
目录
- 前言
- 一、 Redis哨兵模式是啥?🤔
- 二、 为什么需要哨兵模式?🤷♀️
- 三、 哨兵模式的原理是什么?🤝
- 1. 监控(Monitoring)
- 2. 信息共享与客观下线判断
- 3. 哨兵领导者选举
- 4. 故障转移
- 5. 通知
- 四、 如何搭建(1主2从3哨兵)?
- 步骤 1:创建项目目录和文件
- 步骤 2:创建哨兵配置文件 (sentinel_conf/sentinel.conf)
- 步骤 3:创建 Docker Compose 配置文件 (docker-compose.yml)
- 步骤 4:启动集群
- 步骤 5:验证集群状态
- 步骤 6:模拟故障并观察自动切换 🔄
- 五、 哨兵模式的优缺点是什么?
🌟我的其他文章也讲解的比较有趣😁,如果喜欢博主的讲解方式,可以多多支持一下,感谢🤗!
🌟了解 缓存雪崩、穿透、击穿 请看 : 缓存雪崩、穿透、击穿:别让你的数据库“压力山大”!
其他优质专栏: 【🎇SpringBoot】【🎉多线程】【🎨Redis】【✨设计模式专栏(已完结)】…等
如果喜欢作者的讲解方式,可以点赞收藏加关注,你的支持就是我的动力
✨更多文章请看个人主页: 码熔burning
前言
大家好!👋 在上一篇关于 《Redis主从复制:告别单身Redis!》 的分享中,我们一起探索了Redis主从复制的奥秘。通过主从架构,我们实现了数据的备份 💾,并通过读写分离显著提升了Redis的读取性能 🚀,为我们的应用带来了诸多益处。
然而,正如月有阴晴圆缺,主从复制架构也并非完美无瑕。细心的小伙伴们可能已经意识到一个关键问题:如果被所有从节点依赖的主节点(Master)突然宕机了怎么办? 😱
在单纯的主从架构下,这无疑是一个“灾难性”的场景:
- 写操作完全中断 🛑:没有Master,新的数据无法写入。
- 数据一致性风险 🤔:如果宕机前有部分数据还没来得及同步到所有Slave…
- 需要人工干预 🧑💻:运维同学需要手动介入,从众多Slave中挑选一个“幸运儿”执行
SLAVEOF NO ONE,将其提升为新的Master,再让其他Slave指向这位新“老大”,最后还得通知所有应用程序:“嘿,换老板了,连接地址改一下!” 这个过程不仅 耗时 ⏳,容易 出错 ❌,更重要的是,在手动恢复完成之前,服务是 不可用 的!
对于需要高可用性、希望系统能尽可能“自愈”的关键业务来说,这种“手动挡”的故障恢复方式显然是难以接受的。我们渴望一种更智能、更自动化的机制来守护我们的Redis集群。
那么,有没有一种方法,能自动监控主节点的状态,并在它“倒下”时,自动推举出新的主节点,让整个切换过程尽可能平滑无感呢? 🤔
答案是肯定的! 这就是我们今天要深入探讨的主角—— Redis哨兵(Sentinel)模式 👮♂️✨。
哨兵模式,就像是为我们的Redis主从集群配备了一支 7x24小时在线的智能安保团队。它们时刻监控着集群的健康状况,一旦发现主节点失联,就能迅速、自动地完成故障发现、领导者选举、新主节点提升、从节点重定向以及通知客户端等一系列复杂操作,从而极大地提升了Redis集群的可用性,将单点故障的风险降到最低。
在本篇文章中,我们将:
- 深入理解哨兵模式的核心概念和它要解决的痛点 (Why Sentinel?)
- 揭秘哨兵模式自动化故障转移的工作原理 (How Sentinel Works?)
- 手把手带你使用 Docker 和 Docker Compose 在Linux上搭建一个一主二从三哨兵的典型架构 (Let’s Build It! 🛠️)
- 全面分析哨兵模式的优缺点 (Pros & Cons)
准备好了吗?让我们一起揭开Redis哨兵模式的神秘面纱,看看它是如何成为Redis高可用架构中不可或缺的一环吧!🚀
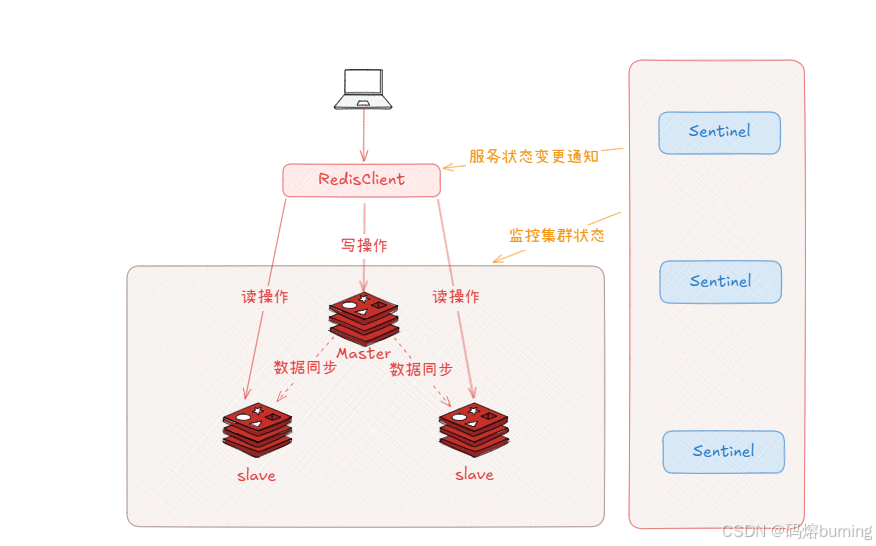
一、 Redis哨兵模式是啥?🤔
想象一下,你开了一个很火的店铺 🏪(这就是你的Redis主节点,Master),生意太好 🔥,一个人忙不过来,就找了几个学徒 🧑🎓(这就是Redis从节点,Slaves)。学徒跟着你学,你做啥他们也跟着做啥(数据复制 📜),这样客人来了,简单的活(读数据 📖)可以让学徒干,你就轻松多了(读写分离)。
但是,万一你这个主节点(老板 👨💼)突然生病请假 🤒 或者有事儿不在了(宕机 ❌),店就没人管了,学徒们也不知道谁该出来主持大局,生意就停摆了 🛑(服务不可用)。
哨兵模式(Sentinel) 就是为了解决这个问题而生的。它就像是你雇佣的一个或多个 特别靠谱的保安(哨兵) 👮♂️👮♀️。这些保安不干活(不存数据),他们的主要职责就是:
- 不停地盯着老板(Master)和学徒(Slaves) 👀,看他们是不是在正常工作 ✅。
- 互相通气 🗣️:保安之间会交流信息,确认老板是不是真的出事了,而不是某个保安眼花看错了 🤔。
- 紧急预案 🚨:一旦确认老板真的挂了,他们会按照预定规则(比如挑个最能干的学徒 💪)推举一个新的老板(Master) 出来主持大局。
- 通知大家 📢:选出新老板后,保安会 通知所有学徒:“以后跟他混!” 也会 通知所有客人(客户端):“现在新老板是这位,找他下单!”
- 老老板回来了咋办?:如果原来的老板回来了 🚶♂️,保安会告诉他:“现在店里有新老板了,你现在也变成学徒(Slave)吧。” (有点小委屈但为了店铺好嘛 😅)
总结: Redis哨兵模式是一套用于 监控 Redis主从集群、实现 自动故障转移(Failover 🛠️)和 通知 客户端新主节点地址的解决方案,核心目标是 提高Redis服务的可用性 ✨。
二、 为什么需要哨兵模式?🤷♀️
在只有主从复制(Master-Slave)的结构下:
- 优点:
- 数据备份: 从节点是主节点的热备份 💾。
- 读写分离: 主节点处理写操作和部分读操作,从节点处理大部分读操作,分担主节点压力,提高读取性能 🚀。
- 致命缺点:
- 单点故障(Single Point of Failure, SPOF): 主节点(Master)是整个系统的“命脉” ❤️🩹。一旦主节点宕机 ❌,写操作完全无法进行。虽然从节点有数据,但它们默认是只读的 🚫✍️,并且不会自动升级为新的主节点。
- 需要人工干预: 发现主节点宕机后,需要运维人员 🧑💻 手动选择一个从节点,执行
SLAVEOF NO ONE命令使其成为新的主节点,再让其他从节点指向这个新主节点,最后还要通知所有应用程序修改连接配置 🤯。这个过程耗时、易出错,期间服务是中断的。
哨兵模式就是来解决这个“单点故障”和“手动恢复”问题的。 它引入了自动化的监控和故障转移机制,当主节点失效时,能自动完成一系列复杂的操作,快速恢复服务 ✅,大大减少了停机时间,保证了系统的高可用性 ✨。
三、 哨兵模式的原理是什么?🤝
哨兵模式的核心原理可以拆解为几个关键动作:
1. 监控(Monitoring)
- 每个哨兵进程会 定期(通常每秒)向它监控的所有Redis实例(包括主节点和从节点)发送
PING命令 ,看对方是否正常响应PONG✅。 - 如果一个实例在配置的
down-after-milliseconds时间内没有有效回复 ⏳,这个哨兵就会 主观地 认为该实例 下线(Subjectively Down,简称 SDOWN) 🤔。这只是这个哨兵自己的判断,可能是网络抖动 🌐〰️ 或这个哨兵自身网络有问题。
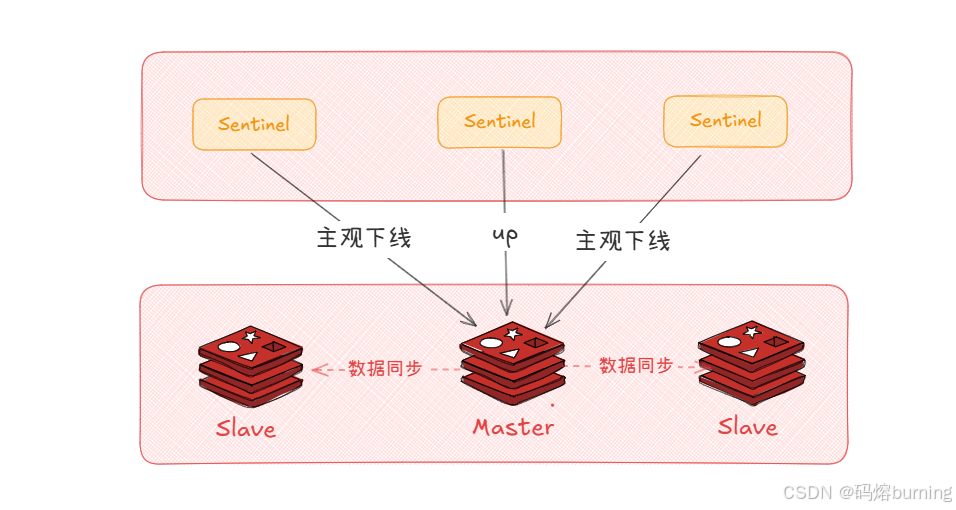
2. 信息共享与客观下线判断
- 哨兵们不仅监控Redis实例,它们之间也会互相发送
PING和订阅消息 📨,形成一个哨兵网络 🕸️。 - 当一个哨兵认为主节点 SDOWN 后,它会向其他哨兵发出
SENTINEL is-master-down-by-addr命令,询问它们的看法:“嘿,哥们儿,你觉得老板挂了吗?” 🗣️。 - 如果 足够数量(达到预设的 Quorum 值,即法定人数 🗳️)的其他哨兵也认为该主节点 SDOWN,那么这个主节点就被 客观地 标记为 下线(Objectively Down,简称 ODOWN) 🧑⚖️。这个判断是集群共识,更可靠 👍。Quorum 的值通常设置为哨兵总数的一半加一 (
N/2 + 1),防止网络分区导致的误判。
3. 哨兵领导者选举
- 一旦主节点被确认 ODOWN ❌,就需要一个哨兵来 负责执行 故障转移操作。不能所有哨兵都去操作,会乱套 🤪。
- 哨兵们会进行一次 领导者选举 👑。选举过程类似于 Raft 算法的一个简化版本:
- 发现 ODOWN 的哨兵会请求其他哨兵投票给自己成为领导者 🙋♂️。
- 每个哨兵在一个任期(epoch)内只能投一票 ☝️,并且会投给最先收到的请求。
- 获得超过半数(Quorum)选票的哨兵成为领导者(Leader)🎉。
- 如果没有选出领导者,会增加任期号,重新选举 🔄。
4. 故障转移
- 选出新主节点: 领导者哨兵 👑 会从所有状态正常的从节点中,按照一定的 优先级规则 🥇🥈🥉 挑选一个最合适的作为新的主节点:
- 优先级(
replica-priority): 配置值越小,优先级越高。 - 复制偏移量(Replication Offset): 选择复制数据最新的(偏移量最大 📈)。
- 运行ID(Run ID): 选择运行ID最小的(通常意味着启动时间最早 ⏱️)。
- 优先级(
- 执行切换:
- 领导者向选中的从节点发送
SLAVEOF NO ONE命令,使其升级为新的主节点 ✨👑。 - 领导者向其他所有从节点发送
SLAVEOF <new_master_ip> <new_master_port>命令,让它们指向新的主节点 👉👑。 - (如果旧主节点恢复 ✅)领导者也会向恢复的旧主节点发送
SLAVEOF <new_master_ip> <new_master_port>命令,使其降级为从节点 😅。
- 领导者向选中的从节点发送
- 更新配置: 哨兵会更新自身和其他哨兵关于
mymaster的配置信息 📝,记录新的主节点地址。
5. 通知
- 整个过程中(SDOWN、ODOWN、选举、切换等),哨兵会通过 Redis 的 发布/订阅(Pub/Sub) 功能发布各种事件消息 📢 (如
+sdown,+odown,+failover-start,+switch-master等)。 - 客户端可以订阅这些频道 👂,实时获取状态变化信息,特别是
+switch-master事件,客户端收到后就知道需要连接到新的主节点地址了 💡。很多 Redis 客户端库内置了对哨兵模式的支持,可以自动处理这个切换过程,非常方便 😊。
四、 如何搭建(1主2从3哨兵)?
假设你已经在Linux系统上安装好了 Docker 和 Docker Compose。
步骤 1:创建项目目录和文件
# 创建一个项目目录 📁
mkdir redis-sentinel-cluster
cd redis-sentinel-cluster# 创建用于存放哨兵配置文件的目录 📄
mkdir sentinel_conf
步骤 2:创建哨兵配置文件 (sentinel_conf/sentinel.conf)
# 哨兵监听的端口(每个哨兵实例在docker-compose中会映射到不同宿主机端口)
# port 26379 # 在compose中通过命令覆盖或让其动态发现,这里可以注释掉或保留默认# 监控名为 'mymaster' 的主节点,地址是 'redis-master' (docker内部服务名),端口 6379
# 最后的 '2' 是 quorum 值,表示至少需要2个哨兵同意,才能判定主节点 objectively down
sentinel monitor mymaster redis-master 6379 2# 主节点被判定为 SDOWN 的超时时间(毫秒)⏲️
sentinel down-after-milliseconds mymaster 5000# 故障转移的超时时间(毫秒),如果超过这个时间还没完成,认为失败 ⏳
sentinel failover-timeout mymaster 15000# 在执行故障转移时,最多可以有多少个从节点同时对新的主节点进行同步(1表示一次一个,更安全 👍)
sentinel parallel-syncs mymaster 1# (可选) 认证密码 🔑,如果你的Redis实例设置了密码
# sentinel auth-pass mymaster YourRedisPassword
重要 ❗️:
mymaster是你给这个主从集群起的名字,可以自定义,但所有哨兵配置和客户端连接时都要用这个名字。redis-master是后面docker-compose.yml文件中定义的 Redis主节点的服务名。Docker Compose内部网络会自动解析这个名字到对应容器的IP。quorum值设为2,因为我们有3个哨兵,3 / 2 + 1 = 2.5-> 需要2个哨兵同意。
步骤 3:创建 Docker Compose 配置文件 (docker-compose.yml)
services:redis-master: # 老板 👨💼image: redis:latest #选择最新的版本container_name: redis-mastercommand: redis-server --port 6379 # 可以省略,默认就是6379ports:- "6379:6379" # 映射主节点端口到宿主机networks:- redis-net# volumes: # 如果需要持久化数据 💾# - redis_master_data:/dataredis-slave-1: # 学徒 1 🧑🎓image: redis:latestcontainer_name: redis-slave-1command: redis-server --slaveof redis-master 6379 # 告诉他跟着谁混ports:- "6380:6379" # 映射从节点端口到宿主机不同端口depends_on:- redis-masternetworks:- redis-net# volumes:# - redis_slave1_data:/dataredis-slave-2: # 学徒 2 🧑🎓image: redis:latestcontainer_name: redis-slave-2command: redis-server --slaveof redis-master 6379 # 告诉他跟着谁混ports:- "6381:6379" # 映射从节点端口到宿主机不同端口depends_on:- redis-masternetworks:- redis-net# volumes:# - redis_slave2_data:/dataredis-sentinel-1: # 保安 1 👮♂️image: redis:latestcontainer_name: redis-sentinel-1# 增加启动延迟command: sh -c "sleep 15 && redis-sentinel /etc/redis/sentinel.conf --port 26379"volumes:- ./sentinel_conf/sentinel.conf:/etc/redis/sentinel.conf # 挂载配置文件 📄ports:- "26379:26379" # 映射哨兵端口depends_on: # 依赖所有 Redis 节点,确保它们先启动(虽然不完全保证启动完成😅)- redis-master- redis-slave-1- redis-slave-2networks:- redis-netredis-sentinel-2: # 保安 2 👮♀️image: redis:latestcontainer_name: redis-sentinel-2# 增加启动延迟command: sh -c "sleep 15 && redis-sentinel /etc/redis/sentinel.conf --port 26379" # 内部端口仍是26379,外部映射不同volumes:- ./sentinel_conf/sentinel.conf:/etc/redis/sentinel.confports:- "26380:26379" # 映射到宿主机 26380depends_on:- redis-master- redis-slave-1- redis-slave-2networks:- redis-netredis-sentinel-3: # 保安 3 👮♂️image: redis:latestcontainer_name: redis-sentinel-3# 增加启动延迟command: sh -c "sleep 15 && redis-sentinel /etc/redis/sentinel.conf --port 26379" # 内部端口仍是26379,外部映射不同volumes:- ./sentinel_conf/sentinel.conf:/etc/redis/sentinel.confports:- "26381:26379" # 映射到宿主机 26381depends_on:- redis-master- redis-slave-1- redis-slave-2networks:- redis-netnetworks:redis-net: # 定义一个网络 🌐,让所有容器可以互相通信driver: bridge # 使用默认的bridge驱动# volumes: # 如果需要持久化,需要定义volumes 💾
# redis_master_data:
# redis_slave1_data:
# redis_slave2_data:
注意:
- 我们为每个服务定义了
container_name,方便识别。 - 所有服务都连接到同一个自定义网络
redis-net,这样它们可以通过服务名(如redis-master)互相访问。 - 从节点通过
command: redis-server --slaveof redis-master 6379自动配置为主节点的从节点。 - 哨兵服务通过
command: redis-sentinel /etc/redis/sentinel.conf --port 26379启动。我们挂载了同一个sentinel.conf文件。重要的是,我们将每个哨兵容器的26379端口映射到了宿主机的不同端口(26379, 26380, 26381),以便从外部访问它们。 depends_on有助于控制启动顺序,但并不保证服务完全就绪。哨兵有重试机制,最终会连上 💪。- 如果需要数据持久化,需要取消注释
volumes部分。
步骤 4:启动集群
在 redis-sentinel-cluster 目录下,运行:
docker compose up -d

这会在后台启动所有容器 🚀。
步骤 5:验证集群状态
-
查看容器是否运行:
docker compose ps
应该能看到 1 个 master, 2 个 slave, 3 个 sentinel 都在运行 (Up) ✅。
-
连接到一个哨兵查看集群信息:
# 连接到第一个哨兵 (宿主机端口 26379) docker exec -it redis-sentinel-1 bash redis-cli -p 26379# 在 redis-cli 中执行哨兵命令: SENTINEL master mymaster # 查看 'mymaster' 的主节点信息 👨💼 SENTINEL slaves mymaster # 查看 'mymaster' 的从节点信息 🧑🎓🧑🎓 SENTINEL sentinels mymaster # 查看监控 'mymaster' 的其他哨兵信息 👮♂️👮♀️👮♂️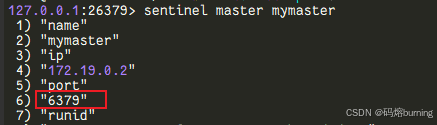
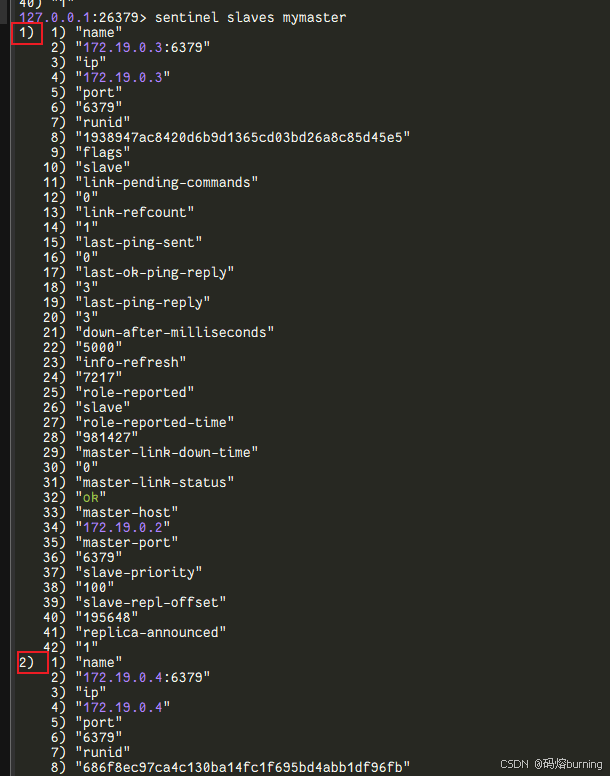
你应该能看到主节点是
redis-master:6379,有两个从节点,并且有3个哨兵。 -
测试主节点连接和数据同步:
# 连接主节点 (宿主机端口 6379) docker exec -it redis-master bash redis-cli #进入主节点客户端 set mykey hello 👋 # 写入数据 exit# 连接一个从节点 (例如宿主机端口 6380) docker exec -it redis-slave-1 bash redis-cli #进入从节点 1 客户端 get mykey # 读取数据,应该能读到 "hello" 👋 # 尝试写入数据 (应该会报错 🚫,因为从节点默认只读) set anotherkey world # (error) READONLY You can't write against a read only replica. exit
步骤 6:模拟故障并观察自动切换 🔄
-
停止主节点容器(模拟老板跑路 🏃♂️💨):
docker compose stop redis-master
-
观察哨兵日志(可选,但推荐 👀):
打开一个新的终端,实时查看其中一个哨兵的日志:docker compose logs -f redis-sentinel-1你会看到类似
+sdown master mymaster ...(觉得老板不对劲 🤔),然后是+odown master mymaster ...(确认老板真的挂了 ❌),接着是选举 (+vote-for-leader🗳️),最后是+switch-master mymaster ...(宣布新老板 🎉),显示新的主节点 IP 和端口(它会显示容器内部 IP,例如172.x.x.x)。
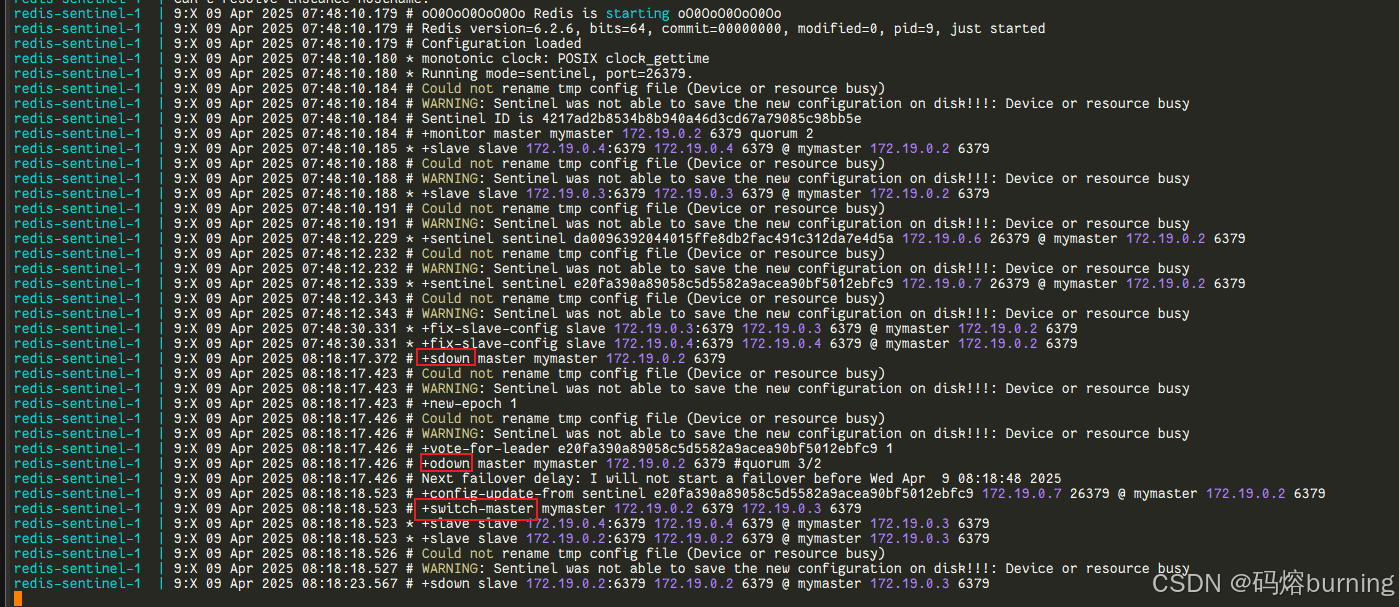
-
再次查询哨兵确认新主节点:
等待一小会儿(根据配置,通常几秒到十几秒 ⏳),再次连接哨兵:docker exec -it redis-sentinel-1 bash redis-cli -p 26379 SENTINEL master mymaster
你会发现
master的地址已经变成了之前某个从节点的地址(在Docker网络内的IP)。同时,num-slaves可能暂时减少,或者显示旧主节点处于下线状态。 -
测试新主节点:
找到新主节点的宿主机映射端口(比如之前是 6380 或 6381 的那个),连接并尝试写入:# 根据上面克制,外部端口 6380 对应的从节点被提升了 👑 docker exec -it redis-slave-1 bash #进入到6380对于的从节点 redis-cli set newkey world 🌍 # 应该可以成功写入 ✅ get mykey # 应该还能读到之前的数据 "hello" 👋 exit
-
恢复旧主节点(老板回来了 😊):
docker compose start redis-master
-
再次观察哨兵日志或查询哨兵:
你会看到哨兵发现了旧主节点的恢复 ✅,并将其配置为新主节点的从节点(现在是学徒了 😅)。docker exec -it redis-sentinel-1 bash redis-cli -p 26379 SENTINEL slaves mymaster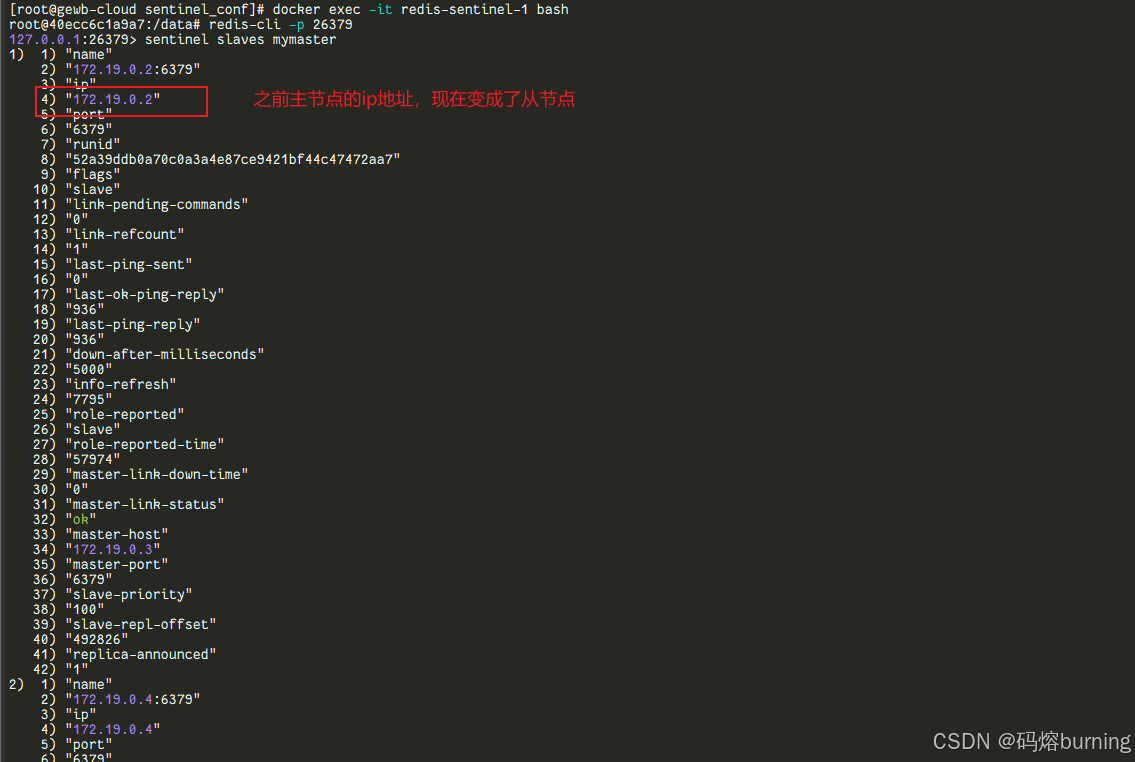
现在应该能看到原来的
redis-master容器作为从节点出现在列表里了。
五、 哨兵模式的优缺点是什么?
优点:
- 高可用性(High Availability)✨: 这是最核心的优点。主节点挂了能自动切换,服务中断时间大大缩短。就像有个备用老板随时待命!
- 自动故障转移(Automatic Failover)🤖: 无需人工干预 🧑💻❌,降低运维成本和出错风险。保安会自动处理紧急情况!
- 监控(Monitoring)👀: 不断检查主从节点状态,提供集群健康状况信息。时刻关注店铺运营!
- 通知(Notification)📢: 客户端或监控系统可以通过订阅哨兵消息,及时了解集群状态变化,自动更新连接。消息灵通!
- 配置提供者 🗺️: 客户端连接时可以先问哨兵:“老大(Master)是谁?”,哨兵会告知当前主节点的地址。像个问询处!
缺点:
- 配置相对复杂 🤔: 比单纯的主从复制多了一层哨兵的配置和管理。要多管理几个保安。
- 资源消耗 💸: 需要额外部署哨兵进程(至少3个以保证高可用),占用服务器资源(虽然哨兵本身资源消耗不大)。多雇几个人要多发点工资嘛。
- 故障转移有延迟 ⏳: 从发现主节点宕机到完成切换,整个过程需要时间(秒级),期间写服务是不可用的 🛑✍️。这个短暂的窗口期内可能会丢失少量写操作(取决于客户端重试策略和Redis持久化配置)。保安反应再快也需要一点点时间。
- 写能力没有扩展 📈❌: 任何时候都只有一个主节点处理写操作,哨兵模式不解决写性能瓶颈问题。店铺再大,能拍板下单的还是只有一个老板。如果需要扩展写能力,需要考虑 Redis Cluster。
- 判断主观下线(SDOWN)可能受网络影响 🌐❓: 单个哨兵的网络问题可能导致误判 SDOWN,但 ODOWN 判断机制(需要 Quorum)大大降低了误判的可能性 👍。
- 客户端需要支持哨兵 📱💡: 应用程序的客户端需要使用支持哨兵模式的库,或者通过代理来动态获取主节点地址。不能再傻傻地只认一个老板的地址了。
- 可能出现脑裂(Split-Brain)问题(理论上)🤯: 在极端复杂的网络分区情况下,如果 Quorum 设置不当,可能会导致两个独立的分区各自选出一个 Master。虽然哨兵机制设计上尽量避免这种情况,但理论风险存在。就像两个地方都以为自己是总部。