当列表不是首选时
虽然列表既灵活又简单,但面对各类需求时,我们可能会有更好的选
择。比如,要存放 1000 万个浮点数的话,数组(array)的效率要高
得多,因为数组在背后存的并不是 float 对象,而是数字的机器翻
译,也就是字节表述。这一点就跟 C 语言中的数组一样。再比如说,如
果需要频繁对序列做先进先出的操作,deque(双端队列)的速度应该
会更快。
如果在你的代码里,包含操作(比如检查一个元素是否出现
在一个集合中)的频率很高,用 set(集合)会更合适。set 专为
检查元素是否存在做过优化。但是它并不是序列,因为 set 是无序
的。
数组
如果我们需要一个只包含数字的列表,那么 array.array 比 list 更
高效。数组支持所有跟可变序列有关的操作,包括 .pop、.insert 和
.extend。另外,数组还提供从文件读取和存入文件的更快的方法,如
.frombytes 和 .tofile。
Python 数组跟 C 语言数组一样精简。创建数组需要一个类型码,这个类
型码用来表示在底层的 C 语言应该存放怎样的数据类型。比如 b 类型码
代表的是有符号的字符(signed char),因此 array(‘b’) 创建出的
数组就只能存放一个字节大小的整数,范围从 -128 到 127,这样在序列
很大的时候,我们能节省很多空间。而且 Python 不会允许你在数组里存
放除指定类型之外的数据。
示例 2-20 展示了从创建一个有 1000 万个随机浮点数的数组开始,到如
何把这个数组存放到文件里,再到如何从文件读取这个数组。
示例 2-20 一个浮点型数组的创建、存入文件和从文件读取的过程
>>> from array import array ➊
>>> from random import random
>>> floats = array('d', (random() for i in range(10**7))) ➋
>>> floats[-1] ➌
0.07802343889111107
>>> fp = open('floats.bin', 'wb')
>>> floats.tofile(fp) ➍
>>> fp.close()
>>> floats2 = array('d') ➎
>>> fp = open('floats.bin', 'rb')
>>> floats2.fromfile(fp, 10**7) ➏
>>> fp.close()
>>> floats2[-1] ➐
0.07802343889111107
>>> floats2 == floats ➑
True
❶ 引入 array 类型。
❷ 利用一个可迭代对象来建立一个双精度浮点数组(类型码是 ‘d’),
这里我们用的可迭代对象是一个生成器表达式。
❸ 查看数组的最后一个元素。
❹ 把数组存入一个二进制文件里。
❺ 新建一个双精度浮点空数组。
❻ 把 1000 万个浮点数从二进制文件里读取出来。
❼ 查看新数组的最后一个元素。
❽ 检查两个数组的内容是不是完全一样。
从上面的代码我们能得出结论,array.tofile 和 array.fromfile 用
起来很简单。把这段代码跑一跑,你还会发现它的速度也很快。一个小
试验告诉我,用 array.fromfile 从一个二进制文件里读出 1000 万个
双精度浮点数只需要 0.1 秒,这比从文本文件里读取的速度要快 60
倍,因为后者会使用内置的 float 方法把每一行文字转换成浮点数。
另外,使用 array.tofile 写入到二进制文件,比以每行一个浮点数的
方式把所有数字写入到文本文件要快 7 倍。另外,1000 万个这样的数
在二进制文件里只占用 80 000 000 个字节(每个浮点数占用 8 个字节,
不需要任何额外空间),如果是文本文件的话,我们需要 181 515 739
个字节。
另外一个快速序列化数字类型的方法是使用
pickle(https://docs.python.org/3/library/pickle.html)模
块。pickle.dump 处理浮点数组的速度几乎跟 array.tofile 一
样快。不过前者可以处理几乎所有的内置数字类型,包含复数、嵌
套集合,甚至用户自定义的类。前提是这些类没有什么特别复杂的
实现。
还有一些特殊的数字数组,用来表示二进制数据,比如光栅图像。里面
涉及的 bytes 和 bytearry 类型会在第 4 章提及。
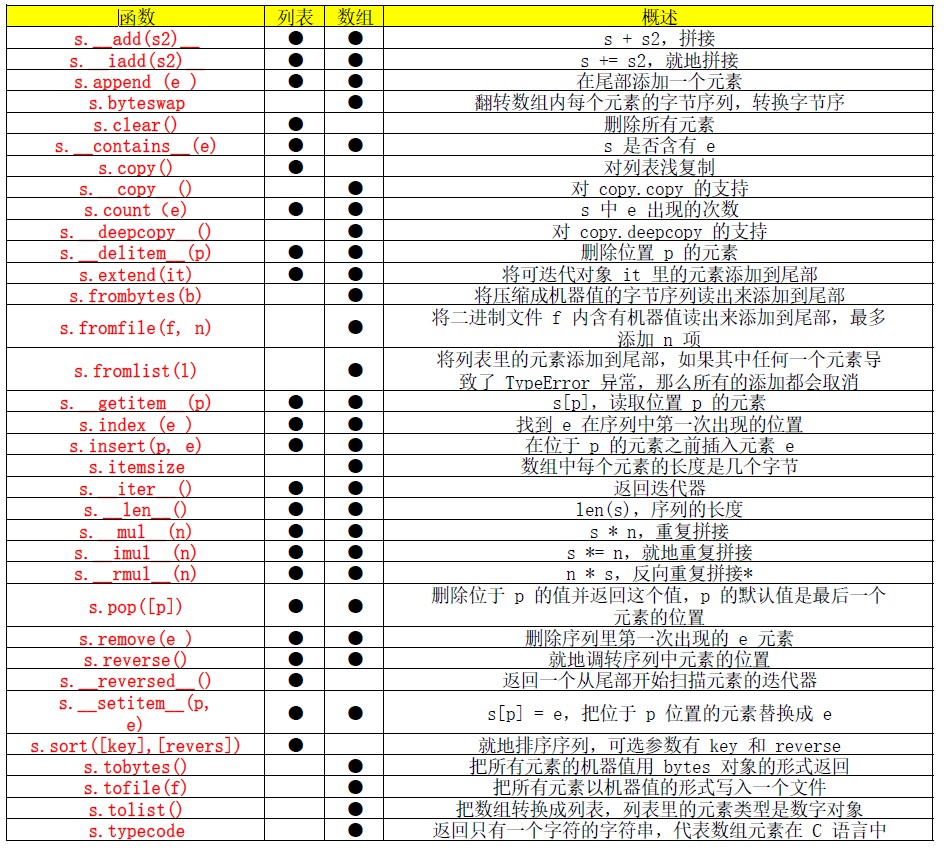
表 2-2 对数组和列表的功能做了一些总结。
表2-2:列表和数组的属性和方法(不包含过期的数组方法以及那些
由对象实现的方法)
从 Python 3.4 开始,数组类型不再支持诸如 list.sort() 这种就地
排序方法。要给数组排序的话,得用 sorted 函数新建一个数组:
a = array.array(a.typecode, sorted(a))
想要在不打乱次序的情况下为数组添加新的元素,bisect.insort
还是能派上用场
如果你总是跟数组打交道,却没有听过 memoryview,那就太遗憾了。
下面就来谈谈 memoryview。
内存视图
memoryview 是一个内置类,它能让用户在不复制内容的情况下操作同
一个数组的不同切片。memoryview 的概念受到了 NumPy 的启发(参见
2.9.3 节)。Travis Oliphant 是 NumPy 的主要作者,他在回答“ When
should a memoryview be
used?”(http://stackoverflow.com/questions/4845418/when-should-amemoryview-
be-used/)这个问题时是这样说的:
内存视图其实是泛化和去数学化的 NumPy 数组。它让你在不需要
复制内容的前提下,在数据结构之间共享内存。其中数据结构可以
是任何形式,比如 PIL 图片、SQLite 数据库和 NumPy 的数组,等
等。这个功能在处理大型数据集合的时候非常重要。
memoryview.cast 的概念跟数组模块类似,能用不同的方式读写同一
块内存数据,而且内容字节不会随意移动。这听上去又跟 C 语言中类型
转换的概念差不多。memoryview.cast 会把同一块内存里的内容打包成一个全新的 memoryview 对象给你。
在示例 2-21 里,我们利用 memoryview 精准地修改了一个数组的某个
字节,这个数组的元素是 16 位二进制整数。
示例 2-21 通过改变数组中的一个字节来更新数组里某个元素的值
>>> numbers = array.array('h', [-2, -1, 0, 1, 2])
>>> memv = memoryview(numbers) ➊
>>> len(memv)
5 >>> memv[0] ➋
-2
>>> memv_oct = memv.cast('B') ➌
>>> memv_oct.tolist() ➍
[254, 255, 255, 255, 0, 0, 1, 0, 2, 0]
>>> memv_oct[5] = 4 ➎
>>> numbers
array('h', [-2, -1, 1024, 1, 2]) ➏
❶ 利用含有 5 个短整型有符号整数的数组(类型码是 ‘h’)创建一个
memoryview。
❷ memv 里的 5 个元素跟数组里的没有区别。
❸ 创建一个 memv_oct,这一次是把 memv 里的内容转换成 ‘B’ 类型,
也就是无符号字符。
❹ 以列表的形式查看 memv_oct 的内容。
❺ 把位于位置 5 的字节赋值成 4。
❻ 因为我们把占 2 个字节的整数的高位字节改成了 4,所以这个有符号
整数的值就变成了 1024。
在第 4 章的示例 4-4 中,我们还可以看到如何利用 memoryview 和
struct 来操作二进制序列。
另外,如果利用数组来做高级的数字处理是你的日常工作,那么 NumPy
和 SciPy 应该是你的常用武器。下面就是对这两个库的简单介绍。
NumPy和SciPy
整本书我都在强调如何最大限度地利用 Python 标准库。但是 NumPy 和
SciPy 的优秀让我觉得偶尔跑个题来谈谈它们也是很值得的。
凭借着 NumPy 和 SciPy 提供的高阶数组和矩阵操作,Python 成为科学计
算应用的主流语言。NumPy 实现了多维同质数组(homogeneous array)
和矩阵,这些数据结构不但能处理数字,还能存放其他由用户定义的记
录。通过 NumPy,用户能对这些数据结构里的元素进行高效的操作。
SciPy 是基于 NumPy 的另一个库,它提供了很多跟科学计算有关的算
法,专为线性代数、数值积分和统计学而设计。SciPy 的高效和可靠性
归功于其背后的 C 和 Fortran 代码,而这些跟计算有关的部分都源自于
Netlib 库(http://www.netlib.org)。换句话说,SciPy 把基于 C 和 Fortran
的工业级数学计算功能用交互式且高度抽象的 Python 包装起来,让科学
家如鱼得水。
示例 2-22 是一个很简短的演示,从中可以窥见一些 NumPy 二维数组的
基本操作。
示例 2-22 对 numpy.ndarray 的行和列进行基本操作
>>> import numpy ➊
>>> a = numpy.arange(12) ➋
>>> a
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
>>> type(a)
<class 'numpy.ndarray'>
>>> a.shape ➌
(12,)
>>> a.shape = 3, 4 ➍
>>> a
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
>>> a[2] ➎
array([ 8, 9, 10, 11])
>>> a[2, 1] ➏
9 >>> a[:, 1] ➐
array([1, 5, 9])
>>> a.transpose() ➑
array([[ 0, 4, 8],
[ 1, 5, 9],
[ 2, 6, 10],
[ 3, 7, 11]])
❶ 安装 NumPy 之后,导入它(NumPy 并不是 Python 标准库的一部
分)。
❷ 新建一个 0~11 的整数的 numpy.ndarry,然后把它打印出来。
❸ 看看数组的维度,它是一个一维的、有 12 个元素的数组。
❹ 把数组变成二维的,然后把它打印出来看看。
❺ 打印出第 2 行。
❻ 打印第 2 行第 1 列的元素。
❼ 把第 1 列打印出来。
❽ 把行和列交换,就得到了一个新数组。
NumPy 也可以对 numpy.ndarray 中的元素进行抽象的读取、保存和其
他操作:
>>> import numpy
>>> floats = numpy.loadtxt('floats-10M-lines.txt') ➊
>>> floats[-3:] ➋
array([ 3016362.69195522, 535281.10514262, 4566560.44373946])
>>> floats *= .5 ➌
>>> floats[-3:]
array([ 1508181.34597761, 267640.55257131, 2283280.22186973])
>>> from time import perf_counter as pc ➍
>>> t0 = pc(); floats /= 3; pc() - t0 ➎
0.03690556302899495
>>> numpy.save('floats-10M', floats) ➏
>>> floats2 = numpy.load('floats-10M.npy', 'r+') ➐
>>> floats2 *= 6
>>> floats2[-3:] ➑
memmap([3016362.69195522, 535281.10514262, 4566560.44373946])
❶ 从文本文件里读取 1000 万个浮点数。
❷ 利用序列切片来读取其中的最后 3 个数。
❸ 把数组里的每个数都乘以 0.5,然后再看看最后 3 个数。
❹ 导入精度和性能都比较高的计时器(Python 3.3 及更新的版本中都有
这个库)。
❺ 把每个元素都除以 3,可以看到处理 1000 万个浮点数所需的时间还
不足 40 毫秒。
❻ 把数组存入后缀为 .npy 的二进制文件。
❼ 将上面的数据导入到另外一个数组里,这次 load 方法利用了一种叫
作内存映射的机制,它让我们在内存不足的情况下仍然可以对数组做切
片。
❽ 把数组里每个数乘以 6 之后,再检视一下数组的最后 3 个数。
双向队列和其他形式的队列
利用 .append 和 .pop 方法,我们可以把列表当作栈或者队列来用(比
如,把 .append 和 .pop(0) 合起来用,就能模拟栈的“先进先出”的特
点)。但是删除列表的第一个元素(抑或是在第一个元素之前添加一个
元素)之类的操作是很耗时的,因为这些操作会牵扯到移动列表里的所
有元素。
collections.deque 类(双向队列)是一个线程安全、可以快速从两
端添加或者删除元素的数据类型。而且如果想要有一种数据类型来存
放“最近用到的几个元素”,deque 也是一个很好的选择。这是因为在新
建一个双向队列的时候,你可以指定这个队列的大小,如果这个队列满
员了,还可以从反向端删除过期的元素,然后在尾端添加新的元素。示
例 2-23 中有几个双向队列的典型操作。
示例 2-23 使用双向队列
>>> from collections import deque
>>> dq = deque(range(10), maxlen=10) ➊
>>> dq
deque([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], maxlen=10)
>>> dq.rotate(3) ➋
>>> dq
deque([7, 8, 9, 0, 1, 2, 3, 4, 5, 6], maxlen=10)
>>> dq.rotate(-4)
>>> dq
deque([1, 2, 3, 4, 5, 6, 7, 8, 9, 0], maxlen=10)
>>> dq.appendleft(-1) ➌
>>> dq
deque([-1, 1, 2, 3, 4, 5, 6, 7, 8, 9], maxlen=10)
>>> dq.extend([11, 22, 33]) ➍
>>> dq
deque([3, 4, 5, 6, 7, 8, 9, 11, 22, 33], maxlen=10)
>>> dq.extendleft([10, 20, 30, 40]) ➎
>>> dq
deque([40, 30, 20, 10, 3, 4, 5, 6, 7, 8], maxlen=10)
❶ maxlen 是一个可选参数,代表这个队列可以容纳的元素的数量,而且一旦设定,这个属性就不能修改了。
❷ 队列的旋转操作接受一个参数 n,当 n > 0 时,队列的最右边的 n
个元素会被移动到队列的左边。当 n < 0 时,最左边的 n 个元素会被
移动到右边。
❸ 当试图对一个已满(len(d) == d.maxlen)的队列做尾部添加操作
的时候,它头部的元素会被删除掉。注意在下一行里,元素 0 被删除
了。
❹ 在尾部添加 3 个元素的操作会挤掉 -1、1 和 2。
❺ extendleft(iter) 方法会把迭代器里的元素逐个添加到双向队列
的左边,因此迭代器里的元素会逆序出现在队列里。
表 2-3 总结了列表和双向队列这两个类型的方法(object 类包含的方
法除外)。
双向队列实现了大部分列表所拥有的方法,也有一些额外的符合自身设
计的方法,比如说 popleft 和 rotate。但是为了实现这些方法,双向
队列也付出了一些代价,从队列中间删除元素的操作会慢一些,因为它
只对在头尾的操作进行了优化。
append 和 popleft 都是原子操作,也就说是 deque 可以在多线程程序
中安全地当作先进先出的栈使用,而使用者不需要担心资源锁的问题。
表2-3:列表和双向队列的方法(不包括由对象实现的方法)
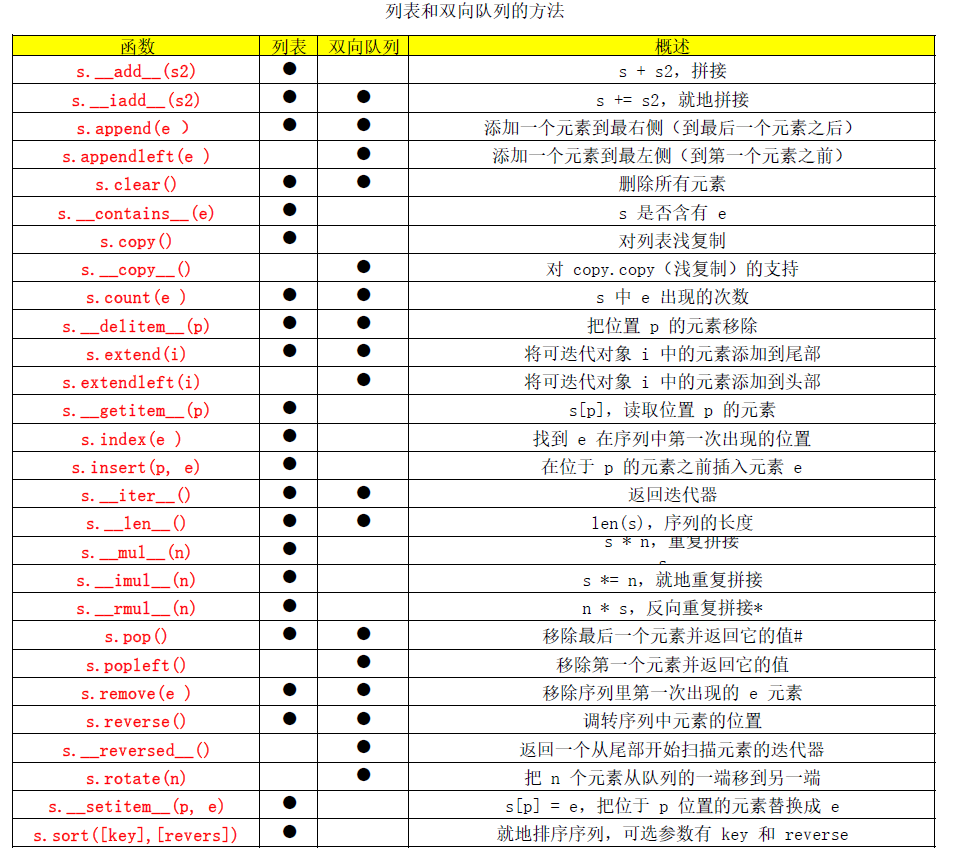
# a_list.pop§ 这个操作只能用于列表,双向队列的这个方法不接收参数。
除了 deque 之外,还有些其他的 Python 标准库也有对队列的实现。
queue
提供了同步(线程安全)类 Queue、LifoQueue 和
PriorityQueue,不同的线程可以利用这些数据类型来交换信息。这三
个类的构造方法都有一个可选参数 maxsize,它接收正整数作为输入
值,用来限定队列的大小。但是在满员的时候,这些类不会扔掉旧的元
素来腾出位置。相反,如果队列满了,它就会被锁住,直到另外的线程
移除了某个元素而腾出了位置。这一特性让这些类很适合用来控制活跃
线程的数量。
multiprocessing
这个包实现了自己的 Queue,它跟 queue.Queue 类似,是设计给
进程间通信用的。同时还有一个专门的
multiprocessing.JoinableQueue 类型,可以让任务管理变得更方
便。
asyncio
Python 3.4 新提供的包,里面有
Queue、LifoQueue、PriorityQueue 和 JoinableQueue,这些类受
到 queue 和 multiprocessing 模块的影响,但是为异步编程里的任务
管理提供了专门的便利。
heapq
跟上面三个模块不同的是,heapq 没有队列类,而是提供了
heappush 和 heappop 方法,让用户可以把可变序列当作堆队列或者优
先队列来使用。
到了这里,我们对列表之外的类的介绍也就告一段落了,是时候阶段性
地总结一下对序列类型的探索了。