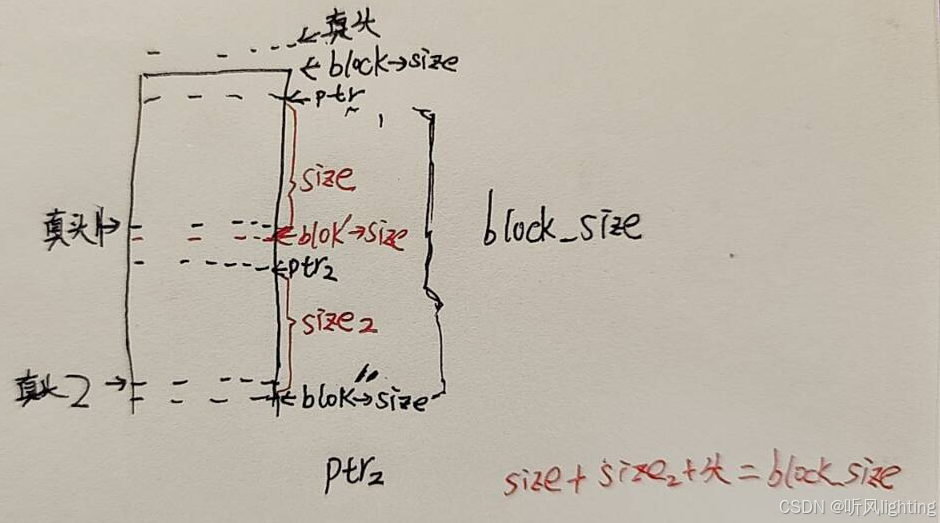
size大小是这么算的 我们把block_header_t->size 当做"头"(因为这个才是本内存块开头的位置)
size的大小等于 下个"头" - 本"头" - size成员变量本身占用的字节
比如block_header_t->size 是0x04 占用4个字节 那我们实际上的返回给程序的 ptr 就是 0x04 + 4 开始的
0x08 大小呢 按照我们说的size算法 正好就是 下个"头"的位置 这样就对上了 - block_to_ptr 从block真正的头到ptr需要多少
static void* block_to_ptr(const block_header_t* block){return tlsf_cast(void*,tlsf_cast(unsigned char*, block) + block_start_offset);}static const uint32_t block_start_offset =(uint32_t) offsetof(block_header_t, size) + sizeof(uint32_t);
现在这个操作就好理解了 先找到size这个成员变量的相对开始位置在哪里(实际上就是差了个pre_phys指针的大小) + size 成员变量占用的大小 这里是uint32_t
4. block_from_ptr – 类似的原理啦
static block_header_t* block_from_ptr(const void* ptr){// 就是在这个指针的基础上减去 偏移量return tlsf_cast(block_header_t*,tlsf_cast(unsigned char*, ptr) - block_start_offset);}
- 核心函数3 block_next函数
static const uint32_t block_header_overhead = sizeof(uint32_t);static block_header_t* block_next(const block_header_t* block){// 这里的计算就绕的离谱--画个图就能理解了block_header_t* next = offset_to_block(block_to_ptr(block),block_size(block) - block_header_overhead);configASSERT(!block_is_last(block));return next;}
为啥这么找到下个内存块呢 首先我们偏移到ptr指针后 我们偏移size大小 就找到了下一个内存块block->size的位置 此时我们再减去一个指针 pre_phy的大小block_header_overhead 才能找到下个block真正开头的位置啦
6. size_t
因为是32位的处理器这里我直接用的就是uint32_t 因为指针也就是32位 然后我把size 也强制为uint32_t 所以有些变量在64位时会变化—好好分析源程序就行
Init操作
- tlsf_create函数
首先第一件事把uHeap堆的开头穿进去之后 先做一下内存对齐的操作
然后对齐完之后呢 把头部control_t 结构体放到uHeap头部 —大概需要3KB 所以要注意heap的最低大小

-
tlsf_add_pool 函数
really_mem_start = tlsf_add_pool(tlsf_cast(tlsf_t,uxAddress), (char*)uxAddress + tlsf_size(), xTotalHeapSize - tlsf_size());
传入参数已经决定了进行了一定的修改–这是最后的结构
/*
±------------------+
| lv_tlsf_t | - control_t TLSF控制器
±------------------+ ---- firstblock->size的起始位置
| Block Header | - block_header_t 主空闲块块头 占了4个字节(size)
±------------------±----ptr 实际可以分配内存开始位置
| Main Free Block| - 主空闲块
±------------------+
| Block Header | - block_header_t 哨兵块块头 实际上只有一个指针占用4个字节?
±------------------±---- 最后四个字节给dummy->size
| Sentinel Block | - 哨兵块 size = 0 哨兵块是使用的 所以next_free和 prev_free没用
*/ -
为啥overhead是两个size_t的大小呢?
首先对于Block head 他的pre_phy不是应该由上一块保存吗? 但是对于第一块MainFreeBlock 哪来的上一块 所以需要一个size 大小表示内存块多大就行 --pre_phy用不着
对于最后一个内存块dummy表示尾部 此时 也是只有一个size成员变量就行 因为dummy->pre_phy在MainFree Block的末尾保留着呢

所以实际pool可用的内存根据画的图也能看出来 需要减去2个字节
然后就是初始化size–主内存块的操作

借助上面分析的函数找到 duumy的开头位置(pre_phy同在的位置)–设置一些参数 主要是size的妙用所以巴拉巴拉

-
示意图

我们可以借助keil5的调试看看我们分析的对不对
-
keil5调试图
ucHeap:0x20007FF4 大小是0x3C00 所以末端是0x2000BBF4
实际mem开始的地址是0x2008C68 因为tlfs控制器用掉了3180
block = offset_to_block(mem, -(tlsfptr_t)block_header_overhead);
算出来block的起始地址是8c64 那是不是正好block_size的地址就是mem的开始地址 8c68

next的开始地址是0x200BBEC 所以他的size在的位置是 0X2000BBF0
哎这样是不是就对了 size占用4个字节 正好就是uHeap末端的0x2000BBF4
此时0x200BBF0 - 0X20008C68 = 2F88 两个假"头"相减的大小
但是实际上呢 ptr是在 0x20008c68 + 4的位置开始的–花的示意图
所以pool_bytes 就是0x2F84 正好差了 firstBlock的size大小
就对上了
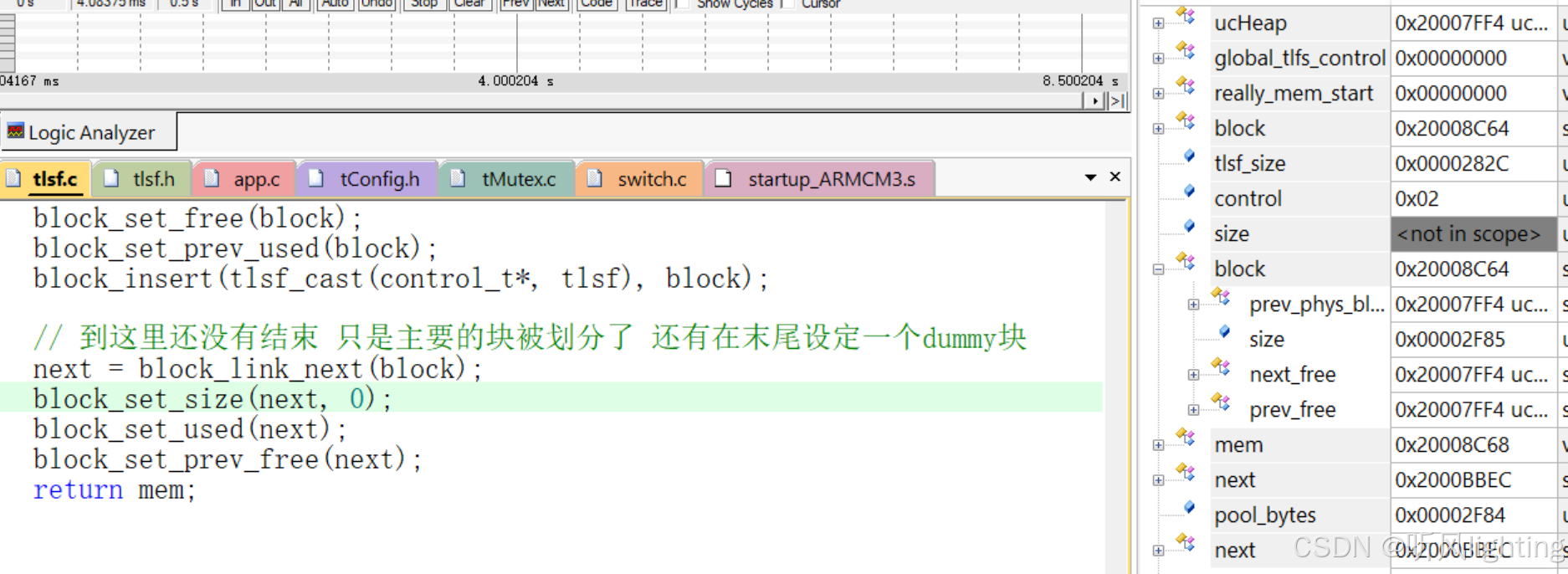
malloc 操作

-
block_locate_free操作
mapping search 和 mapping insert 是两个算法 呃呃反正就是找到fl和sl 算法U1S1 看不懂不讲了
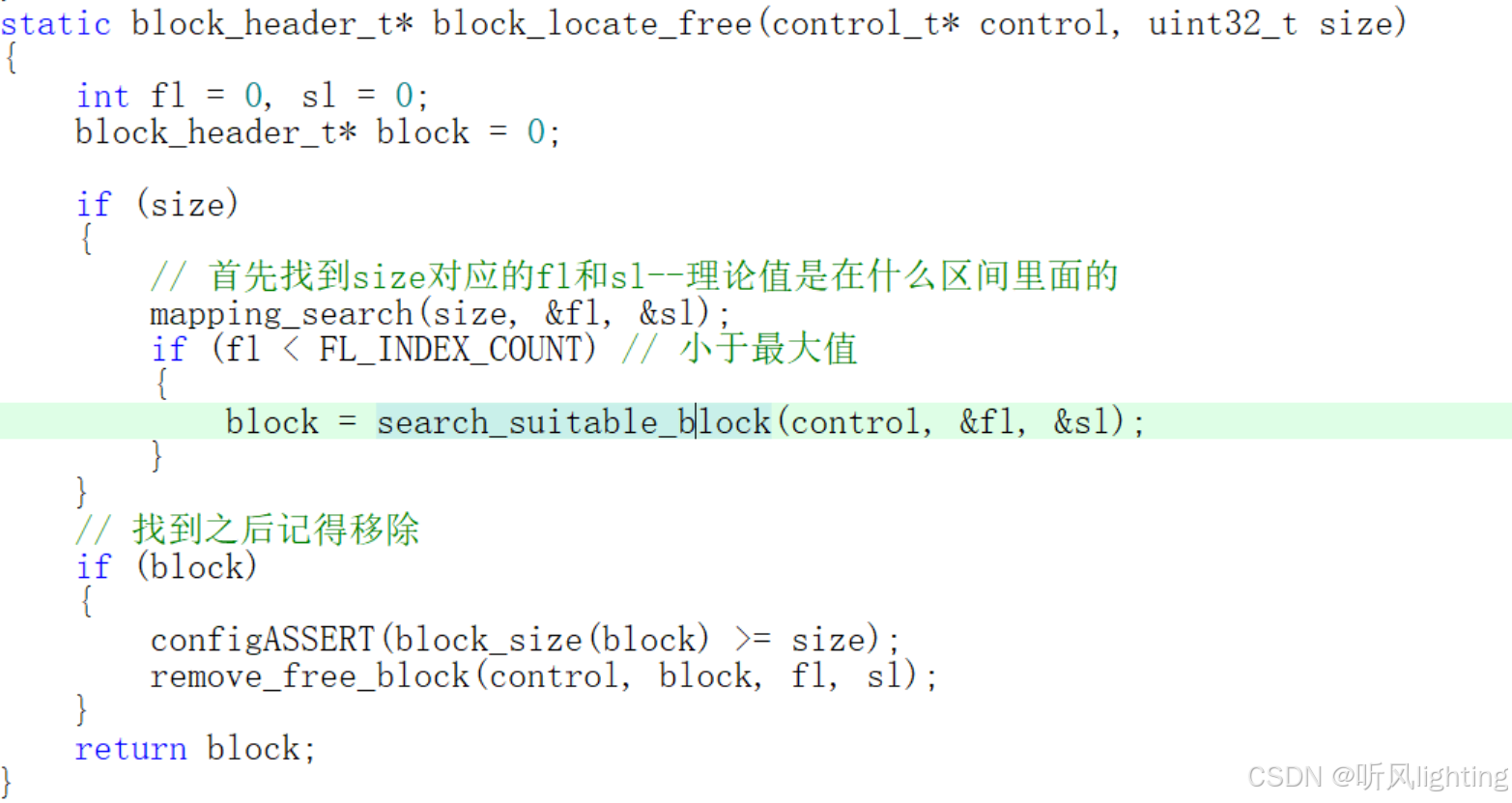
- search_suitable_block函数
注释说的很明白了
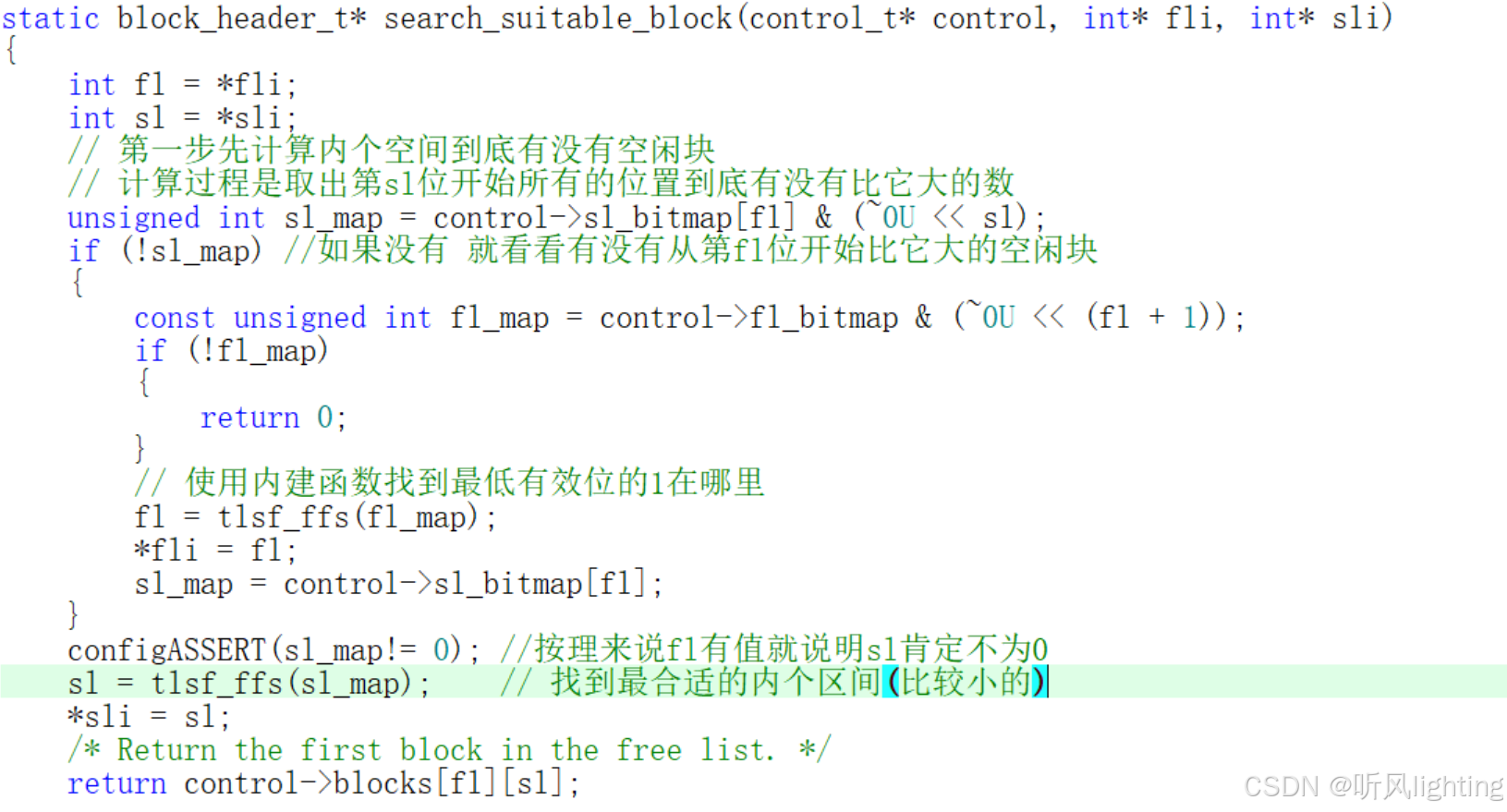
- search_suitable_block函数
-
block_prepare_used函数
两个功能 第一个是过大了就分割一下该块(比如第一次的时候是不是还得把大内存块切割)–放入指定位置
第二个就是把这个块标记为已使用

-
block_trim_free–核心的核心就是这个split函数
分割的时候假设的是两个块都是空闲的 至于说block被用了 那在调用完之后再设置标志位呗

-
block_split函数
-
static block_header_t* block_split(block_header_t* block, uint32_t size){// 这一步的意思是找到remainning 的 block_header_t* 开头位置 这个操作前面遇到很多次了 就和size的大小有关block_header_t* remaining =offset_to_block(block_to_ptr(block), size - block_header_overhead);//? 为啥是这么大呢 还要减去overhead--这个画个图就好理解了const uint32_t remain_size = block_size(block) - (size + block_header_overhead);configASSERT(block_to_ptr(remaining) == align_ptr(block_to_ptr(remaining), ALIGN_SIZE));configASSERT(block_size(block) == remain_size + size + block_header_overhead);block_set_size(remaining, remain_size);configASSERT(block_size(remaining) >= block_size_min);// 把block的大小重新设置一下 并把remain标记为freeblock_set_size(block, size);block_mark_as_free(remaining);return remaining;}
因为你每次分割的时候都得给size单独留出4字节用来保存到底这个ptr指针能操作的内存有多少
malloc操作总结就是:
- 调整size
- 找到适合的空闲块或者是为了满足分配比较大的空闲块 并从fl sl移除该块后记得更新位图
- 对于此时的空闲块 过大了就先切割成2块 一块标记为已使用,另一块标记为空闲之后 放入fl sl对应的位置 放入指定位置的时候由于是空闲块所以操作的是双向链表指针 struct block_header_t* next_free; struct block_header_t* prev_free;
- 返回该块实际的ptr指针位置
- 运行结果示例分析
free操作
-
tlsf_free(tlsf_t tlsf, void* ptr)函数
核心是 block_merge_prev 和 block_merge_next 下的absorb函数

-
block_merge_prev函数

-
block_absorb函数 merge的核心
static block_header_t* block_absorb(block_header_t* prev, block_header_t* block){configASSERT(!block_is_last(prev));//prev的size变大了--这个计算也很有意思//就差这个没看懂了prev->size += block_size(block) + block_header_overhead;// 注意prev的size变了 这里实际上是吧block的next的prev指向給变了一下block_link_next(prev);return prev;}
- 运行结果示例
测试
-
tlsf是不是good fit
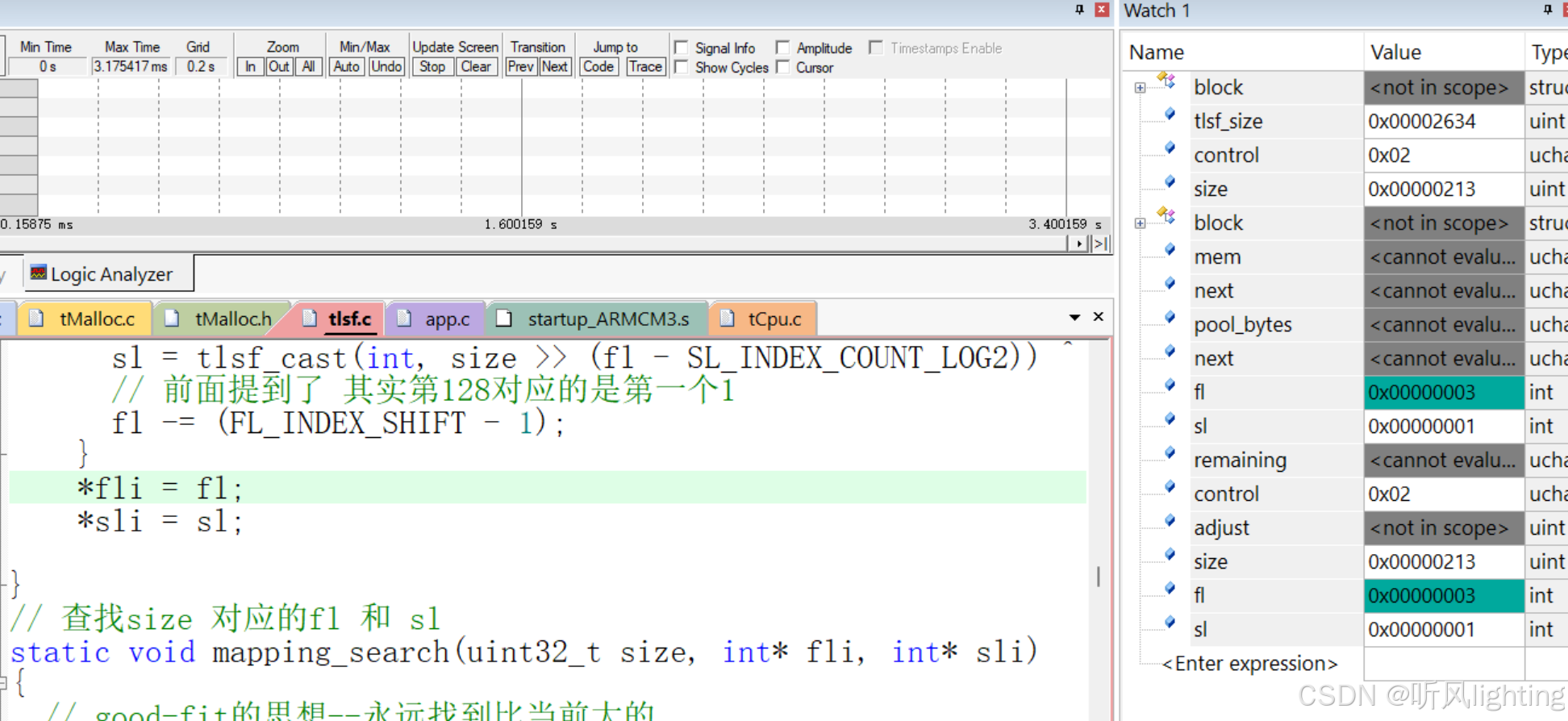
当我们分配 129内存–4字节对齐先变成132
最终结果fl = 1 s1 = 1 此时的区间是132-135 刚刚好
那假如是 514个字节呢
514-被对齐成516 fl = 3 sl = 1
但是实际上 fl = 3 sl = 0 对应的是512-527 也就是说 直接去 528-544字节区间找的块
所以会有一定的内存碎片的
-
tlsf是分配快还是释放快
-
测试单个的
分配前的时间分配后的时间 0.164583 - 0.124833 = 0.03975 ms
准备释放前的时间
释放后的时间 0.169833 - 0.164583 = 0.00525 ms
-
分配多个一样大小的的 --测试一下
int * result[10];
tSetSysTickPeriod(10);
for(stopped = 0;stopped < 10; stopped++)
result[stopped] = (int *)pvPortMalloc(1024);
for(stopped = 0;stopped < 10; stopped++)
vPortFree(result[stopped]);分配花费的时间 0.22675 - 0.124667 = 0.102083ms
释放花费的时间 0.27975 - 0.22675 = 0.053 ms -
分配不一样大小的每个区间各一个
分配需要的时间 0.19925 - 0.125083 = 0.074167 ms

0.230917 - 0.19925 = 0.031667 ms
想想也是分配还挺费劲的 时间肯定比释放要长
3. 我们试一试heap4做一样的操作要多久
-
分配一块
0.125167 0.12725 = 0.002083ms 这咋heap4 全程把tlsf爆了啊 -
分配一样的
0.125167 0.141833 0.159833
0.016666ms 0.018ms 感觉确实把tlsf爆了 -
分配不一样的
0.125167 – 0.136667 – 0.146333
分配耗时:0.011503 ms ? 更短 0.0115 ms
0.146333 - 0.136667 0.009666ms
阿哲怎么看起来heap4更胜一筹 难道是因为刚开始的原因所以heap4 快是吗
为啥会和实际不一样呢因为 tlsf的优势应该是内存碎片较多的时候把